
استخدام یادگیری عمیق: ده مفهوم اساسی برای موفقیت در مصاحبههای کاری
 تیم تحریریه
تیم تحریریه- ۲۴ خرداد ۱۴۰۰
مباحث یادگیری عمیق Deep learning و شبکههای عصبی Neural networks میتوانند گیجکننده باشند. اما باید توجه داشته باشید که برای استخدام یادگیری عمیق در مصاحبههای کاری علوم داده، عمدهی سؤالات از چند مبحث خاص مطرح میشوند. بعد از بررسی صدها نمونه از این مصاحبهها، به 10 مفهوم از یادگیری عمیق رسیدم که اغلب موردتوجه مصاحبهگران قرار میگیرد.
در این نوشتار، این 10 مفهوم را با هم مرور میکنیم:
-
توابع فعالسازی
در صورتی که شناختی از شبکه های عصبی و ساختار آنها ندارید پیشنهاد میکنم ابتدا این مقاله را مطالعه کنید تا مشکلی برای استخدام یادگیری عمیق از این بابت نداشته باشید.
بعد از آشنایی مختصر با نورونها/گرهها Neurons/nodes ، درمییابید تابع فعالسازی Activation function مثل کلیدی است که تعیین میکند یک نورون خاص باید فعال شود یا خیر.
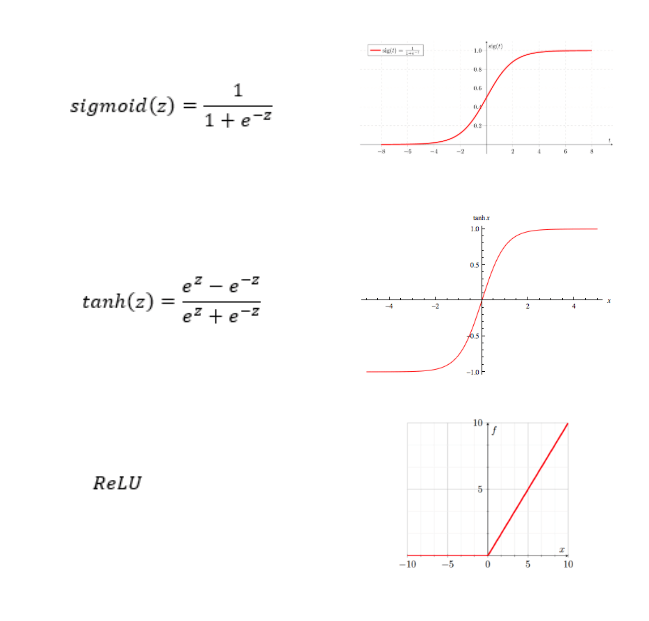
توابع فعالساز انواع مختلفی دارند، اما از محبوبترین آنها میتوان به تابع یکسوساز خطیRectified Linear Unit Function یا ReLU اشاره کرد. این تابع از توابع سیگموئید Sigmoid و تانژانت هذلولوی tanh شناختهشدهتر است، زیرا گرادیان کاهشیGradient descent را با سرعت بیشتری اجرا میکند. با توجه به تصویر بالا، مشاهده میکنید که وقتی x (یا z) خیلی بزرگ باشد، شیب به شدت کاهش مییابد و در نتیجه سرعت کاهش گرادیان به میزان چشمگیری آهسته میشود. اما این نکته برای تابع ReLU صدق نمیکند.
-
تابع هزینه
تابع هزینهCost function یک شبکهی عصبی مانند توابع هزینهای است که در سایر مدلهای یادگیری ماشین به کار میروند و برای استخدام یادگیری عمیق آشنایی با آنها ضروری است. تابع هزینه معیاری برای ارزیابی عملکرد مدل، از طریق سنجش شباهت مقادیر پیشبینیشده با مقادیر واقعی است. تابع هزینه با کیفیت مدل رابطهی عکس دارد؛ یعنی هر چه مدل بهتر باشد، تابع هزینه پایینتر خواهد بود و بالعکس.
تابع هزینه را میتوان بهینهسازی کرد.وزنها و پارامترهای بهینهی مدل، با حداقل ساختن تابع هزینه قابل دسترسی هستند.
از توابع هزینهی متداول میتوان به تابع درجه دومQuadratic cost، تابع آنتروپی متقاطعCross-entropy، تابع هزینه نمایی Exponential cost، فاصله هلینگر Hellinger distance و واگرایی کولبک-لیبلرKullback-Leibler divergence اشاره کرد.
