آموزش پردازش زبان طبیعی با اکوسیستم هاگینگ فیس ؛ روش کار ترنسفورمرها (قسمت پنجم)
 تیم تحریریه
تیم تحریریه- ۲۱ شهریور ۱۴۰۰
در این قسمت، معماری مدلهای ترنسفورمر Transformer models را بررسی خواهیم کرد و با روش کار ترنسفورمرها آشنا خواهیم شد. همچنین در انتهای مطلب میتوانید به دیگر بخشهای این دوره آموزشی دسترسی داشته باشید.
تاریخچه ترنسفورمرها
در تصویر زیر برخی از نقاط مهم در تاریخچه مدلهای ترانسفورمر را مشاهده میکنید:

پیش از بررسی روش کار ترنسفومرها بهتر است اطلاعاتی درباره آنها داشته باشیم. معماری ترنسفورمر در ژوئن 2017 معرفی شد. تمرکز مقاله اصلی این مدل روی مسائل مرتبط با ترجمه بود. به دنبال این مدل، مدلهای قدرتمند دیگری نیز معرفی شدند که از آنها میتوان به موارد زیر اشاره کرد:
ژوئن 2018: GPT، اولین مدل ترنسفورمر از پیش آموزش دیده برای تنظیم دقیق Fine-tuning مسائل مختلف پردازش زبان طبیعی که به نتایج شگفتانگیزی دست یافت.
اکتبر 2018: BERT، یکی دیگر از مدلهای بزرگ و از پیش آموزش دیده که برای خلاصهنویسی بهتر جملات طراحی شده است (در فصل بعدی بیشتر درباره این مدل خواهید خواند.)
فوریه 2019: GPT-2، نسخه بهبودیافته (و بزرگتر) GPT که به دلیل نگرانیهای مربوط به مسائل اخلاقی بلافاصله در دسترس عموم قرار نگرفت.
اکتبر 2019: DistilBERT، نسخه خلاصهشده BERT که 60٪ سریعتر از نسخه قبلی بود و همچنین روی حافظه 40٪ سبکتر بود، اما عملکرد آن تا 97٪ مشابه BERT بود.
اکتبر 2019: BART و T5، دو مدل بزرگ از پیش آموزش دیده که از همان معماری اصلی ترنسفورمر استفاده میکنند.
مه 2020: GPT-3، یک نسخه دیگر از GPT-2 که حتی از نسخه قبلی نیز بزرگتر است و میتواند بدون نیاز به تنظیم دقیق، در حل مسائل مختلف عملکرد خوبی داشته باشد.
البته این لیست کامل نیست و فقط به منظور معرفی شماری از انواع مختلف مدلهای ترنسفورمر آورده شده است. در کل این مدلها را میتوان به سه دسته تقسیم کرد:
GPT مانند (به این مدلهای ترنسفورمر، خودهمبسته auto-regressive نیز گفته میشود)
BERT مانند (به این مدلهای ترنسفورمر، خودرمزنگار auto-encoding نیز گفته میشود)
BART / T5 مانند (به این مدلهای ترنسفورمر، توالیبهتوالی sequence-to-sequence نیز گفته میشود)
بعداً این مدلها را با جزییات بیشتر بررسی خواهیم کرد.
ترنسفورمرها مدلهای زبانی هستند
همه مدلهای ترنسفورمری که در بالا ذکر شد (GPT، BERT، BART، T5 و غیره) به عنوان مدلهای زبانی آموزش داده شدهاند. این بدان معناست که آنها با حجم زیادی از متن خام و به روش خودنظارتی آموزش دیدهاند. یادگیری خودنظارتی نوعی یادگیری است که در آن هدف به طور خودکار براساس ورودیهای مدل محاسبه میشود. این بدان معناست که برای برچسبگذاری داده ها به انسان نیازی نیست.
این مدل نوعی درک آماری از زبانی که توسط آن آموزش داده شده است را توسعه میدهد. اما برای حل مسائل عملی خاص چندان کارامد نیست. به همین دلیل، مدل پس از فرایند پیش آموزش عمومی، وارد فرایندی به نام یادگیری انتقالی میشود. طی این فرآیند، مدل به روش نظارتشده (یعنی با استفاده از برچسبهای حاشیهنویسیشده توسط انسان) برای یک مسئله مشخص به طور دقیق تنظیم میشود.
یک نمونه از مسائلی که این مدلها میتوانند حل کنند این است که بعد از خواندن n کلمه از یک جمله، کلمه بعدی را پیشبینی کنند. به این کار مدلسازی زبان عِلی causal language modeling میگویند زیرا خروجی به ورودیهای گذشته و حال بستگی دارد. اما به ورودیهای آینده ارتباطی ندارد.

