
رقابت ترانسفورماتورها: ELECTRA ،BERT،ROBERTA یا XLNet
 تیم تحریریه
تیم تحریریه- ۱۴ شهریور ۱۴۰۰
یکی از «رموز» موفقیت مدلهای ترانسفورماتورها رویکرد انتقال یادگیری Transfer Learning است. در رویکرد انتقال یادگیری، از پیش یک دیتاست با حجم بالا به یک مدل (در این مورد یک مدل ترانسفورماتور) آموزش داده میشود؛ در این رویکرد برای آموزش مدل از تکنیک پیشآموزش بدون نظارت Unsupervised Learning استفاده میشود. در مرحله بعد، این مدل بر روی مسئله (وظیفهای) که در حال اجرا است، تنظیم دقیق Fine Tuning (معمولاً آموزش بانظارت Supervised Learning) میشود. جذابیت این رویکرد در این است که دیتاست تنظیم دقیق، میتواند بسیار کوچک، برای مثال حاوی 500 تا 1000 نمونه آموزشی باشد. علاوه بر این حجم کم دیتاست موجب میشود که فقط یک بار نیاز باشد که بخش زمانبر و هزینهبر روند پردازشی، یعنی پیش آموزش، را اجرا کنیم و همچنین میتوانیم مجدداً از مدل پیش آموزشداده شده Pretrained models در بسیاری از مسائل دیگر استفاده کنیم. با توجه به اینکه مدلهای پیش آموزشداده شده در دسترس عموم قرار میگیرند به آسانی میتوانیم مدل مورد نیاز خود را پیدا کنیم و آن را به صورت دقیق بر روی دیتاستها تنظیم کنیم و فقط پس از گذشت چندین ساعت مدل کاملاً جدیدی در اختیار خواهیم داشت.
ELECTRA یکی از جدیدترین مدلهای پیشآموزش داده شده ترانسفورماتورها transformers است که گوگل عرضه کرده است؛ ELECTRA در مقایسه با سایر مدلهای پیشآموزش داده شده عملکرد بهتری دارد. در اغلب موارد مدلهای از رویکرد یادگیری عمیق تبعیت میکنند، به نحوی که هرچه مدل بزرگتر باشد به آموزش بیشتری احتیاج دارد و هرچه حجم دیتاست بالاتر باشد، عملکرد مدل بهتر خواهد بود. با وجود این ELECTRA در جهت مخالف این روند عمل میکند؛ ELECTRA عملکرد بهتری نسبت به مدلهای قبلی از جمله BERT دارد و در همان حال از توان محاسباتی کمتر، دیتاستهای کوچکتر استفاده میکند و مدت زمان آموزش آن کمتر است (جالب است بدانید اندازه ELECTRA با BERT یکسان است).
در این مقاله نحوه استفاده از مدل پیش آموزشداده شده ELECTRA در طبقهبندی متن text classification را بررسی میکنیم و سپس آن را با سایر مدلهای مورد استفاده در این حوزه مقایسه میکنیم. سپس عملکرد نهایی (ضریب همبستگی متیوز Matthews correlation coefficient (MCC)) و مدت زمان آموزش مدلهای مقابل را با یکدیگر مقایسه خواهیم کرد:
- electra-small
- electra-base
- bert-base-cased
- distilbert-bert-cased
- distilroberta-base
- roberta-base
- xlnet-base-cased
همانند گذشته این کار را با کتابخانه Simple Transformers (مبتنی بر کتابخانه Hugging Face Transformers) انجام خواهیم داد و برای مصورسازی Visualization از Weights & Biases استفاده میکنیم. برای دسترسی به کدهای مورد استفاده در این مقاله به دایرکتوری نمونههای کتابخانه مراجعه کنید.
نصب
1- با کلیک بر روی این لینک Anaconda یا MiniConda Package Manager را نصب کنید.
2- یک فضای مجازی Virtual Environment جدید ایجاد کنید و پکیجها را در آن نصب کنید.
conda create -n simpletransformers python pandas tqdm
conda activate simpletransformers
conda install pytorch cudatoolkit=10.1 -c pytorch
3- در صورتیکه از fp16 استفاده میکنید، Apex را نصب کنید. مطابق با دستورالعملهای ارائهشده در اینجا عمل کنید.
4- simpletransformers را نصب کنید.
pip install simpletransformers
آمادهسازی داده
در اینجا از دیتاست Yelp Review Polarity طبقهبندی باینری Binary Classification که یک دیتاست است استفاده میکنیم. با استفاده از کد زیر میتوانید این دیتاست را دانلود و سپس آن را در دایرکتوری data ذخیره کنید یا میتوانید به صورت دستی دادهها را از FastAI دانلود کنید.
1 mkdir data 2 wget https://s3.amazonaws.com/fast-ai-nlp/yelp_review_polarity_csv.tgz -O data/data.tgz 3 tar -xvzf data/data.tgz -C data/ 4 mv data/yelp_review_polarity_csv/* data/ 5 rm -r data/yelp_review_polarity_csv/ 6 rm data/data.tgz
هایپرپارامتر
پس از آنکه دادهها در دایرکتوری data قرار گرفتند، میتوانیم فرایند آموزش مدلها را آغاز کنیم. روشهای متفاوتی برای پیکربندی مدلهای Simple Transformers وجود دارد ( بر روی این لینک کلیک کنید) اما در این مقاله روشهای سادهتری به کار گرفتهایم و با این جود هایپرپارامترهای مورد نظر محقق میشوند. دلیل استفاده از روشهای ساده این است که قصد داریم به جای بهینهسازی بهترین پارامترها برای هر مدل، مدلها را در شرایطی یکسان با یکدیگر مقایسه کنیم.
از این روی train_batch_size را به 128 و num_train_epochs را به 3 افزایش میدهیم در نتیجه تمامی مدلهای به اندازه کافی آموزش خواهند دید.
چالشی که در اینجا با آن مواجه میشویم این است که نمیتوان با یک سخت افزار RTX Titan GPU و مقدار train_batch_size 128 اقدام به آموزش XLNet کرد و به همین دلیل train_batch_size برای XLNet به 64 کاهش داده میشود. در هر حال تأثیرات ناشی از این مغایرت را میتوان با تنظیم gradient_accumulation_steps بر روی 2 به حداقل رساند و در نتیجه اندازه دسته به 128 تغییر میکند. ( گرادیانها محاسبه میشوند و وزن مدلها برای هر دو مرحله فقط یک بار به روزرسانی میشود).

حالت پیشفرض سایر تنظیماتی که بر فرایند آموزش تأثیر میگذارند، تغییر نمیکند.
آموزش مدلها
فرایند آموزش بسیار ساده است. برای آغاز کردن فرایند آموزش فقط به بارگذاری دادهها در Dataframes و هایپرپارامترهای تعریفشده نیاز داریم و سپس میتوانیم کار خود را آغاز کنیم. برای سهولت در کار و با توجه به اینکه میان هر اجرا فقط لازم است که اسم مدل را تغییر دهیم، من برای آموزش تمامی مدلها از یک کد واحد استفاده میکنم. یک زیر برنامه واسط برای هر مدل یک اسم انتخاب میکند و علاوه بر آن به صورت خودکار کد آموزش را برای هر مدل اجرا میکند.
1 import sys
2
3 import pandas as pd
4 from simpletransformers.classification import ClassificationModel
5
6
7 prefix = 'data/'
8
9 train_df = pd.read_csv(prefix + 'train.csv', header=None)
10 train_df.head()
11
12 eval_df = pd.read_csv(prefix + 'test.csv', header=None)
13 eval_df.head()
14
15 train_df[0] = (train_df[0] == 2).astype(int)
16 eval_df[0] = (eval_df[0] == 2).astype(int)
17
18 train_df = pd.DataFrame({
19 'text': train_df[1].replace(r'\n', ' ', regex=True),
20 'labels':train_df[0]
21 })
22
23 print(train_df.head())
24
25 eval_df = pd.DataFrame({
26 'text': eval_df[1].replace(r'\n', ' ', regex=True),
27 'labels':eval_df[0]
28 })
29
30 print(eval_df.head())
31
32
33 model_type = sys.argv[1]
34
35 if model_type == "bert":
36 model_name = "bert-base-cased"
37
38 elif model_type == "roberta":
39 model_name = "roberta-base"
40
41 elif model_type == "distilbert":
42 model_name = "distilbert-base-cased"
43
44 elif model_type == "distilroberta":
45 model_type = "roberta"
46 model_name = "distilroberta-base"
47
48 elif model_type == "electra-base":
49 model_type = "electra"
50 model_name = "google/electra-base-discriminator"
51
52 elif model_type == "electra-small":
53 model_type = "electra"
54 model_name = "google/electra-small-discriminator"
55
56 elif model_type == "xlnet":
57 model_name = "xlnet-base-cased"
58
59 train_args = {
60 "reprocess_input_data": True,
61 "overwrite_output_dir": True,
62 "use_cached_eval_features": True,
63 "output_dir": f"outputs/{model_type}",
64 "best_model_dir": f"outputs/{model_type}/best_model",
65 "evaluate_during_training": True,
66 "max_seq_length": 128,
67 "num_train_epochs": 3,
68 "evaluate_during_training_steps": 1000,
69 "wandb_project": "Classification Model Comparison",
70 "wandb_kwargs": {"name": model_name},
71 "save_model_every_epoch": False,
72 "save_eval_checkpoints": False,
73 "train_batch_size": 128,
74 "eval_batch_size": 64,
75 }
76
77 if model_type == "xlnet":
78 train_args["train_batch_size"] = 64
79 train_args["gradient_accumulation_steps"] = 2
80
81
82 # Create a ClassificationModel
83 model = ClassificationModel(model_type, model_name, args=train_args)
84
85 # Train the model
86 model.train_model(train_df, eval_df=eval_df)
توجه داشته باشید که دیتاست Yelp Reviews Polarity به ترتیب از برچسبهای [1 , 2] برای مثبت و منفی استفاده میکند. من برچسبهای مثبت و منفی را به [0 , 1] تغییر میدهیم. لازم است برچسبهای Simple Transformers از 0 شروع شود و (به عقیده من) برچسب 0 برای احساسات منفی بسیار شهودیتر است.