-
پسانتشار
موردی که برای استخدام یادگیری عمیق باید بدانید این است که پسانتشار Backpropagation ارتباط نزدیکی با تابع هزینه دارد. پسانتشار الگوریتمی است که برای محاسبهی گرادیان تابع هزینه به کار میرود. این الگوریتم با توجه به سرعت و کارآیی بالایی که در مقایسه با سایر رویکردها دارد، از محبوبیت و کاربرد بالایی برخوردار شده است.
نام پسانتشار برگرفته از این واقعیت است که محاسبهی گرادیان از آخرین لایهی وزنها آغاز شده و به سوی گرادیانهای اولین لایه، یعنی به سمت عقب، حرکت میکند. بنابراین خطای لایهی k وابسته به لایهی بعدی یعنی k+1 است.
نحوهی کار الگوریتم پسانتشار را میتوان در این گامها خلاصه کرد:
- انتشار رو به جلو را برای هر جفت ورودی-خروجی محاسبه میکند؛
- انتشار رو به عقب هر جفت را محاسبه میکند؛
- گرادیانها را ترکیب میکند؛
- وزنها را بر اساس نرخ یادگیری و گرادیان کلی، به روزرسانی میکند.
این مقاله به خوبی مبحث پسانتشار را پوشش داده و برای مبحث استخدام یادگیری عمیق مناسب است.
-
شبکههای عصبی پیچشی
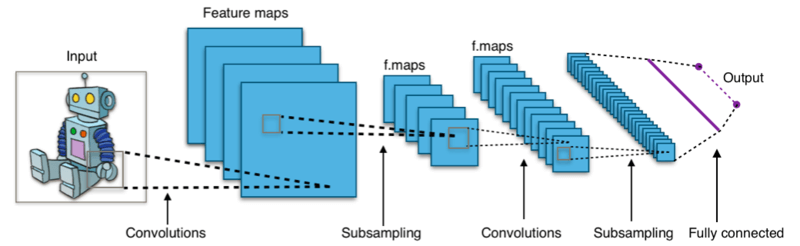
شبکهی عصبی پیچشیConvolutional Neural Networks (CNN) نوعی شبکهی عصبی است که به ویژگیهای مختلف ورودی (که اغلب یک تصویر و یا بخشی از یک متن میباشد.) مقادیر اهمیت اختصاص داده و سپس یک خروجی تولید میکند. آنچه باعث مزیت CNNها نسبت به شبکههای عصبی پیشخورFeedforward neural networks میشود این است که وابستگیهای فضاییSpatial dependencies (پیکسلی) سراسر تصویر، و در نتیجه ترکیب تصویر را بهتر درک میکند.
CNNها در واقع یک عملیات ریاضیاتی به نام کانولوشنConvolution اجرا میکنند. طبق تعریف ویکیپدیا، کانولوشن یک عملیات ریاضیاتی است که روی دو تابع انجام میشود و خروجی آن، تابع سومی است که نشان میدهد شکل یکی از آن توابع چطور توسط دیگری تغییر میکند. پس CNN به جای ضربهای ماتریسی معمولی، حداقل در یکی از لایههای خود، از عملیات کانولوشن استفاده میکند.
-
شبکههای عصبی بازگشتی
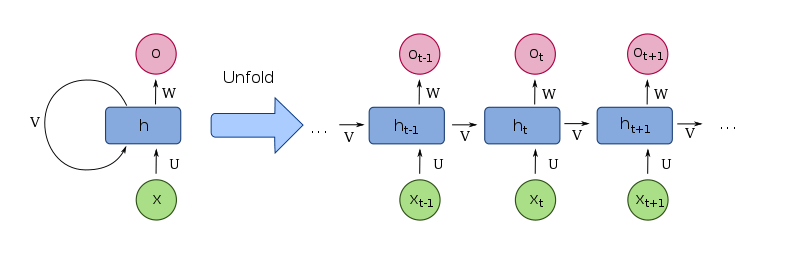
اگر مشتاق استخدام یادگیری عمیق هستید باید بدانید شبکههای عصبی بازگشتیRecurrent Neural Networks (RNN) نوع دیگری از شبکههای عصبی هستند که به خاطر قابلیت پردازش دادههایی با اندازههای گوناگون، روی دادههای توالیSequential data عملکرد بسیار خوبی از خود نشان میدهند. RNNها علاوه بر ورودیهای فعلی، ورودیهای قبلی را هم درنظر میگیرند؛ بنابراین یک ورودی خاص میتواند بر اساس ورودیهای قبلی، خروجیهای متفاوتی تولید کند.
از نظر فنی، RNNها گروهی از شبکههای عصبی هستند که اتصالات بین گرههایشان، علاوه بر یک توالی زمانی، یک گراف جهتدارDigraph ایجاد میکند و بدین ترتیب آنها را قادر میسازد از حافظهی داخلی خود برای پردازش توالیهایی با طول متغیر استفاده کنند.
