یادگیری انتقالی در پردازش زبان طبیعی – بخش دوم
 تیم تحریریه
تیم تحریریه- ۳ آبان ۱۴۰۰
مقاله حاضر دومین بخش از سری مقالات یادگیری انتقالی در پردازش زبان طبیعی است. چنانچه به تازگی به حوزه پردازش زبان طبیعی ورود پیدا کردهاید، به شما توصیه میکنم اولین بخش از این سری مقالات که لینک آن در انتهای مطلب قرار دارد را هم مطالعه کنید.
از زمان انتشار مدل زبانی BERT (ماه اکتبر سال 2018) اتفاقات گوناگونی روی داده است.
- آیا میدانستید مدلسازی زبانی مخفی Masked language modelling BERT کارایی سابق را ندارد؟
- آیا میدانستید لازم نیست مکانیزم توجه به لحاظ زمانی درجه دوم باشد؟
- آیا میدانستید میتوانید بدون کسب اجازه از مدل گوگل استفاده کنید؟
برخی از باهوشترین افراد دوران معاصر زمان خود را وقف تحقیق و پژوهش کردهاند و آثار علمی زیادی به چاپ رساندهاند. شاید بتوان گفت در حال حاضر NLP جذابترین حوزهای است که میتوان وقت خود را صرف آن کرد .
- NLProc مسیر طولانی را پشت سر گذاشته است.
- به خلاصه و جمعبندی دیگری احتیاج داریم.
پاسخهای شما به این 20 سؤال نشان میدهد چقدر اطلاعاتتان راجع به وضعیت کنونی یادگیری انتقالی در پردازش زبان طبیعی به روز است و شما را برای وارد شدن به یک بحث و گفتوگوی تخصصی آماده میکند.
1- وضعیت کنونی مدلهای از پیش آموزش داده شده (PTM) به چه صورت است؟

https://arxiv.org/pdf/2003.08271.pdf
2- از چه مسائلی برای آموزش PTMها استفاده میشود؟

https://arxiv.org/pdf/2003.08271.pdf
3- بهترین عملکرد PTMها بر روی GLUE به چه صورت است؟

https://arxiv.org/pdf/2003.08271.pdf
4- آیا استفاده از دادههای بیشتر همیشه به معنای مدل زبانی بهتر است؟
نتایج حاصل از مطالعه T5 نشان میدهد که استفاده از دادههای بیشتر لزوماً به معنای مدلی بهتر نیست. کیفیت داده ها بر کمیت آنها ارجحیت دارد.

https://arxiv.org/pdf/1910.10683.pdf
5- بهترین متد توکنسازی برای آموزش مدلهای زبانی کدام است؟
نتایج حاصل از این مقاله نشان میدهد که متد جدید Unigram LM بهتر از BPE و WordPiece است.
[irp posts=”11909″]6- بهترین مسئله برای آموزش یک مدل زبانی کدام است؟
در حال حاضر بهترین رویکرد موجود ELECTRA است؛ در این رویکرد به کمک مولد، توکن ورودی جایگزین میشود و متمایزکننده توکنی که مشکل داشته را پیشبینی میکند.

https://arxiv.org/pdf/2003.10555.pdf

https://arxiv.org/pdf/2003.10555.pdf
علاوه بر این، نتایج حاصل از مقاله T5 نشان میدهد اگر مسائل تشخیص span را 3 بار کاهش دهیم هم به نتایج خوبی دست پیدا میکنیم.

https://arxiv.org/pdf/1910.10683.pdf
7- آیا برای آموزش ترنسفورمر بر روی یک مسئله حتماً باید عملیات unfreeze کردن تدریجی را انجام دهیم؟
نتایج حاصل از مقاله T5 نشان میدهد که unfreeze کردن تدریجی ضروری نیست.

https://arxiv.org/pdf/1910.10683.pdf
8- اگر برای آموزش مدل یک بودجه مشخص داشته باشید، برای رسیدن به یک مدل زبانی بهتر چه چیزی را میتوانید تغییر دهید؟
نویسندگان مقاله T5 پیشنهاد میکنند برای ساخت یک مدل زبانی بهتر، مدت زمان و تعداد مراحل آموزشی را افزایش دهیم.

https://arxiv.org/pdf/1910.10683.pdf
9- چنانچه توالی شما طولانیتر از 512 توکن باشد از چه مدلی استفاده میکنید؟
Transformer-Xl یا Longformer
10- مدت زمان پردازش ترنسفورمر چگونه با طول توالی تطبیق پیدا میکند؟
Quadratic
11- با توجه به اینکه در توالیهای طولانی، مدت زمان پردازش ماهیتی درجه دوم دارد، چگونه میتوانیم مدت زمان پردازش اسناد طولانی را برای ترنسفورمرها کاهش دهیم؟
Longformer از یک مکانیزم توجه استفاده میکند که به صورت خطی با طول توالی مطابقت پیدا میکند.

https://arxiv.org/pdf/2004.05150.pdf
Longformer میتواند در کدگذاری اسناد طولانی (برای انجام جستوجوهای معنایی) عملکرد خوبی داشته باشد. جدول مقابل عملکرد آن را تا به امروز نشان میدهد.

