

الگوریتمهای یادگیری تقویتی و مقدمهای بر انواع آن
 تیم تحریریه
تیم تحریریه- ۶ آذر ۱۴۰۰
یادگیری تقویتی Reinforcement Learning یکی از روشهای یادگیری ماشین است که در آن، عامل یادگیری پس از ارزیابی هر اقدام عامل ، پاداشی (همراه با تاخیر) Delayed reward به او داده میشود. درگذشته، این روش اغلب در بازیها (از جمله بازیهای آتاری و ماریو) بهکار گرفته میشد و عملکرد آن در سطح انسان و حتی گاهی فراتر از توانایی ما بود. اما در سالهای اخیر، این الگوریتمهای یادگیری تقویتی درنتیجه ادغام با شبکههای عصبی تکامل پیدا کرده و حال قادر است اعمال پیچیدهتری از جمله حل کردن مسائل را نیز انجام دهد.
الگوریتمهای یادگیری تقویتی بسیار متنوع هستند، اما این الگوریتمها هیچگاه بهطور جامع بررسی و مقایسه نشدهاند. زمانی که قصد داشتم از الگوریتمهای یادگیری تقویتی در پروژه خود استفاده کنم، همین مسئله موجب شد ندانم کدام الگوریتم را باید برای چه فرآیندی بهکار بگیرم. در این مقاله سعی بر این است که بهطور خلاصه سازوکار یادگیری تقویتی را بررسی کرده و تعدادی از محبوبترین الگوریتمهای این حوزه را معرفی نماییم.
یادگیری تقویتی 101
سازوکار یادگیری تقویتی متشکل از دو عنصر عامل تصمیمگیرنده و محیط است.
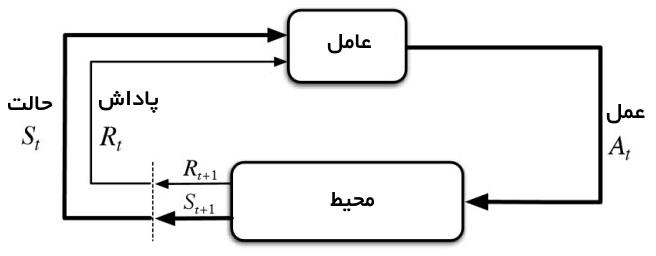
در اینجا محیط، معرف شیءای است که عامل تصمیمگیرنده عملی بر روی آن انجام میدهد (برای مثال، خود بازی در بازی آتاری یک محیط است). این عامل تصمیمگیرنده درواقع همان الگوریتم یادگیری تقویتی است. در ابتدا محیط یک وضعیت state
را برای عامل ایجاد میکند تا عامل براساس دانش خود نسبت به آن عکسالعمل نشان دهد. سپس محیط، وضعیت بعدی و پاداش اقدام قبلی را با هم برای عامل میفرستد. عامل تصمیمگیرنده نیز دانش خود را بر پایه پاداشی که در ازای اقدام پیشین خود دریافت کرده، بهروزرسانی میکند. این چرخه ادامه پیدا میکند تا محیط وضعیت نهایی را برای عامل بفرستد و چرخه را خاتمه دهد.
