
مسئله تشخیص شیء و بررسی آن به منظور یادگیری پایتورچ
 تیم تحریریه
تیم تحریریه- ۱۹ اردیبهشت ۱۴۰۱
از آنجایی که بهترین راه برای یادگیری هر تکنولوژی جدید استفاده از آن در حل یک مسئله ساده است، برای یادگیری PyTorch از آن در حل یک مسئله ساده استفاده میکنیم. استفاده از یک شبکه عصبی از پیش آموزش دیده در مسئله تشخیص شیء. در این نوشتار، علاوه بر توضیح این پروژه، با کتابخانهی PyTorch بیشتر آشنا شده و مفهوم یادگیری انتقالی را نیز با هم مرور خواهیم کرد.
Keras از کتابخانههای محبوب یادگیری ماشین است که API سادهای برای ساخت شبکههای عصبی دارد. اخیراً قابلیت جدیدی به PyTorch اضافه شده که آن را در کانون توجهات قرار داده است. به کارگیری این کتابخانه توسط پژوهشگران و حضور آن در fast.ai حاکی از اهمیت این پدیدهی نوظهور میباشند.
در حال حاضر، تعیین برترین و پرکاربردترین کتابخانهی یادگیری عمیق امری غیرممکن به نظر میرسد؛ به همین دلیل، برای کسب موفقیت در حوزهی علوم داده، لازم است کار با همهی ابزارهای ضروری را بیاموزید، حتی اگر کار با برخی از آنها، مثل PyTorch، چندان ساده نباشد.
کد کامل این پروژه را میتوانید در این نوتبوک GitHub مشاهده کنید. این پروژه حاصل شرکت من در چالش «بورسیهی PyTorch از مؤسسهی Udacity» است.

یادگیری انتقالی
هدف این است که یک شبکهی عصبی کانولوشنی (CNN) را برای مسئله تشخیص شیء آموزش دهیم تا بتواند اشیاء موجود در تصاویر را شناسایی کند. بدین منظور، از دیتاست Caltech 101 استفاده میکنیم که 101 دسته تصویر دارد؛ بیشتر این دستهها تنها شامل 50 تصویر میشوند. این تعداد داده برای دستیابی به دقت بالا در یادگیری، کافی نیست. به همین دلیل، به جای اینکه یک CNN را از صفر ساخته و آموزش دهیم، به کمک یادگیری انتقالی، از یک مدل از پیش آموزش دیده استفاده میکنیم.
مفهوم کلی یادگیری انتقالی ساده است: مدلی که روی یک دیتاست بزرگ آموزش دیده را میگیریم و دانش آن را به یک شبکهی کوچکتر منتقل میکنیم. برای اجرای مسئله تشخیص شیء با یک CNN، لایههای کانولوشن اولیه را منجمد میکنیم و تنها چند لایهی آخر که پیشبینی انجام میدهند را آموزش میدهیم. در نتیجهی این امر، لایههای پیچشی ویژگیهای عمومی و سطح پایین که در میان همهی تصاویر مشترک هستند (همچون لبهها، الگوها، گرادیانها) را استخراج میکنند و لایههای بعدی، ویژگیهای خاص هر تصویر (مثل چشمها یا چرخ) را تشخیص میدهند.
بدین ترتیب میتوانیم از شبکهای استفاده کنیم که روی دیتاستی بزرگ و غیرمرتبط با مسئله حاضر (اغلب ImageNet) آموزش دیده است. ویژگیهای موجود در این دادهها، کلی و سطح پایین هستند و در بین همهی تصاویر مشترکاند. تصاویر دیتاست Caltech 101 به تصاویر دیتاست ImageNet شباهت دارند؛ به همین دلیل، انتقال دانشی که مدل از روی دیتاست ImageNet میآموزد به مسئله حاضر، دشوار نخواهد بود.
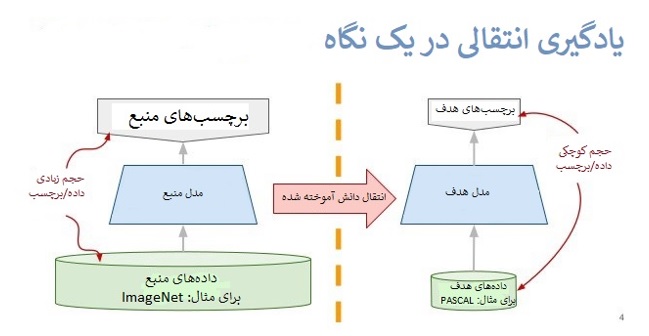
گامهای یادگیری انتقالی برای مسئله تشخیص شیء عبارتاند از:
- بارگذاری CNNای که از پیش روی یک دیتاست بزرگ آموزش دیده است؛
- منجمد کردن پارامترهای (وزنها) لایههای پیچشی پایینتر؛
- افزودن یک کلاسیفایر دلخواه با چند لایه پارامتر قابل آموزش به منظور مدلسازی؛
- آموزش لایههای کلاسیفایر روی دادههای آموزشی موجود؛
- باز آموزش هایپرپارامترها و از انجماد در آوردن لایههای بیشتر تا حد لازم.
