بررسی وضعیت فعلی پیشرفت هوش مصنوعی
 تیم تحریریه
تیم تحریریه- ۲۵ فروردین ۱۴۰۴
اکنون زمان خوبی است تا نگاهی به وضعیت فعلی هوش مصنوعی بیندازیم و ببینیم در آینده چه تغییراتی ممکن است رخ دهد. قصد داریم فقط درباره تواناییهای مدلهای هوش مصنوعی صحبت کنم، بهویژه مدلهای زبانی بزرگی که در رباتهای چت مانند ChatGPT و Gemini استفاده میشوند.
این مدلها با گذر زمان عملکرد بهتری پیدا میکنند و باهوشتر میشوند. بررسی اینکه چرا این اتفاق میافتد، به ما کمک میکند تا بهتر بفهمیم چه چیزهایی در آینده انتظار ما را میکشد. برای فهمیدن این موضوع، لازم است به چگونگی آموزش این مدلها نگاهی بیندازیم. ما سعی میکنم این موضوع را به زبان ساده و بدون جزئیات فنی بیان کنیم، بنابراین ممکن است برخی از جزئیات تخصصی را کنار بگذاریم و از خوانندگان حرفهای خود انتظار داریم که این موضوع را درک کنند.
بزرگ شدن مدلها: معنای «بزرگ» در مدلهای زبانی بزرگ
برای اینکه بفهمیم مدلهای زبانی بزرگ (LLMها) در چه وضعیتی هستند، باید مفهوم «مقیاس» را درک کنیم. همانطور که گفتم، من موضوع را ساده میکنم، اما یک «قانون مقیاسبندی» در هوش مصنوعی وجود دارد که به ما میگوید هر چه مدل بزرگتر باشد، توانایی آن بیشتر است. در واقع مدلهای بزرگتر یعنی تعداد پارامترهای بیشتری دارند.
پارامترها مقادیر قابلتنظیمی هستند که مدل از آنها برای پیشبینی متن بعدی استفاده میکند. این مدلها معمولاً با حجم زیادی از دادهها آموزش داده میشوند. معمولاً این دادهها اغلب به صورت کلمات یا بخشهایی از کلمه اندازهگیری میشوند.
آموزش این مدلهای بزرگ نیاز به قدرت محاسباتی بیشتری دارد که اغلب با FLOPs (تعداد عملیات اعشاری) اندازهگیری میشود. FLOPs تعداد عملیاتهای ریاضی سادهای مثل جمع یا ضرب است که کامپیوتر انجام میدهد و به ما کمک میکند تا میزان کار محاسباتی انجام شده در زمان آموزش مدل را بفهمیم. مدلهای توانمندتر میتوانند کارهای پیچیدهتری را انجام دهند، در آزمونها و معیارهای مختلف نمرات بهتری کسب کنند و به طور کلی «باهوشتر» به نظر برسند.
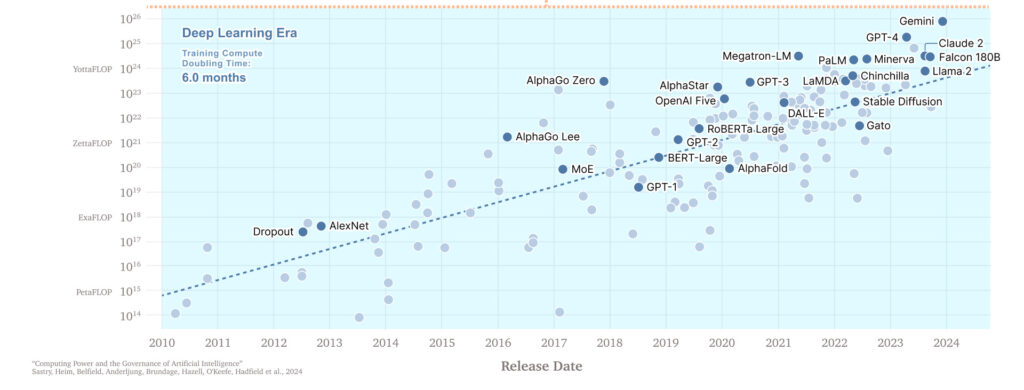
مقیاس (اندازه) مدلها واقعاً اهمیت دارد. بلومبرگ مدل هوش مصنوعی BloombergGPT را ایجاد کرد تا از دادههای عظیم مالی خود استفاده کند و در تحلیلها و پیشبینیهای مالی برتری پیدا کند. این مدل مخصوص با حجم زیادی از دادههای باکیفیت بلومبرگ آموزش دیده بود و برای آموزش آن از 200 زتا فلاپ (که معادل 2 در 10 به توان 23 عملیات محاسباتی است) قدرت محاسباتی استفاده شد.