اغلب الگوریتمهای یادگیری تقویتی از این الگو پیروی میکنند. در قسمت بعدی، واژهها و اصطلاحات پرکاربرد در حوزه یادگیری تقویتی را بهطور خلاصه شرح میدهیم تا درک مباحث بعدی تسهیل شود.
[irp posts=”11464″]تعاریف یادگیری تقویتی
- اقدام (Action|A): شامل تمامی واکنشهای محتملی است که عامل تصمیمگیرنده ممکن است در مواجهه با وضعیت ایجاد شده، از خود نشان دهد.
- وضعیت (State|S): وضعیتی که عامل در هرلحظه با آن مواجه است و محیط آن را ایجاد کرده است.
- پاداش (Reward|R): بازخورد فوری که پس از ارزیابی هر اقدام عامل تصمیمگیرنده، توسط محیط برای آن ارسال میشود.
- سیاست (Policy|π): استراتژی است که عامل تصمیمگیرنده در پاسخ به وضعیت فعلی، برای اقدام بعدی خود درنظر میگیرد.
- ارزش (Value|V): پاداش بلند مدت موردانتظار تنزیلشده Discounted expected long-term reward که برخلاف با پاداش کوتاهمدت (R)، بلندمدت میباشد. عبارت است از سود موردانتظار در بلندمدت که ناشی از وضعیت کنونی s تحت سیاست π است.
- Q-value یا اقدام-ارزش (Q): مفهوم Q-value بسیار شبیه به مفهوم ارزش (V) است. اما در Q-value یک پارامتر بیشتر وجود دارد. این پارامتر اضافه همان اقدام a میباشد. Q(s,a) عبارت است از سود بلندمدت ناشی از اقدام a تحت سیاستPolicy
π در وضعیت کنونی s.
الگوریتمهای بدون مدل دربرابر الگوریتمهای مبتی بر مدل
مدل یک شبیهسازی از پویایی محیط است. یعنی اینکه مدل، تابع احتمال انتقال T(s1|(s0, a)) (یعنی احتمال انتقال وضعیت s1 درصورتی که در وضعیت قبلی یا s0، اقدام a انتخاب شده باشد.) را یاد میگیرد. اگر یادگیری تابع انتقال احتمال موفقیتآمیز باشد، عامل تصمیمگیرنده میتواند احتمال رخ دادن یک وضعیت مشخص را براساس وضعیت و اقدام فعلی محاسبه کند. اما با افزایش تعداد وضعیتها و اقدامها (S*S*A، در یک ساختار جدولی)، الگوریتمهای مبتنی بر مدل کارآمدی خود را از دست میدهند.
از سوی دیگر، الگوریتمهای بدون مدل درواقع مبتنی بر روش آزمون و خطا Trial and Error هستند و براساس نتیجه آن، دانش خود را بهروزرسانی میکنند. درنتیجه، فضایی برای ذخیره ترکیبات احتمالی وضعیتها و اقدامها نیاز نخواهند داشت. الگوریتمهایی که در قسمت بعدی معرفی میشوند، همگی در این دسته قرار دارند.