کارآمدی یادگیری انتقالی در حوزههای گوناگون اثبات شده است. این روش یک ابزار عالی به شمار میرود که آشنایی با آن برای همهی متخصصان ضروری است. در صورت بروز مشکل در مسائل تشخیص تصویر، معمولاً اولین راهحلی که امتحان میشود، یادگیری انتقالی است.
آمادهسازی دادهها
در همهی مسائل علوم داده، قالببندی صحیح دادهها میتواند نقشی تعیینکننده در شکست یا موفقیت پروژه داشته باشد. دادههای Caltech 101 پاکسازی شده و در فرمت صحیح ذخیره شدهاند.
/datadir
/train
/class1
/class2
.
.
/valid
/class1
/class2
.
.
/test
/class1
/class2
.
.
اگر دیرکتوری دادهها به درستی تعریف شده باشد، اختصاص برچسبهای صحیح به کلاسها در PyTorch کار آسانی خواهد بود. اینجا، دادهها با نسبت 50%، 25% و 25% تقسیم شده و در مجموعههای آموزشی، اعتبارسنجی، و تست قرار گرفتهاند. ساختار دیرکتوریها بدین شکل است:
نمودار پایین، تعداد تصاویر آموزشی را در مقایسه با کلاسها نشان میدهد (نکته: در این نوشتار، اصطلاحات کلاس و گروه به جای یکدیگر به کار میروند):
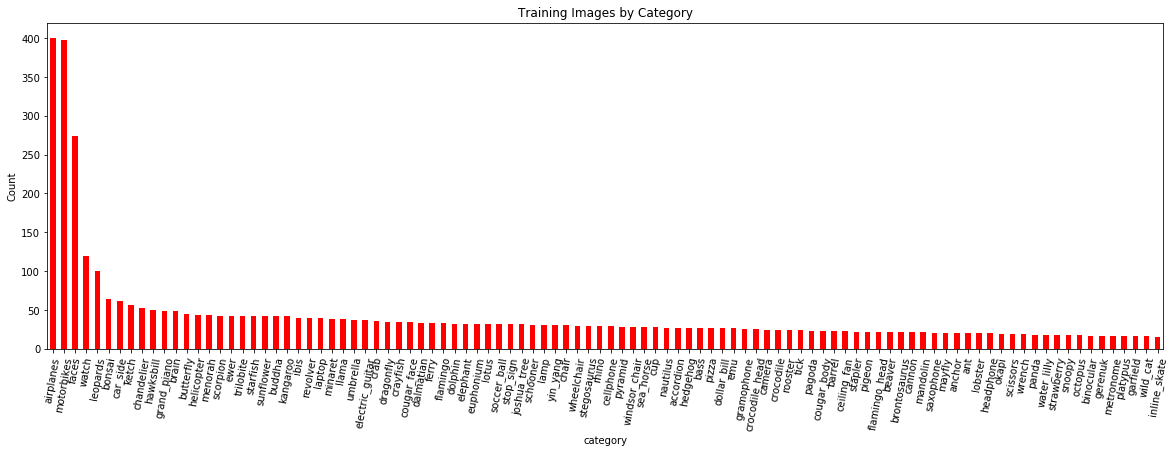
انتظار میرود مدل روی کلاسهایی که تعداد نمونههای بیشتری دارند عملکرد بهتری داشته باشد، زیرا بهتر میتواند بین ویژگیهای این کلاسها و برچسبها ارتباط برقرار کند. برای اینکه تعداد کم نمونههای آموزشی مشکلزا نشود میتوانیم طی آموزش، از تکنیکهای دادهافزایی استفاده کنیم.
در فرآیند اکتشاف داده، به اندازهی توزیع هم باید دقت کرد:
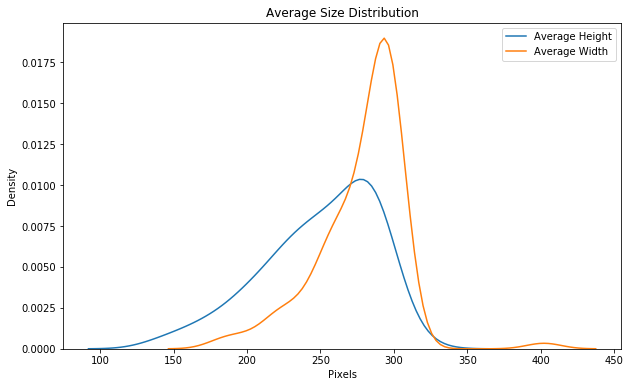
اندازهی تصاویر ورودی ImageNet باید 224×224 باشد؛ به همین دلیل یکی از کارهایی که باید در مرحلهی پیشپردازش انجام دهیم، تغییر اندازهی تصاویر است. تکنیک دادهافزایی هم، در صورت نیاز، در مرحلهی پیشپردازش انجام میشود.