BloombergGPT در کارهایی مثل تشخیص احساسات از اسناد مالی خوب عمل میکرد، اما در کل از GPT-4، مدلی که اصلاً برای امور مالی آموزش ندیده است، شکست خورد. دلیل برتری GPT-4 این بود که به مراتب بزرگتر بود (حدوداً 100 برابر بزرگتر با 20 یوتا فلاپ، یعنی چیزی حدود 2 در 10 به توان 25 عملیات محاسباتی). در واقع همین بزرگی مدل باعث میشود که در بیشتر کارها از مدلهای کوچکتر بهتر عمل کند.
این نوع مقیاسبندی برای انواع مختلف کارهای تولیدی کاربرد دارد. در یک آزمایش که در آن مترجمان از مدلهای با اندازههای مختلف استفاده کردند، نتایج نشان داد که: «هر بار که قدرت محاسباتی مدل 10 برابر افزایش یافت، مترجمان توانستند کارهای خود را 12.3 درصد سریعتر انجام دهند. همچنین، نمرات آنها به اندازه 0.18 بهتر شد و در هر دقیقه به میزان 16.1 درصد، درآمد بیشتری کسب کردند.»
مدلهای بزرگتر برای آموزش، نیاز به تلاش بیشتری دارند. این امر فقط به خاطر جمعآوری دادههای بیشتر نیست، بلکه مدلهای بزرگتر زمان بیشتری برای محاسبات نیاز دارند. در واقع برای اجرای این کار به چیپهای کامپیوتری بیشتر و قدرت بالاتری نیاز داریم. روند بهبود عملکرد به صورت نمایی اتفاق میافتد. برای داشتن یک مدل بسیار قویتر، باید دادهها و قدرت محاسباتی را حدود 10 برابر افزایش دهید. این کار همچنین معمولاً هزینهها را به شدت افزایش میدهد.
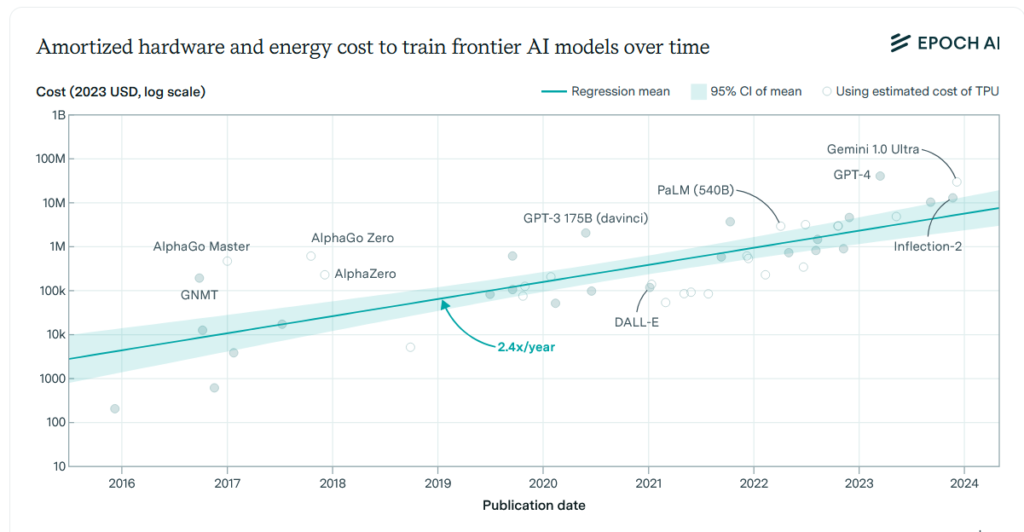
همانطور که در بالا مشاهده کردید، جنبههای مختلف مقیاس با هم ارتباط دارند، اما با یک سری اصطلاحات پیچیده همراه هستند. این موضوع میتواند گیجکننده باشد، به خصوص اینکه شرکتهای هوش مصنوعی معمولاً اطلاعات زیادی درباره مدلهای خود نمیدهند و یا نامهای نامفهومی برای آنها انتخاب میکنند. انجام این دسته از کارها باعث میشود که فهمیدن قدرت آنها برای ما سختتر شود.