نمونهای دیگر از مسائلی که این مدلها قادر به حل آن هستند مدلسازی زبانی پوششی که در آن مدل، کلمهای که با یک ماسک پوشیده شده است را پیشبینی میکند.

ترنسفورمرها مدلهای بزرگی هستند
استراتژی کلی برای دستیابی به عملکرد بهتر، به غیر از در برخی از مدلها مانند DistilBERT، افزایش سایز مدلها است. همچنین افزایش حجم دادههایی است که برای آموزش به آنها داده میشود.

نکتهای که درباره روش کار ترنسفورمرها باید بدانید این است که متأسفانه، آموزش یک مدل، به ویژه یک مدل بزرگ، به مقدار زیادی داده نیاز دارد. این کار از نظر زمان و منابع محسباتی بسیار پرهزینه است. همانطور که در نمودار زیر مشاهده میکنید، آموزش مدل حتی تأثیرات زیستمحیطی نیز دارد.

مدلی که در تصویر بالا به آن اشاره شده است مربوط به پروژهای در ورکشاپ Bigscience بوده که تیم حاضر در آن مدلی بسیار بزرگ (دارای 200 میلیارد پارامتر) را با هدف کاهش تأثیرات زیستمحیطی مرحله پیش آموزش توسعه دادند. البته ردپای زیستمحیطی فرایند آزمون و خطاهای متعدد برای پیدا کردن بهترین ابرپارامترها حتی بیشتر از این خواهد بود.
تصور کنید اگر هر بار که یک تیم تحقیقاتی، یک سازمان دانشجویی یا یک شرکت بخواهد مدلی را آموزش دهد، مجبور باشد این کار را از صفر شروع کند و انجام دهد، چه هزینههای کلان و غیرضروری به دنیا تحمیل میشود!
به همین دلیل بهاشتراکگذاری مدلهای زبانی از اهمیت بالایی برخوردار است. به اشتراکگذاری وزنهای مدل آموزش دیده و ساختن مدل جدید بر پایه وزنهای آن، هزینه کلی محاسبات و ردپای کربن جامعه را کاهش میدهد.
یادگیری انتقالی در روش کار ترنسفورمرها
برای آشنایی با روش کار ترنسفورمرها باید بدانید که پیش آموزش به معنای آموزش یک مدل از صفر است. در این فرایند، مقداردهی اولیه وزنها به صورت تصادفی انجام میشود و سپس آموزش بدون هیچ گونه دانش قبلی آغاز میگردد.