دادهافزایی
هدف از دادهافزایی، افزایش تعداد تصاویر آموزشی به صورت مصنوعی و از طریق اجرای تبدیلات تصادفی روی تصاویر است. برای مثال، میتوانیم به صورت تصادفی یه تصویر را بچرخانیم، برش بدهیم یا حول محور افقی معکوس کنیم. با اجرای دادهافزایی، مدل قادر به رسیدگی به مسئله تشخیص شیء فارغ از جهتگیری آنها خواهد بود. به عبارت دیگر، دادهافزایی باعث میشود مدل نسبت به تبدیلات دادههای ورودی مقاوم باشد.

دادهافزایی معمولاً فقط در مرحلهی آموزش انجام میشود (البته در کتابخانهی fast.ai، دادهافزایی هنگام تست نیز امکانپذیر است). در هر دور که مدل روی همهی تصاویر آموزشی تکرار میشود، یک تبدیل تصادفی متفاوت روی همهی تصاویر آموزشی اجرا میشود. بنابراین، اگر 20 دور آموزشی داشته باشیم، مدل 20 نسخهی تقریباً متفاوت از هر تصویر میبیند. مدل نهایی مسئله تشخیص شیء که به این شیوه به دست میآید، به جای اینکه بازنمایی اشیاء یا اجزای متفرقه در تصویر را بیاموزد، خود اشیاء را فرامیگیرد.
پیشپردازش تصویر
پیشپردازش، مهمترین گام کار با دادههای تصویری است. طی پیشپردازش، به صورت همزمان تصاویر را برای شبکه آماده کرده و دادهافزایی روی مجموعهی آموزشی انجام میدهیم. هر مدلی، ورودیهایی با شرایط خاص را میپذیرد؛ به عنوان مثال، تصاویر ورودی ImageNet باید 224×224 بوده و نرمالسازی شده باشند تا در یک طیف مشخص قرار گیرند.
برای پردازش تصویر در PyTorch، از تابع transforms (تبدیلات) استفاده میکنیم؛ منظور از تبدیلات، عملیاتهای سادهای است که روی آرایهها اجرا میشوند. تبدیلات اعتبارسنجی (و تست) عبارتاند از:
- تغییر اندازه
- برش از ناحیهی مرکز به 224×224
- تبدیل به یک تنسور
- نرمالسازی میانگین و انحراف معیار
نتیجهی این تبدیلات، تنسورهایی خواهند بود که مورد پذیرش شبکه هستند. تبدیلات آموزشی علاوه بر این موارد، شامل دادهافزاییهای تصادفی نیز میشوند.
ابتدا، تبدیلات آموزش و اعتبارسنجی را تعریف میکنیم:
from torchvision import transforms
# Image transformations
image_transforms = {
# Train uses data augmentation
'train':
transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.ColorJitter(),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224), # Image net standards
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) # Imagenet standards
]),
# Validation does not use augmentation
'valid':
transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
ابتدا، تبدیلات آموزش و اعتبارسنجی را تعریف میکنیم:
سپس datasets و DataLoaders را ایجاد میکنیم. PyTorch برای ساخت دیتاست از تابع datasets.ImageFolder استفاده میکند و بدین طریق، به صورت خودکار، تصاویر را به برچسبهای صحیح آنها (که در دیرکتوریهای از پیش تنظیم شده، وجود دارند) مرتبط میکند. در گام بعدی، دیتاستها وارد تابع DataLoader میشوند؛
from torchvision import datasets
from torch.utils.data import DataLoader
# Datasets from folders
data = {
'train':
datasets.ImageFolder(root=traindir, transform=image_transforms['train']),
'valid':
datasets.ImageFolder(root=validdir, transform=image_transforms['valid']),
}
# Dataloader iterators, make sure to shuffle
dataloaders = {
'train': DataLoader(data['train'], batch_size=batch_size, shuffle=True),
'val': DataLoader(data['valid'], batch_size=batch_size, shuffle=True)
}
DataLoader یک تابع iterator است که بستههایی از تصاویر و برچسبها تولید میکند.
# Iterate through the dataloader once trainiter = iter(dataloaders['train']) features, labels = next(trainiter) features.shape, labels.shape (torch.Size([128, 3, 224, 224]), torch.Size([128]))
خروجی این کد، رفتار دورهای تابع DataLoader را به خوبی نشان میدهد:
ساختار بستهها به صورت (batch_size, color_channels, height, width) است. طی مراحل آموزش، اعتبارسنجی و نهایتاً آزمایش، تابع DataLoaders را تکرار میکنیم؛ در هر تکرار، این تابع یک دور کامل در تمام دیتاست میزند. در هر دور DataLoader آموزشی، تبدیلات تقریباً متفاوتی روی تصاویر اجرا میشود تا دادهافزایی انجام گیرد.
استفاده از مدلهای از پیش آموزش دیده در مسئله تشخیص شیء
بعد از اینکه دادهها به شکل مورد نظر درآمدند، توجه خود را به مدل معطوف میکنیم. اینجا از یک شبکهی عصبی کانولوشنی استفاده میکنیم. در PyTorch تعدادی مدل وجود دارند که از پیش روی میلیونها تصویر از 1000 کلاس موجود در ImageNet آموزش دیدهاند. جدول زیر، عملکرد این مدلها را روی دیتاست ImageNet نشان میدهد:
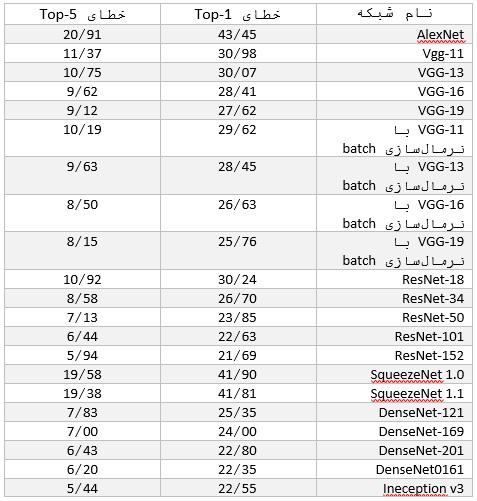
برای این پروژه از مدل VGG-16 استفاده میکنیم. درست است که این مدل پایینترین خطا را در بین مدلها نداشته، اما در این مسئله عملکرد خوبی از خود نشان داده و آموزش آن از سایر مدلها سریعتر بوده است. برای استفاده از یک مدل از پیش آموزش دیده، این گامها را دنبال کنید:
- انتقال وزنها از شبکهای که از قبل روی یک دیتاست بزرگ آموزش دیده است؛
- انجماد همهی وزنهای لایههای (کانولوشنی) پایینی. لایههایی که منجمد میشوند بنا بر شباهت بین مسئله موجود و دیتاست اصلی، قابل تغییر هستند؛
- جابجایی لایههای بالایی شبکه با کلسیفایر دلخواه. تعداد خروجیها باید برابر با تعداد کلاسها باشد؛
- آموزش لایههای کلسیفایر دلخواه برای مسئله حاضر و نهایتاً بهینهسازی مدل برای اجرا روی دیتاست کوچکتر.
در PyTorch، برای انتقال مدل از پیش آموزش دیده از این کد استفاده میشود:
from torchvision import models model = model.vgg16(pretrained=True)
این مدل بیش از 130 میلیون پارامتر دارد، اما تنها چند لایهی کاملاً متصل آخر آموزش میبینند. در انتها، همهی وزنهای مدل منجمد میشوند:
# Freeze model weights
for param in model.parameters():
param.requires_grad = False
سپس نوبت به اضافه کردن کلسیفایر سفارشی میرسد؛ لایههای این کلسیفایر عبارتاند از:
- کاملاً متصل با تابع فعالسازی ReLU و ابعاد= (n_inputs, 256)
- dropout با آستانه Dropping 40 درصد
- کاملاً متصل با خروجی softmax لگاریتمی و ابعاد= (256, n_classes)
import torch.nn as nn# Add on classifier
model.classifier[6] = nn.Sequential(
nn.Linear(n_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, n_classes),
nn.LogSoftmax(dim=1))
لایههایی که به مدل اضافه میشوند به صورت پیشفرض در حالت قابلآموزش قرار دارند (require_grad=True). در مدل VGG-16، تنها آخرین لایهی متصل اصلی را تغییر میدهیم؛ وزنهای مربوط به همهی لایههای پیچشی و 5 لایهی کاملاً متصل اول این مدل، قابل آموزش نخواهند بود.
# Only training classifier[6]
model.classifierSequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Sequential(
(0): Linear(in_features=4096, out_features=256, bias=True)
(1): ReLU()
(2): Dropout(p=0.4)
(3): Linear(in_features=256, out_features=100, bias=True)
(4): LogSoftmax()
)
)
خروجی نهایی شبکه، مقادیر احتمال لگاریتمی برای همهی 100 کلاس موجود در دیتاست میباشد. مدل در کل 135 میلیون پارامتر دارد که بیش از 1 میلیون آنها آموزش خواهند دید.
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')135,335,076 total parameters.
1,074,532 training parameters.
انتقال مدل به GPU
یکی از بهترین قابلیتهای PyTorch این است که امکان انتقال آسان اجزای مختلف یک مدل به یک یا چندین gpu را فراهم میآورد، به نحوی که میتوان از سختافزار نهایت استفاده را کرد. از آنجایی که اینجا برای آموزش از دو gpu استفاده میکنیم، ابتدا مدل را به cuda منتقل کرده و سپس یک مدل توزیعشده DataParallel روی GPUها تولید میکنیم.
# Move to gpu
model = model.to('cuda')
# Distribute across 2 gpus
model = nn.DataParallel(model)
(برای اینکه زمان اجرا در حد قابلقبول باقی بماند، باید این کد را روی یک GPU اجرا کرد. با استفاده از یک CPU، سرعت اجرای مدل تا 10 برابر یا حتی بیشتر هم افزایش مییابد.)
تابع هزینه و بهینهساز آموزش
تابع هزینه آموزش (خطا یا تفاوت بین پیشبینیها و مقادیر واقعی) که اینجا به کار میرود، تابع احتمال لگاریتمی منفی (NLL) است. ورودی تابع زیان NLL در PyTorch، مقادیر احتمال لگاریتمی هستند؛ بنابراین میتوانیم خروجی خام آخرین لایهی مدل را به آن تغذیه کنیم. PyTorch از دیفرانسیلگیری خودکار استفاده میکند، بدین معنی که تنسورها علاوه بر مقادیر، همهی عملیاتهای مربوط به این مقادیر (ضرب، جمع، فعالسازی و غیره) را نیز مد نظر قرار میدهند. به همین دلیل امکان محاسبهی گرادیان (مشتق) همهی تنسورها نسبت به تنسورهای پیشین، وجود دارد.