1 rm -r cache_dir 2 python train.py electra-small 3 4 rm -r cache_dir 5 python train.py electra-base 6 7 rm -r cache_dir 8 python train.py bert 9 10 rm -r cache_dir 11 python train.py roberta 12 13 rm -r cache_dir 14 python train.py distilbert 15 16 rm -r cache_dir 17 python train.py distilroberta 18 19 rm -r cache_dir 20 python train.py xlnet
توجه داشته باشید که در هر مرحله با افزودن rm -r outputs به بَش اسکریپت Bash script میتوانید مدلهای ذخیرهشده را حذف کنید. اگر حافظه کافی برای ذخیره تمامی مدلها را ندارید، حذف مدلها میتواند ایده خوبی باشد. علاوه بر این اسکریپت آموزشی امتیازات ارزیابی را در Weights & Biases ذخیره میکند و امکان مقایسه مدلها را برای ما فراهم میکند.
برای کسب اطلاعات بیشتر راجع به آموزش مدلهای طبقهبندی به اسناد Simple Transformers مراجعه کنید.
نتایج
برای دسترسی به نتایج من بر روی این لینک کلیک کنید. سعی کنید گرافها و اطلاعات مختلف را امتحان و بررسی کنید. در این قسمت نتایج مهم را بررسی میکنیم.
امتیازات نهایی
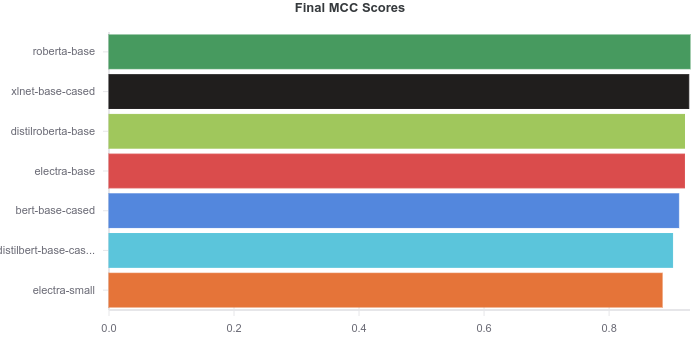
امتیازاتی که در نمودار بالا نشان داده شده است امتیاز نهایی MCC هر مدل است. همانگونه که در نمودار بالا مشاهده میکنید امتیاز تمامی مدلها تقریباً با هم یکسان است. برای آنکه تفاوتها بهتر نمایش داده شود، در نمودار مقابل محور X با بزرگنمایی شده است و فقط امتیازات 0.88 تا 0.94 را نشان میدهد. توجه داشته باشید که یک نمای بزرگنمایی شده در عین حال که میتواند به نشان دادن بهتر تفاوتها کمک کند میتواند درک نتایج را نیز با مشکل مواجه کند. از این روی نمودار مقابل برای توضیح و شفافسازی بیشتر ارائه شده است.
حواستان به نمودارهایی که عدد صفر در آنها نمایش داده نشده، باشد!
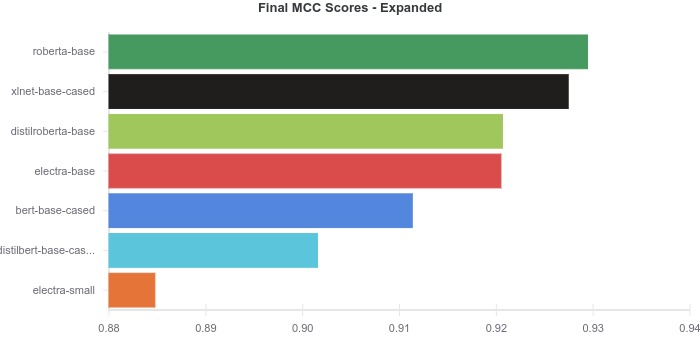
مدل roberta-base در ابتدای بسته و پس از آن xlnet-base قرار میگیرد و دنبال آن مدلهای distilroberta-base و electra-base قرار میگیرند و به ندرت چیزی میان این دو مدل قرار میگیرد. در این مورد تفاوت میان این دو مدل احتمالاً بیشتر تصادفی است تا اینکه دلیل خاصی داشته باشد. در آخر نیز bert-based-cased، distilbert-base-cased و electral-small قرار میگیرند. همانگونه که مشاهده میکنید امتیاز MCC مدلهای بسیار به هم نزدیک است.
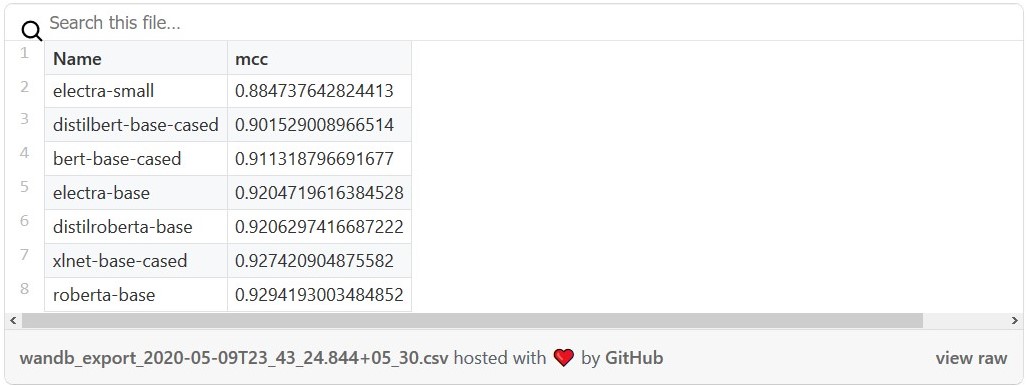
در این آزمایش RoBERTA عملکرد بهتری نسبت به سایر مدلها داشت. اما به عقیده من با اعمال برخی تغییرات همچون بهینهسازی هایپرپارامترها Hyperparameter tuning و جمعبندی هایپرپارامترها مدل ELECTRA میتواند عملکرد بهترین نسبت به سایر مدلها داشته باشد. همانگونه که در جدول امتیازات Bash script معیار GLUE هم نشان داده شده است، عملکرد ELECTRA بهتر از RoBERTA است.
به خاطر داشته باشید که مدل ELECTRA در مقایسه با RoBERTA به منابع کمتری (حدود یک چهارم) برای پیشآموزش نیاز دارد. این موضوع برای distilroberta-base نیز صدق میکند. هرچند مدل distilroberta-base نسبتاً کوچکتر است اما قبل از اینکه بتوانید دانش این مدل را به distilroberta-base منتقل کنید Knowledge Distillation به مدل اصلی roberta-base نیاز پیدا خواهید کرد.
مدل XLNet تقریباً عملکردی مشابه مدل RoBERTA دارد اما در مقایسه با تمامی مدلهایی که در این مقاله به آنها اشاره کردیم به به منابع محاسباتی بیشتری نیاز دارد ( به نمودار مدت زمان آموزش رجوع کنید). تمامی مدلها به غیر از مدل electra-small عملکرد بهتری از مدل BERT (هرچند که کمتر از دو سال از عرضه آن میگذرد) داشتند.

مدت زمان آموزش
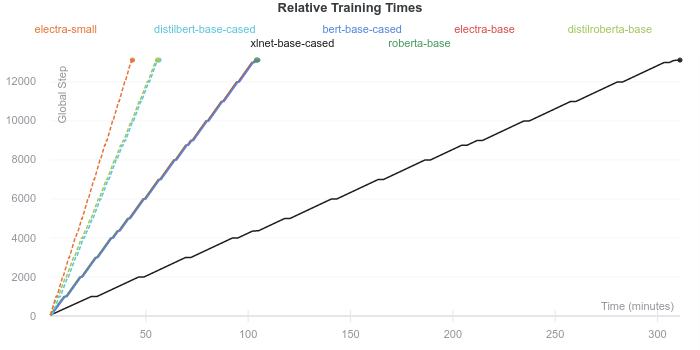

سرعت آموزش اغلب به اندازه ( تعداد پارامترها) مدل ، به استثنای XLNet، بستگی دارد. هرچند تعداد پارامترهای مدل XLNet تقریباً با تعداد پارامترهای سایر مدلها برابر است، اما الگوریتمهایی که برای آموزش Training algorithm XLNet مورد استفاده قرار میگیرند موجب میشوند سرعت این مدل نسبت به مدلهای BERT،RoBERTA و ELECTRA کندتر باشد. علاوه بر این میزان حافظه GPU مورد نیز برای XLNet نسبت به سایر مدلهایی که آزمایش کردیم، بیشتر است و به همین دلیل لازم است اندازه دسته آموزشی این مدل کوچکتر باشد ( اندازه دسته آموزش این مدل 64 و اندازه دسته آموزشی سایر مدلها 128 است).
مدت زمان استنباط Inference times (در اینجا آزمایش نشده) مطمئناً همین روند را دنبال میکند. موضوع مهم دیگری که باید به آن توجه کنیم این است که چه مدت زمان طول میکشد تا هر مدل همگرا شود. تمامی مدلهایی که به آنها اشاره کردیم طی سه دوره بدون تنظیم هیچگونه توقف پیش از موعد Early stopping آموزش داده شدهاند.
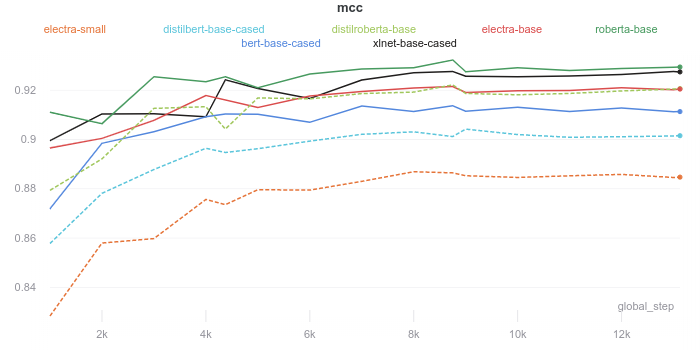
ظاهراً با توجه به تعداد مراحل آموزشی مورد نیاز برای همگرایی Convergence، مدلها تفاوت مشهودی با یکدیگر ندارند. به نظر میرسد تمامی مدلها پس از حدود 9000 مرحله آموزش همگرا میشوند. البته به دلیل تفاوت در سرعت آموزش، مدت زمان لازم برای همگرا شدن هم متفاوت است.
نتیجهگیری
انتخاب یکی از مدلهای ترانسفورماتور دشوار است. با وجود این مقایسه این مدلها به ما کمک میکند تا به بینش ارزشمندی دست پیدا کنیم:
- بسته به موقعیت مدلهای قدیمیتر میتوانند عملکرد بهتری نسبت به مدلهای ELECTRA داشته باشند. اما مزیت مدلهای ELCTRA بر سایر مدلها این است که ELCTRA از منابع محاسباتی کمتر برای پیش آموزش استفاده میکند و در عین حال میتواند عملکرد خوبی داشته باشد.
- نتایج حاصل از پژوهشی حول موضوع ELECTRA نشان میدهد که مدل electra-small در مقایسه با مدل BERT با اندازه مشابه عملکرد چشمگیرتری دارد.
- نرخ دقت نسخههای منتقل شده Distilled مدلهای ترانسفورماتور کمتر است به دلیل اینکه سرعت استنباط و آموزش آنها بیشتر است. در برخی موارد ممکن است این موضوع سودمند باشد.
- سرعت آموزش و استنباط XLNET برای آنکه عمکرد بهتری در مسائل پیچیده داشته باشد، کمتر است.
بر مبنای این یافتهها، پیشنهاد من به شما این است (از آنجاییکه نتایج میان دیتاستهای مختلف میتواند متفاوت باشد باید احتیاط کنید):
- distilroberta-base کماکان شروع خوبی برای اجرای برخی مسائل است. با توجه به نتایج به دست آمده میتوانید راجع به تنظمی هایپرپارامترها تصمیمگیری کنید و تعداد آنها را کاهش یا افزایش دهید.
- اگر در حال آموزش یک مدل زبانی جدید هستید یا اگر تصمیم دارید یک مدل زبانی را دقیق تنظیم کنید، به ویژه اگر منابع محاسباتی کمی دارید و یا دسترسی به دادهها محدود است، به شما پیشنهاد میکنم از ELECTRA استفاده کنید.