پیش آموزش معمولاً روی دادههایی با حجم بسیار زیاد انجام میشود. بنابراین، به یک مجموعه داده بسیار بزرگ نیاز است و آموزش ممکن است چندین هفته به طول بیانجامد.
از طرف دیگر، تنظیم دقیق، مرحلهای از آموزش است که پس از مرحله پیش آموزش یک مدل اجرا میشود. برای انجام این کار، ابتدا یک مدل زبانی از پیش آموزشدیده تهیه میکنید. سپس آن را روی دیتاستی که کاملاً با مسئله مدنظر شما مرتبط است آموزش میدهید. اما چرا از همان اول به سادگی مدل را برای انجام کار نهایی آموزش نمیدهیم؟ این کار چند دلیل دارد:
- مدل از پیش آموزش دیده ابتدا روی دیتاستی که دارای شباهتهای زیادی با دیتاست اصلی در تنظیم دقیق است، آموزش دیده است. بنابراین فرآیند تنظیم دقیق میتواند از دانش به دست آمده توسط مدل اولیه در حین مرحله قبلی بهره ببرد. به عنوان مثال، در حوزه NLP، مدل از پیش آموزشدیده نوعی درک آماری از زبانی که برای حل مسئله مدنظر خود استفاده میکنید دارد.
- از آنجا که مدل آموزش دیده قبلاً روی دادههای زیادی آموزش دیده است، در مرحله تنظیم دقیق برای رسیدن به نتایج مطلوب، به دادههای کمتری نیاز دارید.
- به همین دلیل، زمان و منابعی که باید صرف رسیدن به نتایج مطلوب شود، کاهش مییابد.
برای مثال، میتوان یک مدل از پیش آموزش دیده را به زبان انگلیسی آموزش داد. سپس برای مرحله تنظیم دقیق آن از دیتاست arXiv استفاده کرد. در نهایت هم یک مدل مبتنی بر علم یا پژوهش به دست آورد. مرحله تنظیم دقیق را میتوان با حجم داده کم نیز انجام داد. در این مرحله دانشی که مدل از مرحله پیش آموزش به دست آورده است «منتقل میشود»، از این رو به آن اصطلاحاً یادگیری انتقالی گفته میشود.
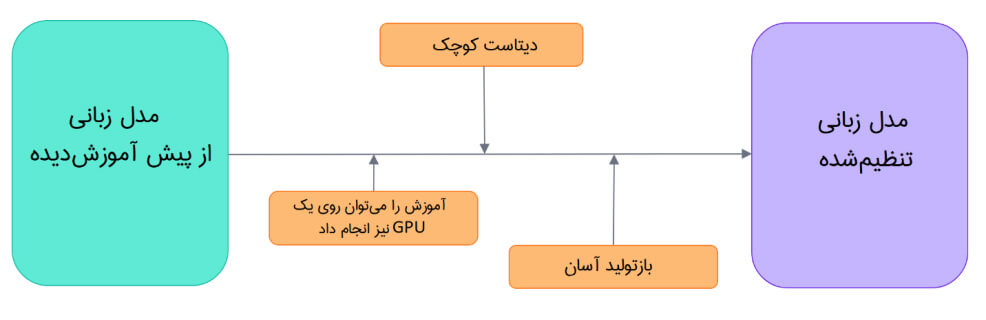
همانطور که ملاحظه میفرمایید، تنظیم دقیق یک مدل زمان، داده، هزینههای مالی و زیستمحیطی کمتری نیاز دارد. همچنین تکرار طرحهای مختلف تنظیم دقیق سریعتر و آسانتر است. زیرا آموزش ساده یک مدل در مقایسه با پیش آموزش کامل آن محدودیتهای کمتری دارد.
به علاوه، این فرایند نسبت به آموزش از مدل از صفر نتایج بهتری به دست میدهد. مگر اینکه حجم دادههای در دسترستان زیاد باشد. به همین دلیل باید سعی کنید از یک مدل از پیش آموزشدیده استفاده کنید و آن را تنظیم کنید.
معماری عمومی
در این بخش از مقاله مربوط به آشنایی با روش کار ترنسفورمرها، ما به معماری کلی مدل ترنسفومر خواهیم پرداخت. اگر بعضی از مفاهیم را متوجه نمیشوید نگران نباشید. در قسمتهای بعدی به طور مفصل درخصوص هر یک از این اجزا صحبت خواهیم کرد.
ویدئو آموزش پردازش زبان طبیعی
این مدل در درجه اول از دو بلوک تشکیل شده است:
- رمزنگار Encoder (سمت چپ): رمزنگار ورودی را دریافت میکند و نگاشتی از آن (ویژگیهای آن) میسازد. این بدان معنی است که مدل برای درک داده ورودی، بهینه شده است.
- رمزگشا Decoder (سمت راست): رمزگشا با استفاده از نگاشتی (ویژگیهایی) که رمزنگار تهیه کرده و سایر ورودیها دریافتی خود یک توالی هدف ایجاد میکند. این بدان معنی است که مدل برای تولید خروجی، بهینه شده است.