آنچه گفته شد در عمل بدین معناست که تابع زیان، علاوه بر میزان خطا، سهم همهی وزنها و سوگیریها را نیز در این خطا مدنظر قرار میدهد. بعد از محاسبهی مقدار زیان، گرادیانهای تابع زیان را نسبت به هرکدام از پارامترهای مدل پیدا میکنیم؛ به این فرآیند پسانتشار گفته میشود. بعد از اینکه همهی وزنها را به دست آوردیم، به کمک بهینهساز، از آنها برای به روزرسانی پارامترها استفاده میکنیم. برای درک بهتر این فرآیند به این لینک مراجعه کنید.
تابع بهینهساز به کاررفته در این پروژه، تابع Adam است: نسخهای کارآمد از گرادیان نزولی که معمولاً نیازی به تنظیم دستی نرخ یادگیری ندارد. طی آموزش، بهینهساز با استفاده از گرادیانهای تابع هزینه و از طریق به روزرسانی پارامترها، خطای خروجی مدل را کاهش میدهد (بهینهسازی میکند). تنها پارامترهای اضافه شده به کلسیفایر، بهینهسازی میشوند.
تابع زیان و بهینهساز بدین طریق تعریف میشوند:
from torch import optim # Loss and optimizer criteration = nn.NLLLoss() optimizer = optim.Adam(model.parameters())
با در دست داشتن مدل از پیش آموزش دیده، کلاسیفایر دلخواه، تابع هزینه، بهینهساز و از همه مهمتر داده ها، اکنون آمادهی آموزش هستیم.
آموزش
آموزش مدل در PyTorch آسانتر از Keras است؛ چون در این کتابخانه، پسانتشار و به روزرسانی پارامترها را باید به صورت دستی انجام دهیم. حلقهی اصلی چندین دور تکرار میشود و در هر دور، DataLoader را تکرار میکنیم. خروجی، یک بسته داده و برچسبها هستند که به کل مدل منتقل میشوند. بعد از هر بستهی آموزشی، تابع هزینه را محاسبه کرده، گرادیانهای تابع هزینه نسبت به پارامترهای مدل را پسانتشار میدهیم و سپس به کمک بهینهساز، پارامترها را به روزرسانی میکنیم.
این نوتبوک جزئیات آموزش را به طور کامل بیان کرده است.
for epoch in range(n_epochs):
for data, targets in trainloader:
# Generate predictions
out = model(data)
# Calculate loss
loss = criterion(out, targets)
# Backpropagation
loss.backward()
# Update model parameters
optimizer.step()
اینجا یک قسمت ساده از کدها را مشاهده میکنید:
آموزش را میتوان به تعداد از پیشتعیین شدهای، تکرار کرد. اما این روش یک مشکل دارد و آن این است که منجر به بیشبرازش مدل روی دادههای آموزشی میشود. برای جلوگیری از این موضوع، از دادههای اعتبارسنجی و تابع early stopping استفاده میکنیم.
Early Stopping
Early stopping یا توقف زودهنگام، در شرایطی که زیان اعتبارسنجی طی چند دور گذشته کاهش پیدا نکرده است، سرعت آموزش را کاهش میدهد. هر چه فرآیند آموزش را ادامه دهیم، زیان آموزش کمتر میشود، اما زیان اعتبارسنجی یا به یک نقطهی کمینه و فلات میرسد و یا شروع به افزایش میکند. حالت ایدهآل این است که وقتی زیان اعتبارسنجی در نقطهی کمینه است، آموزش را متوقف کنیم تا بدین ترتیب، مدل بهترین تعمیمپذیری را روی دادههای آزمایشی داشته باشد. هنگام استفاده از Early stopping، پارامترهای هر دوری که در آن زیان اعتبارسنجی کاهش یافته را ذخیره میکنیم تا بعداً بتوانیم آنها را بازیابی کرده و به بهترین عملکرد اعتبارسنجی دست یابیم.
برای اجرای تابع early stopping در مرحلهی اعتبارسنجی، تابع DataLoader را در انتهای هر دور آموزشی تکرار میکنیم. زیان اعتبارسنجی را محاسبه و آن را با پایینترین زیان اعتبارسنجی مقایسه میکنیم. اگر زیان کنونی پایینترین مقدار زیان تا به اینجا را داشته است، مدل را ذخیره میکنیم. اگر زیان طی چند دور اخیر بهتر نشده بود، آموزش را متوقف کرده و بهترین مدلی که ذخیره کردهایم را برمیگردانیم.