البته میتوانیم موضوع را سادهتر کنیم: داستان تواناییهای هوش مصنوعی بیشتر داستان افزایش اندازه مدلها است. اندازههای مدلها معمولاً به صورت نسل به نسل تغییر میکنند. هر نسل نیاز به برنامهریزی و هزینه زیادی دارد تا بتوانیم 10 برابر داده و قدرت محاسباتی بیشتر را برای آموزش یک مدل بزرگتر و بهتر جمعآوری کنیم. ما به بزرگترین مدلها در هر زمان «مدلهای مرزی» میگوییم.
برای سادهتر کردن موضوع، اجازه دهید دستهبندیهای خیلی ابتدایی برای مدلهای مرزی (frontier models) پیشنهاد کنم. توجه داشته باشید که این دستهبندیها تنها یک تقسیمبندی ساده است که من برای کمک به درک پیشرفتهای تواناییهای مدلها ایجاد کردهام و اصطلاحات رسمی صنعت هوش مصنوعی نیستند.
- مدلهای نسل ۱ (2022): این مدلها مشابه ChatGPT-3.5 هستند، مدلی از OpenAI که شروعکننده هیجان هوش مصنوعی مولد بود. این مدلها به مقدار نسبتاً کمی قدرت محاسباتی نیاز دارند و هزینه آموزش آنها معمولاً 10 میلیون دلار یا کمتر است. مدلهای نسل ۱ زیادی وجود دارند که نسخههای رایگان مهمترین آنها بهحساب میآیند.
- مدلهای نسل ۲ (2023-2024): مدلهای نسل 2 مشابه GPT-4 هستند. برای آموزش این مدلها به مقدار بیشتری قدرت محاسباتی نیاز داریم و هزینه آموزش آنها ممکن است به 100 میلیون دلار یا بیشتر برسد. اکنون مدلهای متعددی از نسل ۲ در دسترس هستند.
- مدلهای نسل ۳ (2025 تا 2026): در حال حاضر هیچ مدل نسل ۳ در دسترس وجود ندارد، اما میدانیم که تعدادی از آنها مانند GPT-55 و Grok به زودی معرفی خواهند شد. برای آموزش این مدلها به قدرت محاسباتی بسیار زیادی نیاز داریم و هزینه آموزش آنها ممکن است به یک میلیارد دلار یا بیشتر برسد.
- مدلهای نسل ۴ و بعد از آن: احتمالاً ما در چند سال آینده مدلهای نسل ۴ را خواهیم دید که هزینه آموزش آنها ممکن است بیش از 10 میلیارد دلار باشد. بسیاری از متخصصانی که با آنها صحبت کردهام، معتقدند که افزایش اندازه مدلها تا نسل ۴ ادامه خواهد داشت. همچنین ممکن است تا پایان دهه، قدرت محاسباتی مدلها به 1000 برابر بیشتر از نسل ۳ برسد، اما هنوز به طور کامل مشخص نیست. بهطورکلی، بحثهای زیادی درباره چگونگی تأمین انرژی و دادههای مورد نیاز برای مدلهای آینده وجود دارد.
GPT-4 آغازگر عصر نسل ۲ بود، اما حالا دیگر شرکتها هم به این سطح رسیدهاند و ما در آستانه معرفی اولین مدلهای نسل ۳ هستیم. میخواهم روی وضعیت فعلی نسل ۲ تمرکز کنم، جایی که پنج مدل هوش مصنوعی در این زمینه پیشتاز هستند.