روش On-policy و روش Off-policy
در روش On-policy، عامل تصمیمگیرنده ارزش را براساس اقدام a که ناشی از سیاست فعلی است، یاد میگیرد. اما در روش دیگر یعنی روش Off-policy فرایند یادگیری به این صورت است که عامل، ارزش را از اقدام a* (بهترین اقدام موجود) که نتیجه یک سیاست دیگر میباشد، میآموزد. این سیاست در الگوریتم یادگیری Q همان سیاست حریصانه است (درادامه این مقاله بیشتر درباره الگوریتمهای یادگیری Q و SARSA صحبت خواهیم کرد).
[irp posts=”5198″]مروری بر چند الگوریتم
الگوریتم یادگیری Q
الگوریتم Q-Learning یا یادگیری Q یک الگوریتم یادگیری تقویتی از نوع بدون مدل و Off-policy است که برپایه معادله معروف بِلمَن تعریف میشود:
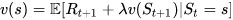
در معادله بالا، E نماد انتظارات و λ ضریب تنزیل Discount factor است. میتوانیم معادله بالا را در فرم تابعی Q-Value به صورت زیر بنویسیم:
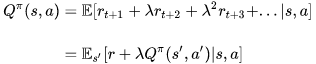
مقدار بهینه Optimal Q-Value Q-value که با نماد نمایش داده میشود را میتوان از فرمول زیر به دست آورد:
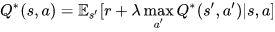
هدف این معادله حداکثرسازی مقدار Q-value است. البته، پیش از پرداختن به روشهای بهینهسازی مقدار Q-value، قصد دارم 2 روش بهروزرسانی ارزش را که رابطه نزدیکی با الگوریتم یادگیری Q دارند، معرفی کنم.
[irp posts=”7290″]تکرار سیاست Policy Iteration
در روش تکرار سیاست، یک حلقه بین ارزیابی سیاست و بهبود آن شکل میگیرد.
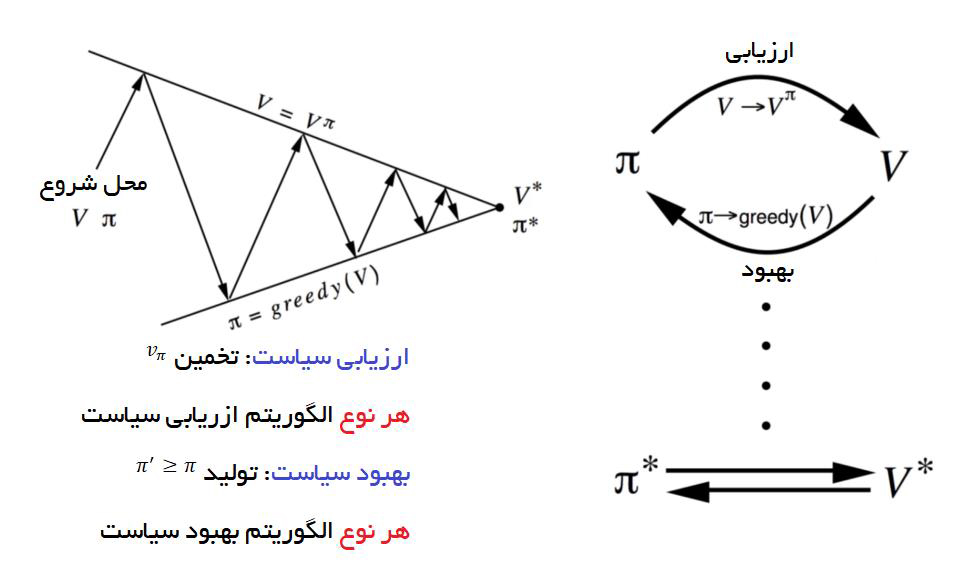
در ارزیابی سیاست، مقدار تابع V را برحسب سیاست حریصانهای که درنتیجهی بهبود سیاست قبلی به دست آمده، تخمین میزنیم. از سوی دیگر، در بهبود سیاست، سیاست فعلی را برحسب اقدامی که مقدار V را در هر وضعیت حداکثر کند، بهروزرسانی میکنیم. بهروزرسانی معادلات برپایه معادله بلمن انجام میگیرد و تکرار حلقه تا زمانی که این معادلات همگرا
Converge شوند، ادامه مییابد.

