
مدیریت دیتاستهای نامتوازن در مسائل ردهبندی دودویی (بخش اول)
 تیم تحریریه
تیم تحریریه- ۲۳ خرداد ۱۴۰۱
هر گاه بخواهیم مسئلهای را برای یک مدل یادگیری ماشین تعریف کنیم، اولین قدم، تجزیه و تحلیل دادههاست؛ از این دادهها برای آموزش و آزمایش مدل استفاده میشود و مدل بر اساس آنها استدلال انجام میدهد. در غالب موارد، قبل از شروع کار، لازم است دیتاست را بازطراحی کنیم یا حداقل با ورود چند ویژگی به مرحله آموزش، مدل را برای شرایط ابتدایی دادهها آماده کنیم.
یکی از این شرایط، میتواند عدم توازن دادهها Unbalanced data باشد؛ در این مجموعه مقالات قصد داریم، مسئله دادههای نامتوازن در مسائل ردهبندی دودوییBinary classification را بررسی کنیم.
دیتاست نامتوازن
زمانی که متغیر وابسته (که در مسائل رگرسیون، پیوسته و در مسائل ردهبندی، گسسته یا دستهای است) توزیع بسیار کجیSkewed داشته باشد، دادههای ما نامتوازن هستند. به این مثال توجه کنید:
فرض کنید باید مدلی بسازیم که بتواند دادههای مربوط به معاملات واقعی کارتهای اعتباری را از معاملات کلاهبرداری تشخیص دهد. بدین منظور، به دیتاستی شامل دادههای مربوط به معاملات گذشته نیاز داریم. این دادهها باید مورد سنجش و ارزیابی قرار بگیرند، تا مشخص شود واقعی هستند یا کلاهبرداری. به بیان دیگر، دادههای ما برچسب دارند؛ به همین دلیل مسئله از نوع یادگیری نظارتشده است. احتمال اینکه یکی از این دادهها کلاهبرداری باشد، از اینکه مربوط به معاملات واقعی باشد، خیلی کمتر است؛ به عبارتی، شاید بتوان گفت تنها 10 درصد از کل دیتاست، مربوط به معاملات کلاهبرداری است. در چنین شرایطی، با یک عدم توازن شدید در دادهها روبهرو هستیم و باید این مشکل را به نحوی حل کنیم.
چرا حل این مشکل، ضروری است؟ الگوریتم از روی دادهها میآموزد؛ اگر دادهها در جهت یک کلاس سوگیری داشته باشند، الگوریتم هم در جهت همان کلاس سوگیری خواهد داشت. به عبارت دیگر، الگوریتم به سرعت میآموزد که پیشبینی کلاسی که بیشترین فراوانی را دارد، به نتایج خوبی منتهی میشود؛ هر چند واقعیت این است که این نتیجه خوب به قیمت اختصاص برچسب اشتباه به دادهها تمام میشود. این برچسبهای اشتباه نادر هستند، اما این مسئله به خاطر قدرت الگوریتم نیست، بلکه به این دلیل است که کلاس اقلیت، نمونههای کمی دارد که بتوانند برچسب اشتباه بخورند.
به همان مثال معاملات کلاهبرداری بر میگردیم. دیتاستی شامل 100 نمونه را تصور کنید که فقط 10 تا از دادههای آن برچسب کلاهبرداری دارند. اگر الگوریتم ما برچسب غیرکلاهبرداری را به همه نمونهها اختصاص دهد، دقت آن 90 درصد خواهد بود که عدد خیلی خوبی است؛ اما واضح است که همه معاملات کلاهبرداری، برچسب اشتباهی دریافت کردهاند. چنین اشتباهی به شرکت بیمه فرضی که این الگوریتم را به کار ببرد، زیانی جبرانناپذیر وارد خواهد کرد.