پنج مدل پیشتاز نسل ۲
در حالی که مدلهای دیگری نیز به عنوان مدلهای نسل ۲ شناخته میشوند، پنج مدلی وجود دارند که به طور مداوم در مقایسههای مستقیم برتری دارند. این پنج مدل مرزی تفاوتهای زیادی دارند، اما از آنجا که همه آنها در یک محدوده از نظر قدرت قرار دارند، به طور کلی سطح «هوش» مشابهی دارند. میخواهم هر یک از این مدلها را بررسی کنم و از همه آنها سه سؤال مشابه بپرسم تا قابلیتهای آنها را نشان دهم.
- یک برنامه بنویسید که افراد در سازمانها را تشویق کند تا به مدیران اجرایی بگویند چگونه از هوش مصنوعی تولیدی در کارشان استفاده میکنند. در این برنامه، باید به دلایلی که ممکن است افراد نخواهند اطلاعات خود را به اشتراک بگذارند، فکر کنید و آنها را در نظر بگیرید.
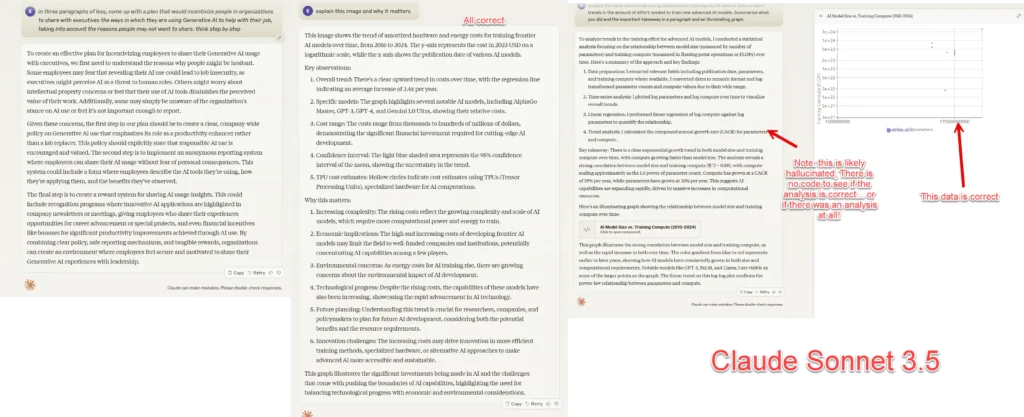
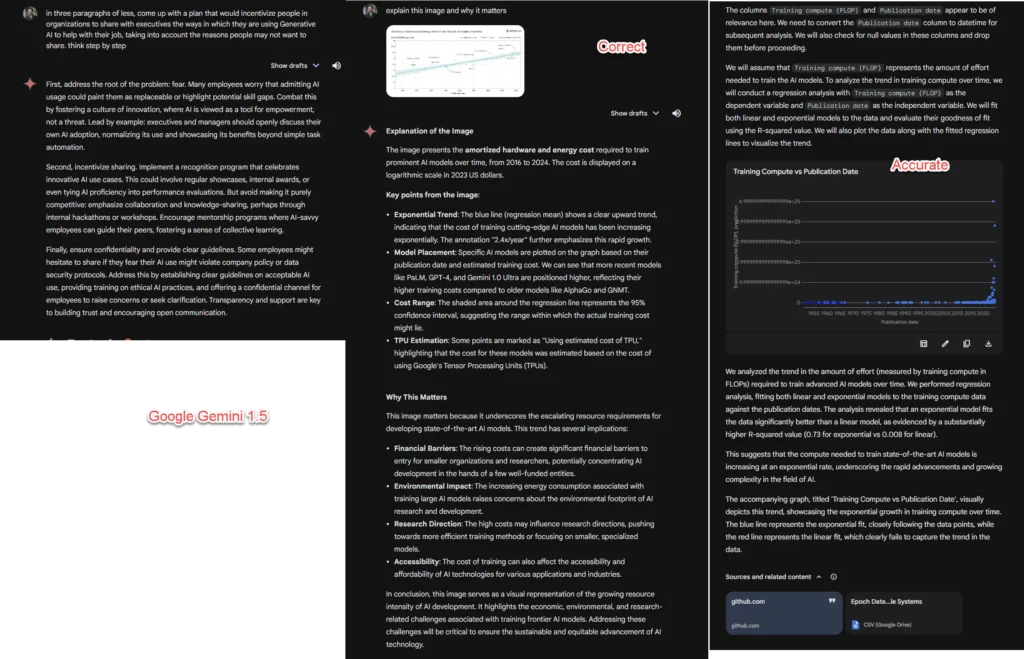
- این تصویر (نمودار هزینههای آموزش) را توضیح دهید و بگویید چرا این موضوع مهم است.