همانطور که پیشتر گفتیم، کد کامل را میتوانید در نوتبوک مشاهده کنید. یک قطعه کد را با هم مشاهده میکنیم:
# Early stopping details
n_epochs_stop = 5
min_val_loss = np.Inf
epochs_no_improve = 0
# Main loop
for epoch in range(n_epochs):
# Initialize validation loss for epoch
val_loss = 0
# Training loop
for data, targets in trainloader:
# Generate predictions
out = model(data)
# Calculate loss
loss = criterion(out, targets)
# Backpropagation
loss.backward()
# Update model parameters
optimizer.step()
# Validation loop
for data, targets in validloader:
# Generate predictions
out = model(data)
# Calculate loss
loss = criterion(out, targets)
val_loss += loss
# Average validation loss
val_loss = val_loss / len(trainloader)
# If the validation loss is at a minimum
if val_loss < min_val_loss:
# Save the model
torch.save(model, checkpoint_path)
epochs_no_improve = 0
min_val_loss = val_loss
else:
epochs_no_improve += 1
# Check early stopping condition
if epochs_no_improve == n_epochs_stop:
print('Early stopping!')
# Load in the best model
model = torch.load(checkpoint_path)
برای درک بهتر مزایای early stopping، به منحنیهای یادگیری که زیان و دقت آموزش و اعتبارسنجی را نشان میدهند، دقت کنید:
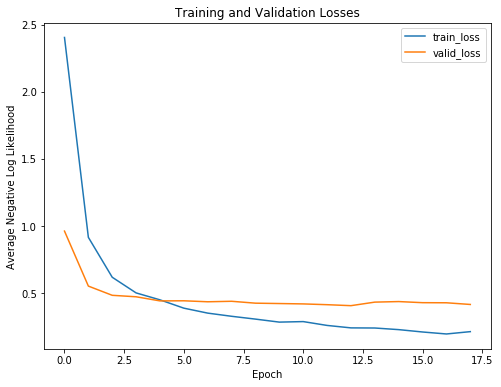
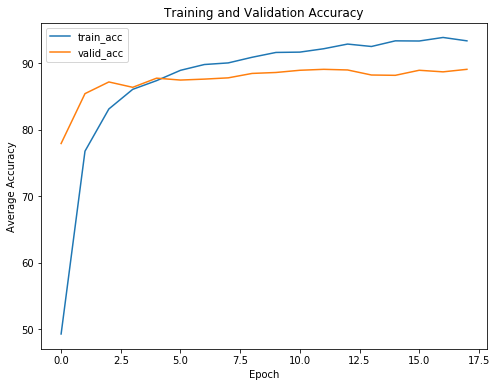
مطابق انتظار، هرچه آموزش ادامه پیدا میکند، زیان آموزش کاهش مییابد؛ اما زیان اعتبارسنجی به یک کمینه میرسد و سپس مسطح میشود. در یک دور مشخص، ادامهی آموزش دیگر فایدهای نخواهد داشت و حتی ممکن است آسیبزا باشد. در این صورت، مدل تنها دادههای آموزشی را به خاطر میسپارد و نمیتواند روی دادههای تست تعمیمپذیری داشته باشد.
به عبارت دیگر، بدون تابع early stopping، مدل بیشتر از حد لازم آموزش خواهد دید و دچار بیشبرازش خواهد شد.
نکتهی دیگری که با توجه به منحنیهای یادگیری درمییابیم این است که بیشبرازش مدل زیاد نیست. طبیعتاً مقداری بیشبرازش وجود دارد، اما اجرای dropout (بعد از اولین لایهی کاملاً متصل قابل آموزش) توانسته است جلوی واگرایی بیش از حد زیانهای آموزش و اعتبارسنجی را بگیرد.
پیشبینی: دریافت خروجی
همانطور که پیشتر مطرح کردیم، مدل روی دادههای آموزشی و حتی اعتبارسنجی عملکرد خوبی داشته است. اما محک آخر این است که ببینیم روی یک مجموعهی تست جدید و دشوار چطور عمل میکند. اگر به خاطر داشته باشید، در آغاز کار 25% از دادهها را به منظور تعیین تعمیمپذیری مدل روی دادههای جدید کنار گذاشتیم.
پیشبینی با استفاده از یک مدل آموزش دیده کار بسیار آسانی است. بدین منظور از همان دستوری استفاده میکنیم که در آموزش و اعتبارسنجی به کار بردیم:
for data, targets in testloader:
log_ps = model(data)
# Convert to probabilities
ps = torch.exp(log_ps)ps.shape()
(128, 100)
بعد احتمالات به دست آمده به صورت ( batch_size , n_classes ) است، چون برای همهی کلاسها یک مقدار احتمال در دست داریم. با مقایسهی بالاترین مقدار احتمال به دست آمده برای هر نمونه با برچسبهای حقیقی، میتوانیم میزان دقت را محاسبه کنیم:
# Find predictions and correct pred = torch.max(ps, dim=1) equals = pred == targets # Calculate accuracy accuracy = torch.mean(equals)
برای ارزیابی شبکهای که در مسئله تشخیص تصویر به کار رفته، بهتر است علاوه بر عملکرد کلی آن روی مجموعهی آزمایشی، تکتک پیشبینیها را نیز بررسی کنیم.