در چنین شرایطی چه میکنیم؟ درحالحاضر، روشهایی وجود دارند (از اصلاح دیتاست گرفته تا پیادهسازی سوگیری مخالف در الگوریتمها) که با استفاده از آنها میتوان این مشکل را حل کرد. در نوشتار حاضر که قسمت اول از یک مجموعه است، بر تکینکهایی تمرکز خواهیم کرد که دیتاست اصلی را مستقیماً دستکاری میکنند، تا بعد از تغذیه به الگوریتم، موجب سوگیری آن نشود؛ به این تکنیکها، روشهای بازنمونهگیریResampling methods گفته میشود. در این مقاله، روشهای نمونهگیری افزایشی، نمونهگیری کاهشی و SMOTE (بیشنمونهبرداری مصنوعی کلاس اقلیتSynthetic Minority Over-sampling Technique ) را مورد بررسی قرار میدهیم.
نمونهگیری افزایشی، کاهشی و SMOTE
برای پیادهسازی این تکنیکها در پایتون، از ماژول sklearn به نام imbalanced-learn استفاده میکنیم (شما هم از طریق pip بهراحتی میتوانید آن را نصب کنید).
ابتدا یک دیتاست مصنوعی نامتوازن تولید میکنیم:
from sklearn.datasets import make_classification import pandas as pd X, y = make_classification( n_classes=2, class_sep=1.5, weights=[0.9, 0.1], n_informative=2, n_redundant=0,n_repeated=0, flip_y=0, n_features=2, n_clusters_per_class=1, #for visualization purposes n_samples=1000, random_state=123 ) df = pd.DataFrame(X) df['target'] = y df.target.value_counts().plot(kind='bar', title='Count (target)', color = ['b', 'g'])

از آنجایی که دو ویژگی داریم، میتوانیم دیتاست را در یک نمودار پراکندگیScatter plot دو بُعدی نمایش دهیم.
import matplotlib.pyplot as plt
groups = df.groupby("target")
for name, group in groups:
plt.plot(group[0], group[1], marker="o", linestyle="", label=name)
plt.legend()
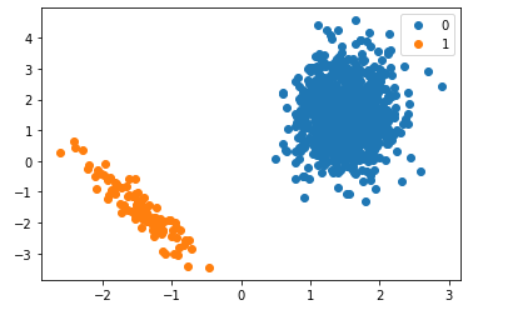
حال از سه طریق این مسئله را حل میکنیم:
۱– نمونهگیری کاهشی کلاس اکثریت: در این روش، نمونههایی از کلاس اکثریت حذف میشوند. نقطهضعف این رویکرد این است که مقدار کلی دادهها نیز کاهش مییابد. تکنیکهای گوناگونی برای کاهش این نمونهها وجود دارند، اما اینجا از رویکرد ساده تصادفی استفاده میکنیم:
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(return_indices=False)
X_rus, y_rus = rus.fit_sample(X, y)#visualizing resultsdf_down_samp = pd.DataFrame(X_rus)
df_down_samp['target'] = y_rusimport matplotlib.pyplot as pltgroups = df_down_samp.groupby("target")
for name, group in groups:
plt.plot(group[0], group[1], marker="o", linestyle="", label=name)
plt.legend()

همانطور که مشاهده میکنید، در مقایسه با نمودار قبلی،در اینجا کلاس 0 و 1 از نظر تعداد نقطهدادهها به هم نزدیکتر شدهاند.
نمودار مربوط به این قسمت که در پست هست اضافه نشده.