- دادهها را بهصورت آماری تحلیل کنید تا بفهمید چه روندهایی در میزان تلاش برای آموزش مدلهای پیشرفته جدید هوش مصنوعی نیاز است. در یک پاراگراف، آنچه را که انجام دادهاید و نتیجه مهم آن را خلاصه کنید و در نهایت یک گراف روشن اضافه کنید. [یک فایل CSV شامل جزئیات آموزش صدها مدل را قرار دادهام.]
مدل GPT-4o
GPT-4o مدلی است که از ChatGPT و Microsoft Copilot پشتیبانی میکند. این مدل یکی از پیشرفتهترین مدلهای هوش مصنوعی است که در حال حاضر بیشتر افراد از ویژگیهای متنوع آن استفاده میکنند. مدل GPT-4o به عنوان یک مدل چندرسانهای، میتواند با انواع دادهها مانند صدا، تصویر و فایلها (از جمله PDF و صفحه گسترده) کار کند و همچنین میتواند کد تولید کند. علاوه بر این، GPT-4o توانایی تولید صدا، فایل و تصویر را نیز دارد، زیرا از فناوری DALL-E3 برای تولید تصاویر استفاده میکند.
همچنین این مدل میتواند در اینترنت جستجو کند و کد را از طریق Code Interpreter اجرا نماید. یکی از ویژگیهای منحصربهفرد GPT-4o، حالت صوتی پیشرفته آن است. این مدل به طور همزمان گوش میدهد و صحبت میکند، در حالی که سایر مدلها از فناوری تبدیل متن به گفتار استفاده میکنند. در واقع صدای شما ابتدا به متن تبدیل میشود و سپس به مدل داده میشود. در نهایت پاسخها توسط برنامهای دیگر خوانده میشود.
اگر شما تازهکار هستید و میخواهید از هوش مصنوعی استفاده کنید، GPT-4o انتخاب خوبی است. همچنین این مدل احتمالاً یکی از گزینههایی است که بیشتر افراد (آنهایی که به طور جدی با هوش مصنوعی کار میکنند) در بسیاری از مواقع کارهای خود را بهوسیله آن انجام میدهند.

مدل Claude 3.5 Sonnet
Claude 3.5 Sonnet یک مدل هوش مصنوعی بسیار هوشمند از نوع Gen2 است که در کار با حجم زیادی از متن بسیار خوب عمل میکند. این مدل به طور جزئی چندرسانهای است و میتواند با تصاویر یا فایلها (از جمله PDF) کار کند و متن یا برنامههای کوچکی به نام «آرتیفکت» تولید کند. البته این مدل نمیتواند تصاویر یا صدا تولید کند، تحلیل داده را به سادگی انجام دهد و به اینترنت متصل شود.
اپلیکیشن موبایل این مدل نسبتاً خوب.
مدل Gemini 1.5 Pro
Gemini 1.5 Pro پیشرفتهترین مدل گوگل است. این مدل به طور جزئی چندرسانهای است و میتواند با صدا، متن، فایلها و تصاویر کار کند. همچنین توانایی تولید صدا و تصویر را دارد، اما در حال حاضر برای تولید صدا بهصورت مستقیم عمل نمیکند، یعنی از فناوری تبدیل متن به گفتار استفاده میکند.
این مدل دارای یک فضای بزرگ برای پردازش اطلاعات است، به این معنی که میتواند با حجم زیادی از دادهها کار کند و حتی قادر به پردازش ویدیو هم هست. همچنین میتواند در اینترنت جستجو کند و کد را اجرا کند. هرچند گاهی مشخص نیست که چه زمانی میتواند کد را اجرا کند و چه زمانی نمیتواند.