نتایج مدل
اینجا دو نمونه از پیشبینیهای خیلی خوبی که مدل انجام داده را با هم میبینیم:
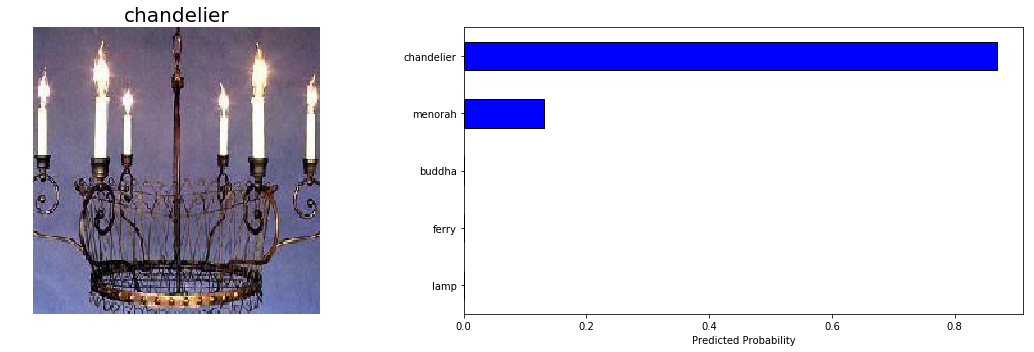

رسیدگی به مسئله تشخیص شیء در این نمونهها بسیار آسان است، پس اینکه مدل مشکلی در پیشبینی آنها نداشته نشانهی خوبی است.
اینجا قصد نداریم فقط روی پیشبینیهای صحیح تمرکز کنیم و در بخشهای بعدی به نتایج اشتباه مدل هم میپردازیم. اما در حال حاضر، میخواهیم عملکرد مدل را روی کل دیتاست تست ارزیابی کنیم. بدین منظور در طول آزمایش، DataLoader را تکرار کرده و زیان و دقت را برای همهی نمونهها محاسبه میکنیم.
برای ارزیابی عملکرد شبکه های عصبی پیچشی در مسئله تشخیص شیء، معمولاً از معیار دقت topk استفاده میشود؛ این معیار نشان میدهد کلاس واقعی جزو k کلاس پیشبینیشدهی اول هست یا خیر. برای مثال، نمرهی top-5 میگوید احتمال اینکه کلاس واقعی در بین 5 کلاسی که با بالاترین مقدار احتمال پیشبینیشدهاند، وجود داشته باشد چقدر است. به منظور پیدا کردن k کلاسی که با بیشترین میزان احتمال پیشبینی شدهاند، میتوانید از این تنسور PyTorch استفاده کنید:
top_5_ps, top_5_classes = ps.topk(5, dim=1) top_5_ps.shape(128, 5)
برای ارزیابی مدل روی کل مجموعهی آزمایشی، این معیارها را محاسبه میکنیم:
Final test top 1 weighted accuracy = 88.65% Final test top 5 weighted accuracy = 98.00% Final test cross entropy per image = 0.3772.
با توجه به این معیارها میتوان نتیجه گرفت که دقت top-1 مدل روی دادههای اعتبارسنجی چیزی حدود 90% است. بنابراین میتوان گفت مدل از پیش آموزش دیده، توانسته است با موفقیت دانش خود از دیتاست ImageNet را به دیتاست کوچکتر انتقال دهد.
بررسی مدل
با اینکه معیارهای بالا حاکی از عملکرد خوب مدل بودند، میتوان برای بهبود بیشتر هم اقداماتی انجام داد. بهترین راه برای اینکه دریابیم عملکرد مدل را چطور میتوانیم ارتقاء دهیم، این است که خطاهای آن را بررسی کنیم.