تکرار ارزش
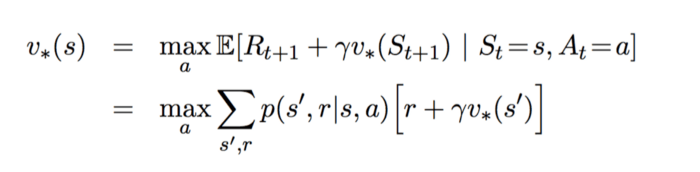
روش تکرار ارزش تنها یک بخش دارد. در این روش، تابع ارزش براساس مقدار بهینه معادله بلمن بهروزرسانی میشود.
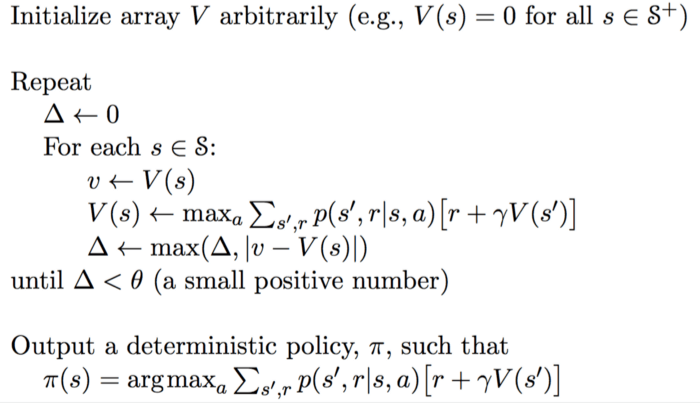
وقتی تکرار به همگرایی برسد، یک سیاست بهینه برای همه وضعیتها مستقیماً توسط تابع argument-max ارائه داده میشود.
بهخاطر داشته باشید که برای استفاده از این دو روش باید احتمال انتقال Transition Probability p را بشناسید. بنابراین، میتوان گفت که این روشها، الگوریتمهای مبتنی بر مدل هستند. اما همانطور که پیشتر نیز ذکر کردیم، الگوریتمهای مبتنی بر مدل با مشکل مقیاسپذیری مواجه هستند. سوالی که در اینجا پیش میآید این است که الگوریتم یادگیری Q چطور این مشکل را حل کرده است؟
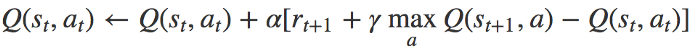
در این معادله، α نماد نرخ یادگیری Learning rate (یعنی سرعت ما در حرکت به سوی هدف اصلی) است. ایده اصلی یادگیری Q بهشدت به روش تکرار ارزش متکی است. اما معادله بهروزشده با فرمول بالا جایگزین میشود و درنتیجه، دیگر نیاز نیست نگران احتمال انتقال باشیم.