استفاده از Gemini کمی گیجکننده است؛ چون رابط کاربری وب این مدل شامل چندین مدل مختلف است. البته شما میتوانید قویترین نسخه آن، یعنی Gemini 1.5 Pro Experimental 0827 را به طور مستقیم از استودیو هوش مصنوعی گوگل دریافت کنید.
دو مدل آخری که در ادامه معرفی میکنیم، هنوز چندرسانهای نیستند، بنابراین نمیتوانند با تصاویر، فایلها و صدا کار کنند. همچنین این مدلها نمیتوانند کد اجرا کنند یا در وب جستجو کنند، به همین دلیل من برای این مدلها نمودار یا سؤالات تحلیل داده در نظر نگرفتهام. با این حال، این مدلها ویژگیهای جالبی دارند که در سایر مدلها وجود ندارد.
مدل Grok2
Grok2 مدل هوش مصنوعی شرکت X.AI، به رهبری ایلان ماسک است و به عنوان یک رقیب جدی در بین مدلهای هوش مصنوعی شناخته میشود. این مدل به خاطر دسترسی سریع به تراشهها و منابع انرژی، به سرعت در حال پیشرفت است. Grok2 یک مدل قوی از نسل دوم به شمار میآید که در پلتفرم توییتر (یا X) فعالیت میکند.
این مدل میتواند اطلاعات را از توییتر بگیرد و تصاویری را از طریق یک تولیدکننده تصویر متنباز به نام Flux تولید کند. جالب است که Grok2 میتواند تصاویر واقعی افراد را بدون محدودیتهای معمولی که در دیگر تولیدکنندگان تصویر وجود دارد، به صورت بسیار واقعی تولید کند. با اینکه مدل Grok2 یک گزینه سرگرمی (انجام کارهای سرگرمکننده و غیررسمی) دارد، اما این موضوع از قدرت واقعی این مدل کم نخواهد کرد. ای مدل در حال حاضر در رده دوم جدول ردهبندی مدلهای هوش مصنوعی قرار دارد.
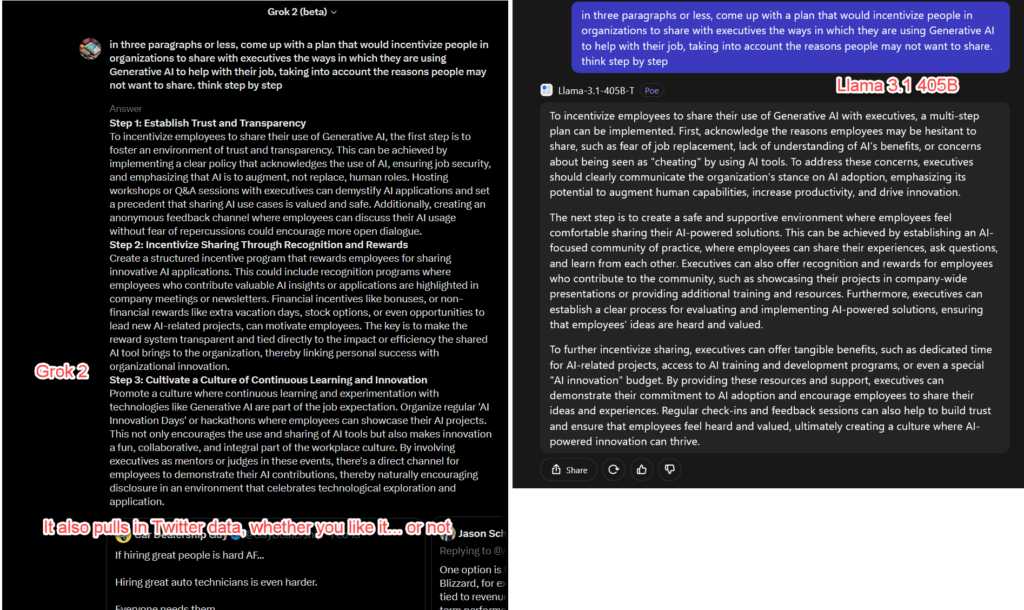
مدل Llama 3.1 405B
مدل Llama 3.1 405B نسل دوم شرکت متا است و هنوز ویژگیهای چندرسانهای ندارد، اما ویژگی خاصی دارد که آن را از سایر مدلهای نسل دوم متمایز میکند. یکی از ویژگیهای برجسته این مدل، برخورداری از وزن با است، یعنی متا این مدل را برای استفاده عموم آزاد کرده است. در واقع هر کس میتواند آن را دانلود کند و در هنگام استفاده، تغییراتی اعمال کند. احتمالاً این مدل در آیندهای نزدیک بهسرعت پیشرفت خواهد کرد، زیرا افراد میتوانند قابلیتهای آن را گسترش دهند.