به بیان خلاصه، RNNها نوعی از شبکههای عصبی هستند که اساساً روی دادههای توالی یا سریهای زمانی به کار میروند.
-
شبکههای حافظهی کوتاهمدت بلند (LSTM)
شبکههای LSTMLong Short-Term Memory نوعی از شبکه های عصبی بازگشتی هستند که برای جبران یکی از نقاط ضعف RNNها یعنی حافظهی کوتاهمدت، ساخته شدهاند و برای استخدام یادگیری عمیق باید با آن آشنا باشید.
به بیان دقیقتر، اگر یک توالی طولانی داشته باشیم (برای مثال رشتهای با بیشتر از 5-10 گام)، RNNها اطلاعات مربوط به گامهای اول را فراموش خواهند کرد. به عنوان مثال، اگر یک پارگراف را به RNN تغذیه کنیم، احتمال نادیده گرفته شدن اطلاعات ابتدای پارگراف وجود دارد.
LSTMها برای حل این مشکل به وجود آمدند.
در این مطلب میتوانید اطلاعات بیشتری در مورد LSTMها به دست آورید.
-
تعریف وزن
هدف از تعریف وزنWeight initialization اطمینان حاصل کردن از این است که شبکهی عصبی به یک راهکار بیهوده همگرایی نخواهد داشت.
اگر مقدار تعریفشده برای همهی وزنها یکی باشد (برای مثال همه 0 باشند)، همهی واحدها سیگنالی دقیقاً یکسان دریافت میکنند؛ در نتیجه، لایهها طوری رفتار میکنند که فقط یک سلول واحد وجود دارد.
بنابراین، باید به صورت تصادفی مقادیر نزدیک صفر، اما نه خود صفر، را به وزنها اختصاص دهیم. الگوریتم بهینهسازی تصادفی که برای آموزش مدل به کار میرود از این قاعده استثناست.
-
مقایسه گرادیان کاهشی تصادفی با گرادیان کاهشی دستهای
افراد مایل به استخدام یادگیری عمیق باید بدانند که گرادیان کاهشی دستهای و گرادیان کاهشی تصادفی Stochastic Gradient descent دو روش متفاوت برای محاسبهی گرادیان هستند.
گرادیان کاهشی دستهای، گرادیان را بر اساس همهی دیتاست محاسبه میکند. این روش در دیتاستهای بزرگ، سرعت پایینی خواهد داشت، اما برای هموارسازی یا واگرا شدن منیفلد خطا بهتر است.
در روش گرادیان کاهشی تصادفی، گرادیان در هر بازهی زمانی، بر اساس یک نمونهی آموزشی واحد محاسبه میشود. به همین خاطر، این روش از نظر محاسباتی سریعتر و کمهزینهتر است. با این حال، در این روش، بعد از رسیدن به کمینهی سراسری، جستجو در اطراف همچنان ادامه میباید. نتیجهی این روش قابلقبول است، اما بهینه نیست.
-
هایپرپارامترها
هایپرپارامترها متغیرهایی هستند که ساختار شبکه را تنظیم میکنند و بر نحوهی آموزش آن نظارت دارند. از جمله هایپرپارامترهای متداول میتوان به این موارد اشاره کرد:
- پارامترهای معماری مدل همچون تعداد لایهها، تعداد واحدهای نهان Hidden units، و …؛
- نرخ یادگیری Learning rate (آلفا)؛
- تعریف وزنهای شبکه؛
- تعداد دورهها (دوره به معنی یک چرخهی کامل در دیتاست آموزشی است)
- اندازهی بستهداده batch
-
نرخ یادگیری
نرخ یادگیری یکی از هایپرپارامترهای شبکههای عصبی است که بر اساس خطای برآورد شده در هربار به روزرسانی وزنها، میزان انطباق مدل را تعیین میکند.
اگر نرخ یادگیری خیلی پایین باشد، سرعت آموزش مدل آهسته خواهد بود؛ زیرا در هر تکرار، وزنهای مدل به حداقل میزان ممکن به روزرسانی خواهند شد. به همین دلیل، قبل از رسیدن به کمینه، باید بهروزرسانیهای زیادی انجام شود.
اگر نرخ یادگیری خیلی بالا باشد، توابع زیان رفتاری واگرا خواهند داشت. زیرا در به روزرسانی وزنها، تغییراتی چشمگیر رخ میدهد. این رفتار ممکن است آنقدر شدید باشد که تابع هیچگاه همگرا نشود.