بخاطر داشته باشید که اقدام بعدی یعنی ، با هدف حداکثر کردن وضعیت بعدی Q-value انتخاب شده است، نه براساس سیاست مربوطه. درنتیجه یادگیری Q در دسته روشهای Off-policy قرار میگیرد.
الگوریتم «وضعیت-اقدام-پاداش-وضعیت-اقدام» یا SARSA
الگوریتم SARSA (که سرواژه عبارت State-Action-Reward-State-Action است) شباهت زیادی با الگوریتم یادگیری Q دارد. تفاوت کلیدی این دو الگوریتم در این است که SARSA برخلاف الگوریتم یادگیری Q، در دسته الگوریتمهای On-Policy قرار میگیرد. بنابراین، الگوریتم SARSA مقدار Q-value را با توجه به اقدامی که ناشی از سیاست فعلی است محاسبه میکند نه اقدام ناشی از سیاست حریصانه.
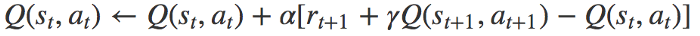
اقدام اقدامی است که در وضعیت بعدی یعنی تحت سیاست فعلی انجام خواهد گرفت.

ممکن است در نمونه کد بالا متوجه شده باشید که هر دو اقدام اجرا شده از سیاست فعلی پیروی میکنند. اما در الگوریتم یادگیری Q، تا زمانی که اقدام بعدی بتواند مقدار Q-value برای وضعیت بعدی را حداکثر سازد، هیچ قیدی برای آن تعریف نمیشود. بنابراین همانطور که گفته شد، الگوریتم SARSA از نوع الگوریتمهای On-policy است.
[irp posts=”11877″]شبکه عمیق Q یا DQN
الگوریتم یادگیری Q الگوریتم قدرتمندی است، اما قابلیت تعمیمپذیری Generalization ندارد و همین مسئله را میتوان بزرگترین نقطهضعف آن دانست. اگر الگوریتم یادگیری Q را بهروزرسانی اعداد موجود در یک آرایه دو بعدی (شامل: فضای اقدام×فضای وضعیت) درنظر بگیرید، متوجه شباهت آن با برنامهنویسی پویا Dynamic Programming خواهید شد. این موضوع برای ما روشن میسازد که وقتی عامل تصمیمگیرنده در الگوریتم یادگیری Q با وضعیتی کاملاً جدید روبهرو شود، هیچ راهی برای شناسایی و انتخاب اقدام مناسب نخواهد داشت. به عبارت دیگر، عامل تصمیمگیرنده الگوریتم یادگیری Q توانایی تخمین ارزش وضعیتهای ناشناخته را ندارد. برای حل این مشکل، شبکه DQN آرایه دو بعدی را حذف و شبکه عصبی را جایگزین آن میکند.
شبکه DQN به کمک یک شبکه عصبی، تابع Q-value را تخمین میزند. وضعیت فعلی به عنوان ورودی به این شبکه داده میشود، سپس مقدار Q-value متناظر با هر اقدام به عنوان خروجی از شبکه دریافت خواهد شد.
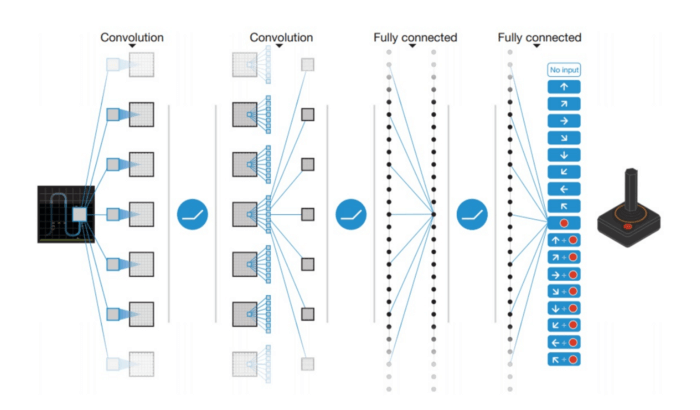
شرکت دیپ مایند DeepMind در سال 2013، شبکه DQN را همانطور که در تصویر بالا ملاحظه میکنید، در بازی آتاری بهکار گرفت. ورودی که به این شبکه داده میشد یک تصویر خام از وضعیت جاری بازی بود. این ورودی از چندین لایه مختلف از جمله لایههای پیچشی و تماماً متصل عبور میکند و خروجی نهایی شامل مقادیر Q-valueهای مربوط به تمام اقدامات احتمالی عامل تصمیمگیرنده است.
حال سؤال اصلی این است که: چطور میتوان این شبکه را آموزش داد؟
پاسخ این است که ما شبکه را براساس معادله بهروزرسانی الگوریتم یادگیری Q آموزش میدهیم. اگر بخاطر داشته باشید، مقدار Q-value هدف برای الگوریتم یادگیری Q از فرمول زیر به دست میآمد:

نماد ϕ معادل وضعیت s است. نماد ? نیز بیانگر تعدادی از پارامترهای شبکه عصبی است که خارج از بحث ما هستند. بنابراین، تابع زیان شبکه به صورت مربعات خطای Q-value هدف و Q-value ای که شبکه به عنوان خروجی به ما میدهد، تعریف میشود.