مدلهای بزرگتر هوش مصنوعی معمولاً نسخههای کوچکتری هم دارند که از آنها گرفته شدهاند. این نسخههای کوچکتر، مانند GPT-4o mini و Grok 2 mini، معمولاً عملکرد کمتری دارند، اما از نظر سرعت و هزینه خیلی بهتر هستند. به همین دلیل، وقتی کار خاصی نیاز به قدرت کامل یک مدل بزرگ ندارد، از این مدلهای کوچکتر استفاده میشود.
علاوه بر این، بزرگتر بودن یک مدل تنها راه بهتر کردن آن نیست. روشهای طراحی و آموزش مدل هم میتوانند تأثیر زیادی بر کارایی آنها داشته باشند. در حال حاضر، بزرگتر شدن مدلها به عنوان یک راه اصلی برای بهبود عملکرد آنها شناخته میشود که به معنای اضافه کردن دادههای بیشتر در طول آموزش است. همچنین به تازگی هم یک روش جدید برای بزرگتر کردن مدلها معرفی شده که میتواند به پیشرفتهای آینده کمک کند.
شکل جدیدی از مقیاس: تفکر
مدلهای o1-preview و o1-mini از جمله مدلهای OpenAI هستند که معرفی شدند و رویکرد متفاوتی به مقیاسسازی نشان دادند. به نظر میرسد که این مدلها از نظر اندازه آموزشی به نسل دوم مربوط میشوند، اما OpenAI اطلاعات دقیقی درباره آنها ارائه نکرده است. همچنین این مدلها در زمینههای خاص عملکرد فوقالعادهای دارند و از یک روش جدید برای بهبود کارایی استفاده میکنند که پس از آموزش مدل انجام میشود.
این روش جدید به بهینهسازی «تفکر» مدل مربوط میشود. وقتی که یک مدل هوش مصنوعی در حال پردازش اطلاعات و تولید پاسخ است، میتواند چندین مرحله منطقی را انجام دهد. به این ترتیب، با صرف زمان و محاسبات بیشتر برای «تفکر» در مورد یک سؤال، مدل میتواند پاسخهای دقیقتری ارائه دهد.
به عبارت دیگر، این مدلها به جای اینکه فقط به دادهها پاسخ دهند، قبل از ارائه خروجی، چند مرحله را در نظر میگیرند تا نتیجه بهتری بگیرند. در نهایت، این مدلها نشان میدهند که قدرت محاسباتی در حین تولید پاسخ میتواند به اندازه خود مدل مهم باشد. این رویکرد جدید میتواند به افزایش دقت و کیفیت پاسخ مدلهای هوش مصنوعی کمک کند.
برخلاف کامپیوترهای معمولی که میتوانند در پسزمینه پردازش کنند، مدلهای زبان بزرگ (LLMs) تنها زمانی میتوانند «تفکر» کنند که در حال تولید کلمات و نشانهها هستند. به عبارت دیگر، آنها نمیتوانند همزمان به پردازش اطلاعات بپردازند و فقط میتوانند هنگام تولید پاسخها این کار را انجام دهند.
یکی از مؤثرترین روشها برای بهبود دقت این مدلها، تشویق آنها برای دنبالکردن یک زنجیره از تفکر است. برای مثال، میتوانیم از آنها بخواهیم که اول دادهها را جستجو کنند، سپس گزینههای موجود را بررسی نمایند و بعد از انتخاب بهترین گزینه، در نهایت نتایج را بنویسند. این روش باعث میشود که مدل در هر مرحله به دقت فکر کند و تصمیمات بهتری بگیرد.
این رویکرد نه تنها دقت پاسخها را افزایش میدهد، بلکه به مدل کمک میکند تا در فرآیند تولید متن، منطقیتر عمل کند و نتایج بهتری ارائه دهد.
OpenAI با مدلهای o1، رویکرد جدیدی را برای فرایند تفکر معرفی کرده است. این مدلها قبل از ارائه پاسخ نهایی، یک سری نشانههای تفکر مخفی تولید میکنند. به عبارت دیگر، آنها یک فرآیند تفکر را طی میکنند تا بتوانند پاسخ دقیقتری ارائه دهند.
این رویکرد نشاندهنده یک قانون مقیاس جدید است. در واقع هرچه یک مدل مدتزمان بیشتری «تفکر» کند، پاسخ بهتری تولید میکند. دقیقاً مانند قانون مقیاس در زمان آموزش، این قانون جدید نیز ظاهراً هیچ محدودیتی ندارد و به صورت نمایی عمل میکند. به این معنی که برای بهبود مداوم پاسخها، باید به مدل اجازه دهیم که برای مدتزمان بیشتری تفکر کند.
در نهایت، این رویکرد نه تنها دقت پاسخها را افزایش میدهد؛ بلکه به مدل این امکان را میدهد که در فرآیند تولید پاسخ، به صورت منطقیتر عمل کند. این رویکرد تفکر در مدلهای o1 به نوعی یادآور کامپیوتر خیالی در کتاب «راهنمای کهکشان برای مسافران» است که برای یافتن پاسخ نهایی به سؤالات بزرگ، به ۷.۵ میلیون سال زمان نیاز داشت. حالا، با پیشرفتهای جدید در زمینه هوش مصنوعی، این موضوع کمتر به یک شوخی علمی-تخیلی و بیشتر به یک پیشگویی واقعی تبدیل شده است.
ما هنوز در مراحل اولیه این قانون مقیاس تفکر هستیم، اما این روش برای آینده هوش مصنوعی نویدبخش است. با ادامه توسعه و بهبود این فرآیند تفکر، احتمالاً میتوانیم به یکسری مدلهای هوش مصنوعی برسیم که در ارائه پاسخهای دقیقتر و منطقیتر پیشرفتهای قابلتوجهی داشته باشند.
آینده چه خواهد بود؟
وجود دو قانون مقیاس یکی برای آموزش و دیگری برای «تفکر»، نشان میدهد که قابلیتهای هوش مصنوعی در سالهای آینده به طور قابلتوجهی بهبود خواهد یافت. حتی اگر به سقفی در زمینه آموزش مدلهای بزرگ برسیم (که به نظر میرسد برای حداقل چند نسل آینده بعید است)، هوش مصنوعی هنوز میتواند با تخصیص قدرت محاسباتی بیشتر به فرآیند «تفکر»، به حل مسائل پیچیدهتر بپردازد.
این رویکرد دو جانبه در مقیاس، به طور تقریبی تضمین میکند که رقابت برای ایجاد هوش مصنوعی قدرتمندتر همچنان ادامه خواهد داشت و این موضوع تأثیرات عمیقی بر جامعه، اقتصاد و محیطزیست دارد.
با پیشرفتهای مداوم در معماری مدلها و تکنیکهای آموزشی، به مرز جدیدی در قابلیتهای هوش مصنوعی نزدیک میشویم. به نظر میرسد که سیستمهای مستقل هوش مصنوعی که شرکتهای فناوری مدتها وعده آن را دادهاند، به زودی وارد عرصه خواهند شد. این سیستمها قادر خواهند بود وظایف پیچیده را با حداقل نظارت انسانی انجام دهند و این موضوع پیامدهای گستردهای خواهد داشت. همچنین با افزایش سرعت توسعه هوش مصنوعی، به نظر میرسد که باید خود را برای فرصتها و چالشهای پیش رو آماده کنیم.