https://arxiv.org/pdf/2004.05150.pdf
11- آیا عملکرد فوقالعاده BERT به دلیل استفاده از لایه توجه است؟
نویسندگان مقاله Attention is not Explanation معتقدند توجه تأثیر چندانی بر روی خروجی ندارد و به همین دلیل نمیتوانیم بگوییم عملکرد مدل به صورت مستقیم از آن تأثیر میپذیرد.
[irp posts=”8142″]12- اگر یک شاخه (Head) را حذف کنیم، عملکرد BERT شدیداً افت پیدا میکند؟
نتایج حاصل از مقاله Revealing the Dark Secrets of Bert نشان میدهد که حذف یک شاخه منجر به افت شدید عملکرد مدل نمیشود.
13- اگر یک لایه را حذف کنیم، عملکرد BERT شدیداً افت پیدا میکند؟
نتایج حاصل از مقاله Revealing the Dark Secrets of Bert نشان میدهد که حذف یک لایه منجر به افت شدید عملکرد مدل نمیشود.
14- اگر BERT را به صورت تصادفی مقداردهی کنیم, عملکرد آن به شدت افت پیدا میکند؟
نتایج حاصل از مقاله Revealing the Dark Secrets of Bert نشان میدهد که مقداردهی تصادفی مدل، عملکرد آن را تحت الشعاع قرار نمیدهد.
15- آیا فشردهسازی مدل لازم و ضروری است؟
احتمالاً نه! نکات زیر برگرفته از این مقاله فوقالعاده هستند.
«تکنیکهای فشرده سازی شبکه عصبی با معرفی راهکارهایی که مدلهای بیش پارامترسازی شده تمایل دارند با آنها همگرا شوند، ما را در امر آموزش مدلهای پارامترسازی شده کمک میکنند. انواع زیادی از فشرده سازی مدل وجود دارد و هر یک از آنها از نوع متفاوتی از «سادگی» استفاده میکنند که در شبکه های عصبی آموزش دیده یافت میشود.»
- بسیاری از وزنها نزدیک به صفر هستند (هرس کردن)
- ماتریسهای وزنی سطح پایین هستند (فاکتورگیری وزنی)
- وزنها را فقط با چند بیت میتوان نشان داد ( کوانتومی کردن)
- به طور معمول لایهها توابع مشابه را یاد میگیرند ( اشتراک گذاری وزنی)
16- آیا میتوانیم بدون اجازه از مدلی که دسترسی به آن از طریق API فراهم شده، استفاده کنیم؟
بله، میتوانیم! برای کسب اطلاعات بیشتر این مطلب فوقالعاده را مطالعه کنید.
18- وضعیت کنونی Distillation به چه صورت است؟

https://arxiv.org/pdf/2003.08271.pdf
19- مدلهای بزرگتر ترنسفورمر را سریعتر آموزش میدهند یا مدلهای کوچکتر؟
بر اساس یافتههای این مقاله، مدلهای بزرگتر.
20- چارچوب student-teacher چه کاربردی دارد؟
تقطیر دانش برای ساخت مدلهای کوچکتر

https://arxiv.org/pdf/1909.10351.pdf
ایجاد تعبیههای جملهای Sentence embeddings یکسان برای زبانهای مختلف

https://arxiv.org/pdf/2004.09813v1.pdf
آخرین سوالی که برای محک زدن اطلاعاتتان درباره مبحث یادگیری انتقالی در پردازش زبان طبیعی باید از خودتان بپرسید این است که چگونه مدل طراحی کنیم؟ کدام پارامترها مهمتر هستند؟
سؤال دشواری است!
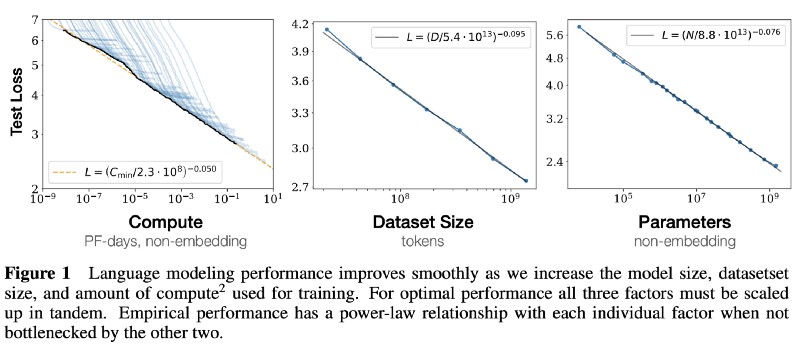
در مقاله Scaling Laws for Neural Language Models به طور کامل به این سؤال پاسخ داده شده و توضیح داده شده که میان موارد زیر همبستگی وجود دارد:
- زیان آزمایش و محاسبه
- زیان آزمایش و اندازه دیتاست
- زیان آزمایش و پارامترها
برای طراحی و آموزش یک مدل، پیش از هر چیز باید معماری مدل و سپس تعداد پارامترهای آن را مشخص کنیم. در گام بعدی هم میتوانیم زیان را محاسبه کنیم. سپس اندازه دادهها را انتخاب کرده و دادههای مورد نیاز را محاسبه میکنیم.
معادلههای مقیاسبندی در نمودار زیر نشان داده شده است.
برای مطالعه بخش اول وارد لینک زیر شوید: