تشخیص اجزای اصلی گل با استفاده از یادگیری عمیق
 تیم تحریریه
تیم تحریریه- ۲۱ مهر ۱۴۰۰
در این نوشتار نحوه تشخیص اجزای اصلی در تصاویر گل را با استفاده از یادگیری عمیق و شبکههای عصبی پیچشی توضیح میدهیم. وجود برخی از اجزای اصلی از جمله ساقه و گل برای تبدیل تصاویر به مدلهای سه بعدی لازم و ضروری است.
BloomyPro
ابتدا لازم است به معرفی Bloomy بپردازیم. کاربران با استفاده از نرمافزار Bloomy موسوم به BloomyPro میتوانند با استفاده از یک مدل 3D، دستهگل مورد نظر خود را در مرورگر طراحی کنند. پرورشدهندگان گل و گیاه، خردهفروشها، عمدهفروشها و توزیعکنندگان گل و سایر افراد و گروههای فعال در صنعت گل و گیاه از این نرمافزار استفاده میکنند.
افراد و گروههای فعال در صنعت گل و گیاه با استفاده از این نرمافزار میتوانند، به جای طراحی دستهگلی واقعی، از دستهگل عکس بگیرند و آن را برای مشتری خود ارسال کنند؛ این افراد میتوانند تمامی این فرایند را به صورت آنلاین انجام دهند و در زمان و هزینهها صرفهجویی کنند.

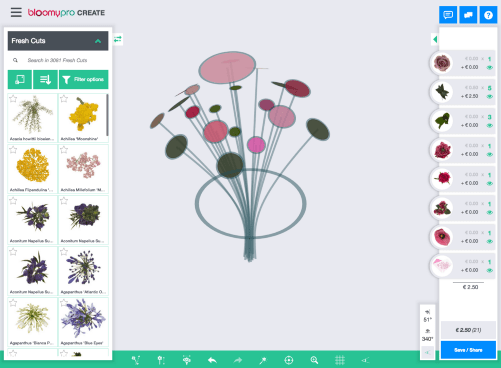
برای اینکه امکان تشخیص تصاویر ایجاد شده از تصاویر دستهگلهای واقعی وجود نداشته باشد، تصاویر ایجادشده تا حد امکان باید به تصاویر واقعی شباهت داشته باشند. برای دستیابی به این هدف باید از تصاویر واقعی گلها که از زوایای مختلف گرفته شدهاند استفاده کرد و سپس آنها را به مدلهای 3D تبدیل کرد.
از هر گل جدید، از 7 زاویه مختف عکس گرفته میشود. در اتاقک گل، گلها با استفاده از موتوری که در کابین تعبیه شده است، به صورت خودکار چرخانده میشوند.
در مقابل، فرایند پس پردازش Post-processing هنوز به طور کامل به صورت خودکار در نیامده است. در حال حاضر هزاران گونه گل در این دیتاست وجود دارد و روزانه گلهای جدیدی به آن افزوده میشود. اگر تعداد گلهای موجود در این دیتاست را در تعداد زوایا (زوایای عکسبرداری از گلها) ضرب کنید، میبینید تصاویر زیادی در اختیار دارید تا به صورت دستی پردازش کنید.
یکی از مراحل پس پردازش، تعیین و تشخیص محل قرارگیری برخی از اجزای اصلی در تصاویر است، پیش از این نیز گفتیم برای تبدیل تصاویر به مدلهای 3D به این اجزا احتیاج داریم. مهمترین اجزا عبارتند از محل ساقه و گلبرگها. در حال حاضر تشخیص محل قرارگیری این اجزا به صورت دستی انجام میشود و هدف ما این است که این مرحله را به صورت خودکار درآوریم.
دیتاست
خوشبختانه در حال حاضر هزاران تصویر در این دیتاست وجود دارد که به صورت دستی با اجزای اصلی گل حاشیهنویسی شدهاند. در نتیجه دادههای آموزشی فراوانی داریم که میتوانیم از آنها استفاده کنیم.

در تصویر فوق، تعدادی از گلهای حاشیهنویسی شده مجموعه آموزشی را مشاهده میکنید. در تصویر فوق یک تصویر از در زوایای مختلف نشان داده شده است. در تصویر فوق، ساقه با رنگ آبی و گلبرگها با رنگ سبز نشان داده شده است.
در برخی از تصاویر ابتدای ساقه توسط گل پنهان شده است. در چنین مواردی باید محلی که بیشترین احتمال را دارد ساقه در آن قرار داشته باشد، حدس بزنیم.

معماری شبکه
به دلیل اینکه مدل به جای کلاس باید عدد خروجی بدهد، از رگرسیون استفاده میکنیم. یکی از دلایل شهرت CNNها عملکرد فوقالعاده آنها در انجام و اجرای مسائل طبقهبندی است، اما این شبکهها در رگرسیون هم عملکرد خوبی دارند. برای مثال، DensePose عملیات برآورد حالتهای بدن انسان Human pose estimation را با بهرهگیری از رویکردی مبتنی بر CNN انجام میدهد.