بعد از بررسی میفهمیم که مدل در تشخیص کروکودیلها عملکرد چندان خوبی نداشته است؛ به همین دلیل به چند نمونهی پیشبینیشده از این دسته نگاه میاندازیم:
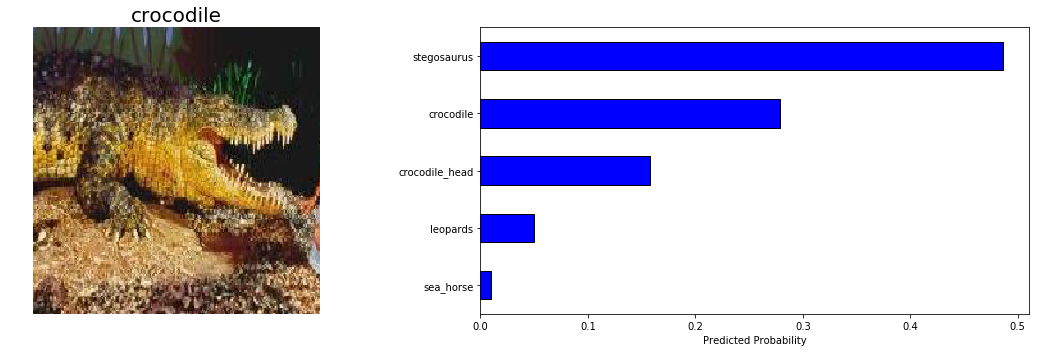
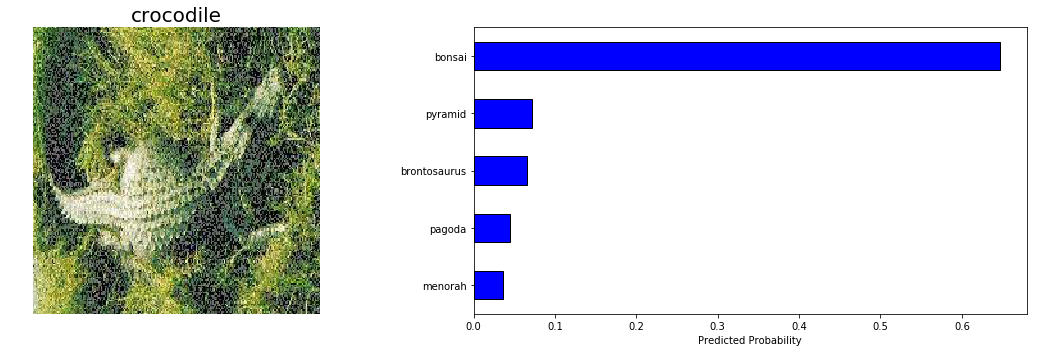

با توجه به تفاوت اندک بین crocodile و crocodile_head و دشواری تشخیص در تصویر دوم، میتوانیم بگوییم که اشتباه مدل در این نمونهها چیز چندان عجیب و غیرطبیعی نبوده است. باید به خاطر داشته باشیم هدف نهایی تشخیص تصویر این است که از قابلیتهای انسانی فراتر برویم و مدل ما تقریباً به این هدف دست یافته است.
نکتهی آخر این است که انتظار میرود مدل روی کلاسهایی که تصاویر بیشتری دارند، بهتر عمل کند. به همین دلیل نموداری مثل تصویر پایین رسم میکنیم که دقت هرکدام از کلاسها را به ازای تعداد تصاویر آموزشی موجود در آنها نشان میدهد:
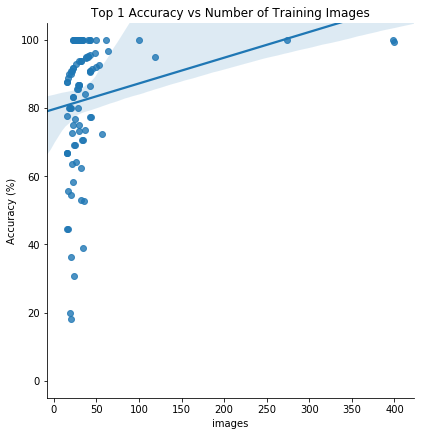
با توجه به نمودار بالا به نظر میرسد بین تعداد تصاویر آموزشی و دقت top1 مدل روی دادههای آزمایشی، همبستگی مثبت وجود دارد. این امر حاکی از مفید بودن دادهافزایی آموزشی و یا حتی دادهافزایی آزمایشی است. برای آزمایشات بیشتر میتوان یک مدل از پیش آموزش دیدهی دیگر را به کار برد یا یک کلسیفایر دلخواه جدید ساخت. در حال حاضر، یادگیری عمیق همچنان حوزهای تجربی باقی میماند، بدین معنی که نیاز به آزمایشات بیشتر وجود دارد.
جمعبندی
در حوزهی یادگیری عمیق شاید کتابخانههای زیادی باشند که کار با آنها آسانتر از PyTorch است، اما این کتابخانه هم مزایای زیادی دارد که از جملهی آنها میتوان به این موارد اشاره کرد: سرعت بالا، کنترل روی جنبههای مختلف معماری/آموزش مدل، اجرای کارآمد پسانتشار با دیفرانسیلگیری خودکار از تنسورها، و سهولت در دیباگ کردن کد به خاطر ذات پویای گرافهای PyTorch. شاید هنوز نتوان دلیل قانعکنندهای برای برتری PyTorch در مقایسه با سایر کتابخانهها (برای مثال Keras که منحنی یادگیری هموارتری دارد) پیدا کرد. با این حال، انتخاب بهترین کتابخانهی ممکن برای پروژههای شخصی یا کد تولید، کار آسانی نیست؛ بنابراین بهتر است با همهی گزینههای موجود آشنایی داشته باشیم.
در این نوشتار، با استفاده از پروژهی مذکور توانستیم با مفاهیم پایهی PyTorch و یادگیری انتقالی آشنا شده و روشی کارآمد برای مسئله تشخیص شیء بیاموزیم. دریافتیم به جای اینکه یک مدل را از صفر آموزش دهیم، میتوانیم از معماریهای موجود که از پیش روی دیتاستهای بزرگ آموزش دیدهاند استفاده کنیم و آنها را برای مسئله سفارشی خودمان تنظیم کنیم. بدین طریق زمان مورد نیاز برای آموزش کاهش مییابد و مدل معمولاً به عملکرد بهتری میرسد. در نتیجهی تسلط بر مفاهیمی که در این مقاله مرور کردیم، میتوانید با استفاده از PyTorch و به کمک یادگیری انتقالی، مسائل پیچیدهتری را حل کنید.





