راه حل کمبود داده در یادگیری ماشین
 تیم تحریریه
تیم تحریریه- ۱۱ مرداد ۱۴۰۱
کمبود داده در یادگیری ماشین به اندازه کافی علیرغم برخورداری از ایدههای فوقالعاده هوش مصنوعی در کسبوکار، موجب نگرانی شرکتها شده است. اما راه حلهایی هم برای این مساله وجود دارد.
“الکساندر گلفالونیِری“
هدف مقاله حاضر این است که خواننده را با برخی از این راهحلها آشنا کند، اما ارائه همه راهحلهای موجود در دستور کار این مقاله نیست. مسئلۀ کمبود داده در یادگیری ماشین اهمیت زیادی دارد، زیرا دادهها نقشی حیاتی در پروژههای هوش مصنوعی ایفا میکنند. بنابراین عملکرد ضعیف در پروژههای یادگیری ماشین را میتوان به اندازه مجموعهداده Dataset نسبت داد؛ چرا که در اغلب موارد، مسائل مرتبط با کمبود داده در یادگیری ماشین، دلیلِ اصلیِ عدم اجرای پروژههای بزرگ هوش مصنوعی هستند.
محققان در بعضی از پروژهها به این نتیجه میرسند که هیچ داده مرتبطی وجود ندارد یا فرایند گردآوری داده دشوار و زمانبر است. مدلهای یادگیری بانظارت (Supervised) با موفقیت برای پاسخگویی به طیف وسیعی از چالشهای کسبوکار استفاده میشوند. با این حال، این مدلها به شدت نیازمند داده هستند و اندازه دادههای آموزشی اهمیت زیادی دارد.
در اغلب موارد، ساخت مجموعهدادههایی که به قدر کافی بزرگ باشند، کار سختی است. از مشکلات دیگر این است که تحلیلگران پروژه، معمولاً میزان دادههای لازم برای مدیریت مسائل رایج در کسبوکار را دست کم میگیرند. من هم در جمعآوری مجموعهدادههای آموزشی بزرگ به مشکل خوردهام. وقتی برای شرکت بزرگی کار میکنید، گردآوری داده پیچیدهتر میشود.
چه میزان داده نیاز داریم؟
خب، حدود 10 برابر بیشتر از درجه آزادی در مدل، به نمونه نیاز است. هرقدر مدل پیچیدهتر باشد، بیشتر در معرض بیشبرازش قرار میگیرید؛ اما با اعتبارسنجی میتوان از این مورد اجتناب کرد. با این وجود، بسته به موردِ استفاده میتوان از دادههای خیلی کمی هم استفاده کرد.
بیشبرازش Overfitting
مدلی است که دادههای آموزشی را خیلی خوب مدلسازی میکند. این مسئله زمانی اتفاق می افتد که یک مدل جزئیات ونویزهای موجود در دادههای آموزشی را یاد میگیرد و این مسئله تاثیر منفی بر عملکرد مدل روی دادههای جدید دارد.
اما مدیریت مقادیر گمشده به چه معناست؟ اگر تعداد مقادیر گمشده در دادهها زیاد باشد (بالای 5 درصد)، مدیریت مقادیر گمشده missing value به معیارهای موفقیت خاصی نیاز خواهد داشت. به علاوه، این معیارها در مجموعهداده های مختلف و حتی در کاربردهای مختلف از قبیل تشخیص، تقطیع، پیشبینی، طبقهبندی و… نقش متفاوتی ایفا میکنند.
باید به این نکته توجه داشت که هیچ راهکار بینقصی برای مقابله با دادههای گمشده یا ناموجود وجود ندارد. راهحلهای مختلفی وجود دارند اما نوع مسئله حائز اهمیت است (تحلیل سری زمانی، یادگیری ماشین، رگرسیون و…).