در این مقاله نحوه عملکرد CNNها را به طور کامل شرح نمیدهیم، چنانچه به این موضوع علاقهمند هستید این مقاله را که حول موضوع اصول و مبنای CNN است مطالعه کنید.
شبکه از چندین بلوک کانولوشن استاندارد تشکیل شده است. هر لایه از 3 لایه کانولوشن، max-pooling، batch normalization و لایه dropout تشکیل شده است.
- لایههای کانولوشن از تعدادی فیلتر تشکیل شدهاند. هر فیلتر همانند یک تشخیص دهند الگو عمل میکند. لایههای کانولوشن بعدی فیلترهای بیشتری دارند و به همین دلیل این لایه میتواند الگوهایی درون الگوها پیدا کند.
- Max-pooling وضوح تصویر را کاهش میدهد و در نتیجه تعداد پارامترهای مدل کاهش پیدا میکنند. اغلب، در مسائل طبقهبندی تصویر موضوعی که بیشترین اهمیت را دارد وجود یک شی در تصویر است، نه محل دقیق قرارگیری آن در تصویر. اما در این پروژه، محل دقیق قرارگیری شی در تصویر برای ما اهمیت دارد. با این حال، داشتن چندین لایه max-pooling تأثیر منفی بر عملکرد نخواهد داشت.
- لایههای batch normalization به آموزش (همگرایی) سریعتر مدل کمک میکنند. در برخی از شبکههای عمیق، بدون وجود این لایهها نمیتوان مدل را آموزش داد.
- لایههای dropout به صورت تصادفی گرهها را غیرفعال میکنند و از این طریق مانع بیشبرازش Overfitting مدل میشوند.
پس از بلوکهای کانولوشن، تنسور را مسطح میکنیم تا با لایههای dense سازگار شود. global max-pooling و average max-pooling هم میتوانند تنسور را مسطح کنند اما در این صورت تمامی اطلاعات مکانی از بین میروند. مسطح کردن تنسور در آزمایشات ما بهتر جواب داد، هرچند که در پایان مدلی با پارامترهای بیشتر داشتیم و در نتیجه آموزش این مدت زمان بیشتری طول کشید.
پس از دو لایه پنهان dense که تابع فعالسازی Relu را دارند، لایههای خروجی قرار دارند. فرض کنید میخواهیم مختصات x و y دو جز اصلی را پیشبینی کنیم، برای انجام این کار لایه خروجی باید 4 گره داشته باشد. تصاویر میتوانند وضوحهای متفاوتی داشته باشند، در نتیجه ما مختصات را بین 0 و 1 مقیاسبندی میکنیم و پیش از استفاده، مقیاس آنها را به حالت اولیه افزایش میدهیم.
لایه خروجی تابع فعالسازی ندارد. هرچند متغیرهای هدف بین 0 و 1 هستند اما عدم وجود تابع فعالسازی در لایه خروجی برای ما بهتر از استفاده از سیگموید بود.
در مقابل خلاصه کاملی از معماری مدلی از Keras که از آن استفاده کردیم، ارائه شده است:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 126, 126, 64) 2368 _________________________________________________________________ conv2d_2 (Conv2D) (None, 124, 124, 64) 36928 _________________________________________________________________ conv2d_3 (Conv2D) (None, 122, 122, 64) 36928 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 61, 61, 64) 0 _________________________________________________________________ batch_normalization_1 (Batch (None, 61, 61, 64) 256 _________________________________________________________________ dropout_1 (Dropout) (None, 61, 61, 64) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 59, 59, 128) 73856 _________________________________________________________________ conv2d_5 (Conv2D) (None, 57, 57, 128) 147584 _________________________________________________________________ conv2d_6 (Conv2D) (None, 55, 55, 128) 147584 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 27, 27, 128) 0 _________________________________________________________________ batch_normalization_2 (Batch (None, 27, 27, 128) 512 _________________________________________________________________ dropout_2 (Dropout) (None, 27, 27, 128) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 93312) 0 _________________________________________________________________ dense_1 (Dense) (None, 256) 23888128 _________________________________________________________________ batch_normalization_3 (Batch (None, 256) 1024 _________________________________________________________________ dropout_3 (Dropout) (None, 256) 0 _________________________________________________________________ dense_2 (Dense) (None, 256) 65792 _________________________________________________________________ batch_normalization_4 (Batch (None, 256) 1024 _________________________________________________________________ dropout_4 (Dropout) (None, 256) 0 _________________________________________________________________ dense_3 (Dense) (None, 4) 1028 ================================================================= Total params: 24,403,012 Trainable params: 24,401,604 Non-trainable params: 1,408 ___________________________
سوالی که ممکن است برای شما پیش بیاید این است که چرا 3 لایه کانولوشن؟ یا چرا 2 بلوک کانولوشنی؟ در جستوجو برای یک ابرپارامتر، این اعداد را به عنوان ابرپارامتر قرار دادیم. با استفاده از پارامترهایی همچون تعداد لایههای dense، سطح dropout، batch normalization و تعداد فیلترهای کانولوشن جستجویی تصادفی انجام دادیم تا ترکیب بهینه ابرپارمترها را پیدا کنیم.