دو تکنیک دیگر نیز برای آموزش شبکه DNQ ضروری است:
- تکرار تجریه Experience Replay: در سازوکار متداول یادگیری تقویتی، نمونههای آموزشی همبستگی بالایی دارند و ازنظر مقدار داده موردنیاز نیز کارآمد نیستند. به همین دلیل، سخت است که مدل به مرحله همگرایی برسد. یک راه برای حل مسئله توزیع نمونه، بهکارگیری تکنیک تکرار تجربه است. در این روش، تابع انتقال نمونهها ذخیره میشود و سپس الگوریتم این تجربیات را از محلی به نام «مجموعه انتقال» به طور تصادفی انتخاب میکند تا دانش خود را براساس آن بهروزرسانی نماید.
- شبکه هدف مجزا Separate Target Network: ساختار شبکه هدف Q مشابه ساختار شبکهای است که ارزش را تخمین میزند. همانطور در نمونه کد بالا ملاحظه کردید، در به تعداد C مرحله، شبکه هدف جدیدی تعریف میشود تا از شدت نوسانات کاسته شود و فرایند آموزش ثبات بیشتری داشته باشد.
الگوریتم DDPG
اگرچه شبکه DQN در مسائلی که ابعاد زیادی دارند (همچون بازی آتاری)، بسیار موفق عمل کرده است، اما فضای اقدام در این شبکه گسسته Discrete میباشد و از آنجا که بسیاری از مسائل موردعلاقه و حائز اهمیت برای ما از جمله مسائل مربوط به کنترل فیزیکی، دارای فضای اقدام پیوسته هستند، گسسته بودن فضا در شبکه DQN یک نقطهضعف بهشمار میآید.
با تبدیل یک فضای اقدام پیوسته به یک فضای گسسته به صورت دقیق و جزئی، یک فضای اقدام بسیار گسترده به دست میآید. برای مثال، فرض کنید درجه آزادی سیستم تصادفی 10 باشد. بهازای هر درجه، باید فضا را به 4 قسمت تقسیم کنیم. به این ترتیب، در آخر 1048576=4¹⁰ عدد اقدام خواهیم داشت. سخت است که در چنین فضای اقدام بزرگی به همگرایی برسید.
الگوریتم DDPG مبتنی بر معماری عملگر منتقد actor-critic architecture است. این معماری دو عنصر اصلی دارد: عملگر و منتقد. عنصر عملگر، تنظیم پارامتر ? با تابع سیاست Policy function را برعهده دارد، به این ترتیب، عملگر تصمیم میگیرد که بهترین اقدام ممکن برای هر وضعیت چیست.

وظیفه منتقد نیز ارزیابی تابع سیاستی است که عملگر براساس تابع خطای تفاوت موقتی temporal difference (TD) error تخمین زده است.

در این تابع حرف v کوچک نمایانگر سیاستی است که عملگر برمیگزیند. این فرمول کمی آشنا بهنظر نمیرسد؟ بله، درست است. این فرمول دقیقاً مشابه معادله بهروزرسانی الگوریتم یادگیری Q است. یادگیری تفاوت زمانی روشی است که الگوریتم به کمک آن میتواند نحوه پیشبینی یک تابع ارزش را بر پایه ارزشهای آتی یک وضعیت معین بیاموزد. الگوریتم یادگیری Q نوعی خاصی از یادگیری تفاوت زمانی در حوزه یادگیری Q-value است.

الگوریتم DDPG تکنیکهای تکرار تجربه و شبکه هدف مجزا در شبکه DQN را نیز بهکارمیگیرد. اما یکی از مشکلات DDPG این است که به ندرت اقدامات را جستوجو میکند. یک راهحل برای این مشکل، ایجاد اختلال Adding noise در فضای پارامترها یا فضای اقدام میباشد.

البته محققین OpenAI در مقاله خود ادعا کردهاند که ایجاد اختلال در فضای پارامترها بهتر از ایجاد اختلال در فضای اقدام است. یکی از رایجترین و پرکاربردترین اختلالات در این زمینه فرایند تصادفی اورنستین-یولنبک Ornstein-Uhlenbeck Random Process نام دارد.

سخن نهایی
در این مقاله به برخی از مفاهیم پایهای و ساده الگوریتمهای یادگیری Q، SARSA، DQN و DDPG پرداختیم. در مقاله بعدی و در ادامه همین بحث، به بررسی پیشرفتهترین الگوریتمهای یادگیری تقویتی از جمله NAF، A3C و غیره خواهیم پرداخت و در آخر نیز تمامی الگوریتمهای مذکور را با یکدیگر مقایسه خواهیم کرد. اگر ابهام یا سؤالی درخصوص این مقاله دارید، آن را در بخش نظرات با ما به اشتراک بگذارید.