نکته مهم درباره روشهای پیشبینیکننده این است که این روشها زمانی استفاده میشوند که مقادیر گمشده با سایر مقادیر معلوم ارتباط دارند. در کل، میتوان از الگوریتمهای مختلف یادگیری ماشین برای مشخص کردن دادههای گمشده استفاده کرد.
این کار با تبدیل ویژگیهای گمشده به برچسب انجام میشود به طوری که از ستونهای بدون مقدار گمشده جهت پیشبینیِ ستونهای دارایِ مقادیر گمشده استفاده میشود. بر اساس تجربه، اگر تصمیم دارید راهحلی مبتنی بر هوش مصنوعی ارائه دهید، احتمال دارد در جایی با کمبود داده یا دادههای گمشده مواجه شوید. اما خوشبختانه، راهحلهایی برای تبدیل این محدودیت کمبود داده در یادگیری ماشین به فرصت وجود دارد.
[irp posts=”24654″]کمبود داده در یادگیری ماشین
همانطور که در بالا اشاره شد، تخمینِ میزان حداقلیِ دادههای لازم برای یک پروژه هوش مصنوعی غیرممکن است. واضح است که ماهیت پروژه، تاثیر شگرفی بر میزان دادههایی که نیاز دارید خواهد گذاشت. برای مثال، متون، تصاویر و فیلمها معمولاً به داده بیشتری نیاز دارند. با این حال، باید چندین عامل دیگر را نیز برای تخمین دقیق در نظر گرفت.
تعداد دسته ها
خروجی مورد انتظارتان از مدل چیست؟ اساساً، هرقدر تعداد دستهها کمتر باشد، نتیجه بهتر است.
عملکرد مدل
شاید دیتاست کوچک در اثبات مفهوم به قدر کافی خوب باشد، اما در تولید به دادههای بیشتری نیاز است.
در کل، دیتاستهای کوچک مستلزم مدلهایی هستند که پیچیدگی کمتری دارند تا از بیشبرازش اجتناب شود.
راهحلهای غیرفنی
پیش از اینکه راهحلهای فنی را بررسی کنیم، بیایید ببینیم از چه راهکارهایی میتوان برای ارتقای دیتاست و رفع کمبود داده استفاده کرد. شاید نیازی به گفتن نباشد اما قبل از اینکه کار هوش مصنوعی را آغاز کنید، سعی کنید با توسعه ابزارهای درونی، بیرونی و روشهای گردآوری داده، تا آنجا که میتوانید داده جمع کنید. اگر میدانید انجام چه کارهایی از الگوریتم یادگیری ماشین انتظار میرود، میتوانید به ساخت یک سازوکار گردآوری داده بپردازید.
سعی کنید فرهنگ استفاده از داده واقعی را در سازمان رواج دهید
برای آغاز فرایند اجرای یادگیری ماشین، باید از دادههای منبع باز استفاده کنیم. دادههای فراوانی برای یادگیری ماشین وجود دارند که برخی از شرکتها برای قرار دادن آنها در دسترس دیگران اعلام آمادگی کردهاند. اگر به دادههای بیرونی در پروژهتان احتیاج دارید، شاید بهتر باشد به همکاری با سایر سازمانها بپردازید تا دادههای مورد نیاز خود را به دست آورید. بیتردید شراکت با سایر سازمانها هزینههایی را به همراه خواهد داشت، اما دریافت دادههای اختصاصی یک مانع طبیعی برای رقبا ایجاد میکند.
یک نرمافزار مفید بسازید، آن را منتشر و از دادهها استفاده کنید
یکی دیگر از روشهایی که استفاده کردیم، دادنِ دسترسی به کاربران برای استفاده از یک نرمافزار ابری بود. دادههایی که در ساخت نرمافزار به کار برده میشود، میتواند برای ایجاد مدلهای یادگیری ماشین نیز استفاده شود. یکی از همکاران ما چندی پیش یک نرمافزار برای بیمارستانها ساخت و آن را در دسترس همه قرار داد. ما به لطف آن نرمافزار، دادههای زیادی را جمعآوری کردیم و توانستیم دیتاست منحصربهفردی برای راهحل یادگیری ماشینمان ایجاد کنیم.
وقتی مشتریان یا سرمایهگذاران متوجه شوند که خودتان مجموعهدادۀ منحصربهفردی را درست کردهاید، با دید دیگری به شما نگاه میکنند و این خیلی خوب است.

مجموعهدادههای کوچک
برخی از رایجترین روشهایی که میتوان از آنها برای ساخت مدلهای پیشبینیکننده با مجموعهدادههای کوچک استفاده کرد، به شرح زیر است. در کل، هرقدر الگوریتم یادگیری ماشین سادهتر باشد، از مجموعهدادههای کوچک به شیوه بهتری یاد میگیرد. از دید یادگیری ماشین، دادههای کوچک به مدلهایی با پیچیدگی کمتر نیاز دارند تا از بیشبرازش دوری شود. الگوریتم «Naïve Bayes» از جمله سادهترین طبقهبندیکنندهها به شمار میرود و قابلیت این را دارد تا از مجموعهدادههای نسبتاً کوچک به خوبی یاد بگیرد.
در کل، هرقدر الگوریتم یادگیری ماشین سادهتر باشد، از مجموعهدادههای کوچک به شیوه بهتری یاد میگیرد. از دید یادگیری ماشین، دادههای کوچک به مدلهایی با پیچیدگی کمتر نیاز دارند تا از بیشبرازش دوری شود. الگوریتم «Naïve Bayes» از جمله سادهترین طبقهبندیکنندهها به شمار میرود و قابلیت این را دارد تا از مجموعهدادههای نسبتاً کوچک به خوبی یاد بگیرد.
روشهای «Naïve Bayes»: مجموعهای از الگوریتمهای یادگیریِ بانظارت، بر پایه استفاده از قضیه بیزی Bayes’ theorem با فرضِ ساده ابتداییاستقلال شرطی naive) conditional independence) میان هر جفت از ویژگی ها به شرط دانستن مقدار متغیر کلاس.
امکان استفاده از سایر مدلهای خطی و درختهای تصمیم وجود دارد. این مدلها میتوانند در مجموعهدادههای کوچک عملکرد نسبتاً خوبی از خود بر جای بگذارند. اساساً، مدلهای ساده قادرند بهتر از مدلهای پیچیدهتر (شبکههای عصبی) از مجموعهدادههای کوچک یاد بگیرند، زیرا دنبال یادگیری کمتری هستند.
روشهای بیزی در مجموعهدادههای کوچک بهترین عملکرد را دارند، هرچند که عملکرد آن به چگونگی انتخاب فرض پیشین بستگی داد. از دید ما، «Naïve Bayes» و رگرسیون ستیغی Ridge Regression بهترین مدلهای پیشبینی هستند. در مجموعهدادههای کوچک، به مدلهایی نیاز داریم که پارامترهای کمتری دارند (پیچیدگی کمتر). البته بسته به ماهیت مسائل کسبوکار و اندازه مجموعهداده، چندین راهحل دیگر هم وجود دارد.
در مجموعهدادههای کوچک، به مدلهایی نیاز داریم که پارامترهای کمتری دارند (پیچیدگی کمتر). البته بسته به ماهیت مسائل کسبوکار و اندازه مجموعهداده، چندین راهحل دیگر هم وجود دارد.
یادگیری انتقال Transfer learning
چارچوبی است که از مدلها یا دادههای مرتبطی که وجود دارند استفاده میکند و در عین حال به ساختِ یک مدل یادگیری ماشین میپردازد. یادگیری انتقال از دانش حاصل از کاری که پیشتر یاد گرفته شده استفاده میکند تا عملکرد سیستم را بهبود بخشد.
بنابراین، کاهش میزان دادههای آموزشیِ لازم را در دستور کار خود قرار میدهد. روشهای یادگیری انتقال خیلی مفید هستند زیرا این فرصت را در اختیار مدلها میگذارند تا با استفاده از دانشِ حاصل از مجموعهداده دیگر یا مدلهای یادگیری ماشینیِ موجود پیشبینی کنند. روشهای یادگیری انتقال باید زمانی مد نظر قرار گیرند که دادههای آموزشیِ هدفِ کافی در اختیار نداشته باشیم و قلمروهای هدف و مبدأ میان مدل موجود و مدل مطلوب به یکدیگر شباهت دارند، اما کاملاً یکسان نیستند.
[irp posts=”12844″]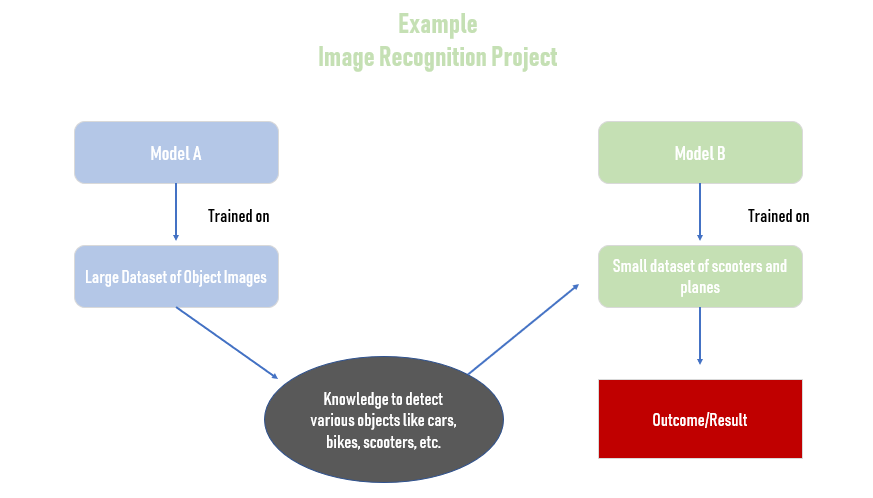
انباشتن سادهلوحانۀ مدلها یا مجموعهدادههای مختلف همیشه کارساز نیست! اگر مجموعهدادههای موجود تفاوت زیادی با دادههای هدف داشته باشند، در این صورت مدلها یا دادههای موجود، بر یادگیرندۀ جدید تاثیر منفی میگذارند.
یادگیری انتقال زمانی به خوبی عمل میکند که بتوانید از مجموعهدادههای دیگر برای استنتاجِ دانش استفاده کنید، اما اگر هیچ دادهای نداشته باشید چه اتفاقی میافتد؟
نقش مهم تولید داده
اینجاست که تولید داده میتواند نقش مهمی ایفا کند و مشکل کمبود داده به چشم میآید. این روش در صورت نبودِ داده یا زمانی که دادههای بیشتری تولید میکنید، استفاده میشود. در این مورد، دادههای کمی که وجود دارند، اصلاح میشوند تا زمینه برای آموزش داده فراهم شود.
برای مثال، میتوان با کراپ کردن یک عکس از خودرو چندین عکس از آن ایجاد کرد. متاسفانه، نبودِ دادههای برچسبدارِ باکیفیت، یکی از بزرگترین چالشهایی است که متخصصان داده با آن مواجه هستند، اما استفاده از روشهایی مثل یادگیری انتقال و تولید داده، میتواند مشکلِ کمبود داده را حل کند.
یکی دیگر از کاربردهای رایج یادگیری انتقال، آموزشِ مدلها در مجموعهدادههای کاربران برای رفع مشکل شروع-سرد cold-start problem است. وقتی شرکتهای SaaS برای محصولات یادگیری ماشینشان مشتریان جدید پیدا میکنند، معمولاً با این مشکل روبرو میشوند. در واقع، تا زمانی که مشتری جدید بتواند دادههای کافی برای رسیدن مدل به عملکرد مناسب (که شاید چند ماه طول بکشد)، باید نکاتی را در نظر گیرد.
دادهافزایی Data augmentation
دادهافزایی به معنای افزایش تعداد نقاط دادهای است. ما در تازهترین پروژهمان از روشهای دادهافزایی برای افزایش تعداد عکسها در مجموعهدادهمان استفاده کردهایم. دادهافزایی از منظر دادههای فرمت ردیف/ستون، به معنایِ افزایش تعداد ردیفها یا اشیا است. ما به دو دلیل مجبور بودیم بر دادهافزایی تکیه کنیم: زمان و دقت.
فرایندهای گردآوری داده، هزینههایی به دنبال دارند. این هزینه میتواند در قالب پول، فعالیتهای انسانی، منابع محاسباتی و زمان نمایان شود. متعاقباً، مجبور به افزودن داده بودیم تا اندازه دادههایی که در طبقهبندیکنندههای یادگیری ماشین به کار میبریم، افزایش پیدا کند و هزینههای مربوط به گردآوری داده جبران شود.
راههای زیادی برای دادهافزایی وجود دارد
در این مورد، امکان چرخش تصویر، تغییر شرایط روشنایی و قطع متفاوت آن وجود دارد. پس میتوان زیرنمونههای مختلفی برای یک تصویر ایجاد کرد. به این ترتیب، قادر خواهید بود از میزان بیشبرازش طبقهبندی کننده کم کنید. با این حال، اگر در حال ایجاد دادههای مصنوعی با استفاده از روشهایی مثل SMOTE هستید، احتمال دارد بیشبرازش اتفاق بیفتد.
مدل بیشبرازش شده مدلی است که خطاهای موجود در دادههایی که روی آنها آموزش دیده را نشان میدهد، ولی پیشبینیِ دقیقِی برای دادههای مشاهده نشده ارائه نمیدهد. باید در هنگام توسعه راهحل هوش مصنوعی به این مورد توجه داشته باشید.
دادههای مصنوعی
دادههای مصنوعی به آن دسته از دادههای ساختگی اشاره میکند که حاوی طرحها و ویژگیهای آماریِ یکسان با دادههای واقعی است. اساساً، این دادهها به قدری واقعی به نظر میرسند که تفکیکشان تقریباً غیرممکن است. خب، هدف از بهکارگیری دادههای مصنوعی چیست؟ اگر به دادههای واقعی دسترسی داریم، چه لزومی دارد از دادههای مصنوعی استفاده کنیم؟
بهکارگیری دادههای مصنوعی، زمان سروکار داشتن با دادههای خصوصی (بانکداری، مراقبتهای پزشکی و غیره) هم رخ داده است. این موضوع باعث میشود استفاده از دادههای مصنوعی به روشی امن و مطمئن تبدیل شود. دادههای مصنوعی عمدتاً زمانی مورد استفاده قرار میگیرند که داده واقعی به مقدار کافی وجود نداشته باشد و با کمبود داده در یادگیری ماشین مواجه باشیم یا دادههای واقعیِ کافی برای الگوهای مد نظر شما در دسترس نباشند.
روش «SMOTE» و «Modified – SMOTE» به تولید دادههای مصنوعی میپردازند. «SMOTE» از نقاط دادهای اقلیت استفاده کرده و نقاط دادهای جدیدی ایجاد میکند که بین دو نقطه داده نزدیک واقع شدهاند. این الگوریتم، فاصله میان دو نقطه داده را در فضای ویژگی محاسبه میکند؛ فاصله را به عددی تصادفی بین صفر و یک ضرب میکند و نقطه داده جدید را در این فاصله جدید قرار میدهد.
برای اینکه اقدام به ایجاد دادههای مصنوعی کنید، باید از یک مجموعه آزمایشی برای تعریف مدل استفاده کنید که این کار به اعتبارسنجی نیاز دارد. آنگاه میتوانید با تغییر پارامترهای دلخواه، دادههای مصنوعی را ایجاد کنید.