سوال دیگری که ممکن است برای شما پیش بیاید این است که چرا به جای جستوجوی شبکهای، جستوجوی تصادفی انجام دادیم. این کار ممکن است کمی دور از انتظار باشد اما در عمل منجر به کاهش هزینهها میشود. برای کسب اطلاعات بیشتر این مقاله را که حول موضوع تنظیم ابرپارامترها است مطالعه کنید.
ما برای آموزش از بهینهساز Adam با نرخ یادگیری 0.005 استفاده کردیم. اگر زیان اعتبارسنجی Validation loss برای چندین مرحله بهبود پیدا نکند، نرخ یادگیری به صورت خودکار کاهش پیدا میکند.
ما از خطای میانگین مربعات Mean Square Error (MSE) به عنوان تابع زیان استفاده کردیم. در نتیجه خطاهای بزرگ نسبتاً بیشتر از خطاهای کوچک پاداش منفی دریافت میکنند.
آموزش و عملکرد
نمودار مقابل نشاندهنده زیان (خطا) پس از 50 مرحله آموزش است:
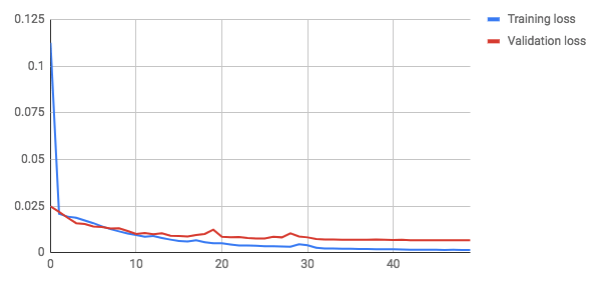
پس از 8 مرحله، زیان اعتبارسنجی بیشتر از زیان آموزش میشود. زیان اعتبارسنجی تا پایان آموزش کاهش خواهد یافت و در نتیجه مدل بیشبرازش نخواهد شد.
آخرین زیان (MSE) در مجموعه آموزشی 0.0064 بود. توضیح و تفسیر MSE ممکن است کمی دشوار باشد. توضیح خطای میانگین متوسط Mean Average Error (MAE) برای انسانها آسانتر است.
- MAE برابر 0017 است؛ به عبارت دیگر، پیشبینیها به طور متوسط 1.7 درصد صحیح نیستند.
در مقابل چندین مجموعه آزمایشی را مشاهده میکنید. دایرههای سفید اجزای اصلی مورد نظر را نشان میدهند و دایرههای توپر پیشبینیهای ما را نشان میدهند. در بسیاری موارد بسیار به هم نزدیک هستند ( با هم همپوشانی دارند).

استقرار
عملکرد مدل به اندازهای خوب هست که ارزش محصول را افزایش دهد. در حال حاضر در هنگام بارگذاری تصاویر جدید از گلها، از اجزای اصلی برای تنظیم مختصات استفاده میشود. در بسیاری از موارد نیازی نیست مختصات را به صورت دستی تنظیم کنیم.
این مدل از طریق یک API ارائه میشود و در یک کانتینتر docker قرار گرفته است. این کانتینر به وسیله پایپلاینهای bitbucket ساخته شده است. علاوه بر این، وزنهای آموزش دیده شده در image داکر قرار دارند. به دلیل اینکه نمیخواهیم فایلهای بزرگی در Git قرار داشته باشد، از Git LFS برای ذخیره آنها استفاده میکنیم.
ارتقای عملکرد مدل
برای بهبود عملکرد مدل به روشهای دیگری نیز رسیدیم که در این پروژه نتوانستیم آنها را اجرا کنیم:
- در حال حاضر یک مدل هر دو جز اصلی را تشخیص میدهد. به عقیده ما اگر برای هر جز یک مدل جداگانه آموزش دهیم، عملکرد مدل بهتر خواهد بود. مزیت دیگری که این کار برای شما دارد این است که میتوانید در آینده بدون نیاز به آموزش مجدد کل مدل، اجزای بیشتری اضافه کنید.
- روش دیگر این است که زاویه عکسبرداری را هم در نظر بگیرید. برای مثال، میتوانید زاویه عکسبرداری را به عنوان ورودی به لایههای dense بدهید. زوایه عکسبردای میتواند ماهیت مسئله را تغییر دهد و در نتیجه ارائه چنین اطلاعاتی میتواند به شبکه کمک کند. علاوه بر این، آموزش یک شبکه جداگانه برای هر زاویه مفید خواهد بود.
مراحل آتی
مرحله پس پردازش علاوه بر تنظیم اجزای اصلی، مراحل دیگری را نیز شامل میشود. برای نمونه میتوان به مرحله تنظیم رنگ ساقه اشاره کرد. مدل 3D ساقههایی مصنوعی رسم میکند که رنگ آنها با رنگ ساقههای درون تصویر مطابقت دارد.
نتیجهگیری
در این پژوهش ثابت کردیم میتوان از CNNها در تشخیص اجزای اصلی در تصاویر گلها استفاده کرد. متد بهکار رفته در این پروژه را میتوان در حوزههای دیگر از جمله عکاسی صنعتی و تبلیغاتی استفاده کرد.