۲– نمونهگیری افزایشی کلاس اقلیت: این رویکرد، نمونههای کلاس اقلیت را افزایش میدهد. یک روش این است که نمونهگیری تصادفی را با جایگزینی از کلاس اصلی همراه کنیم. عیب این رویکرد حضور نمونههای تکراری در میان دادههاست. در این قسمت نیز از نمونهگیری تصادفی با جایگزینی استفاده میکنیم:
from imblearn.over_sampling import RandomOverSamplerros = RandomOverSampler()
X_ros, y_ros = ros.fit_sample(X, y)df_up_samp = pd.DataFrame(X_ros)
df_up_samp['target'] = y_rosimport matplotlib.pyplot as pltgroups = df_up_samp.groupby("target")
for name, group in groups:
plt.plot(group[0], group[1], marker="o", linestyle="", label=name)
plt.legend()

چون نتیجه بهدستآمده در این تصویر، بهخوبی مشخص نشده است، از این کد استفاده میکنیم، تا تفاوت تعداد نمونههای کلاس 1 را قبل و بعد از اجرای این روش محاسبه کنیم:
print(X_ros.shape[0] - X.shape[0])Output: 800
۳– بیشنمونهبرداری مصنوعی کلاس اقلیت (SMOTE): در این روش هم از نمونهگیری کاهشی و هم نمونهگیری افزایشی استفاده میشود. رویکرد SMOTE برای نمونهگیری افزایشی کلاس اقلیت، یک نقطه تصادفی از این کلاس انتخاب میکند، K عدد از نزدیکترین همسایههای آن را محاسبه و ترکیب آنها را بهعنوان خروجی تولید میکند؛ بدین ترتیب نمونههای جدید به دست میآیند. روش SMOTE از کلاس اکثریت نیز نمونهگیری کاهشی انجام میدهد، تا نهایتاً کل دیتاست به توازن برسد. نمونهگیری کاهشی کلاس اکثریت با حذف تصادفی نقطهدادهها انجام میشود. به خاطر داشته باشید که در این قسمت نسبت پارامتری را برابر با کلاس اقلیت تنظیم کردهایم، یعنی نمونهگیری افزایشی روی کلاس اقلیت اجرا میکنیم:
from imblearn.over_sampling import SMOTEsmote = SMOTE(ratio='minority')
X_sm, y_sm = smote.fit_sample(X, y)df_sm = pd.DataFrame(X_sm)
df_sm['target'] = y_smimport matplotlib.pyplot as pltgroups = df_sm.groupby("target")
for name, group in groups:
plt.plot(group[0], group[1], marker="o", linestyle="", label=name)
plt.legend()
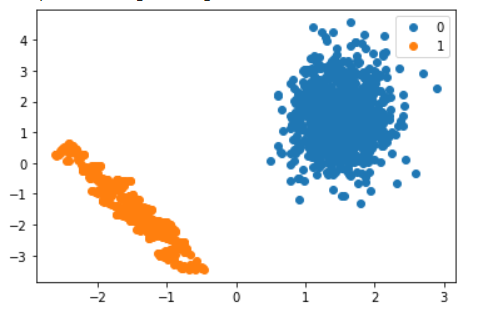
جمعبندی
در این مقاله که قسمت اول از یک مجموعه بود، در خصوص رویکردهای اصلی بازنمونهگیری دیتاستهای نامتوازن صحبت کردیم. این تکنیکها جامع و کامل نیستند و امروزه روشهای جدیدی نیز مطرح شدهاند. بااینحال، این روشها میتوانند درباره دستکاری دیتاستها (در صورت رویارویی با مسئله عدمتوازن در دادهها) اطلاعات خوبی به ما بیاموزند.
در قسمت دوم این مجموعه بر تکنیکهای دیگری تمرکز خواهیم کرد که با اصلاح الگوریتمها در مرحله آموزش، سعی در حل عدم توازن دادهها دارند.
از طریق لینک زیر میتوانید به بخش دوم دسترسی داشته باشید:
مدیریت دیتاستهای نامتوزان در مسائل ردهبندی دودویی (بخش دوم)