بسته به مسئله مدنظر میتوان هر یک از این قسمتها را به طور مستقل نیز استفاده کرد:
- مدلهای فقط رمزنگار: برای کارهایی که نیاز به درک ورودی دارند، مانند دستهبندی جملات و تشخیص موجودیتهای نامدار named entity recognition، مناسب است.
- مدلهای فقط رمزگشا: برای مسائلی که میخواهیم چیزی تولید کنیم کاربرد دارند، مانند مسائل تولید متن.
- مدلهای رمزگشا-رمزنگار یا مدلهای توالیبهتوالی: برای مسائل مولدی که به ورودی نیاز دارند، مانند ترجمه یا خلاصهسازی، مناسبند.
در بخشهای بعدی به طور جداگانه به هر یک از این معماریها خواهیم پرداخت.
لایههای توجه
ویژگی اصلی مدلهای ترنسفورمر این است که با لایههای خاصی به نام لایههای توجه Attention layers ساخته شدهاند. در واقع، عنوان مقاله معرفی معماری ترنسفورمر «توجه، همه آن چیزی است که شما نیاز دارید» بود. بعد از این که در این دوره با روش کار ترنسفورمرها آشنا شدید، در قسمتهای بعدی این دوره لایههای توجه را با جزییات بیشتری بررسی خواهیم کرد. در حال حاضر، تنها چیزی که شما باید درباره این لایهها بدانید این است که این لایه به مدل میگوید هنگام کار با نگاشت هر کلمه، به یک سری کلمات خاص در جملهای که به آن دادهاید، توجه ویژهای داشته باشد (و بقیه را کم و بیش نادیده بگیرید).
فرض کنید میخواهیم یک متن را از انگلیسی به فرانسوی ترجمه کنیم. به عنوان ورودی جمله ” You like this course” را به مدل میدهیم. در این مسئله، مدل ترجمه باید به کلمه مجاور کلمه «like» یعنی «You» نیز توجه کند تا ترجمه مناسبی برای کلمه «like» ارائه دهد، زیرا در زبان فرانسه صرف فعل «like» به فاعل وابسته است.
با این حال، بقیه جمله برای ترجمه آن کلمه مفید نیست. به همین ترتیب، هنگام ترجمه کلمه «this» مدل باید به کلمه «course» نیز توجه کند. زیرا ترجمه کلمه «this» به فرانسوی، بسته به مذکر یا مونث بودن کلمه بعدی تغییر میکند. اما سایر کلمات جمله برای ترجمه کلمه «this» اهمیتی نخواهند داشت. در جملات پیچیدهتر (که قوانین دستورزبان پیچیدهتری نیز دارند) ممکن است مدل مجبور شود برای ترجمه هر کلمه نه تنها به کلمات مجاور، بلکه به کلمات دورتر نیز توجه داشته باشد تا بتواند ترجمه درستی از هر کلمه ارائه دهد.
این مفهوم به مسائل مرتبط با زبان طبیعی نیز قابل تعمیم است. یک کلمه به خودی خود دارای یک معنی است. اما این معنی به شدت تحت تأثیر بافت جمله (کلمات بعدی یا قبلی کلمه منتخب) قرار دارد.
اکنون که تا حدودی متوجه کاربرد لایههای توجه شدید و با روش کار ترنسفورمرها آشنا شدید، بیایید نگاهی دقیق به معماری ترنسفورمر بیندازیم.
معماری اصلی
معماری ترنسفورمر در اصل برای ترجمه طراحی شده است. در طول آموزش، رمزنگار ورودیها را به یک زبان خاص دریافت میکند. رمزگشا همان جملات را به زبان مقصد موردنظر دریافت میکند. در رمزنگار، لایههای توجه میتوانند از تمام کلمات یک جمله استفاده کنند. زیرا، همانطور که دیدیم، ترجمه یک کلمه میتواند به کلمات بعد و قبل آن در جمله بستگی داشته باشد. اما رمزگشا به ترتیب کار میکند و فقط میتواند به کلماتی از جمله توجه میکند که قبلاً ترجمه کرده است. بنابراین فقط به کلمات قبل از کلمهای که در حال حاضر تولید میشود، توجه دارد. به عنوان مثال، وقتی سه کلمه اول از ترجمه متن پیشبینی شوند، آنها را به رمزگشا میدهیم. با این کار با استفاده از تمام ورودیهای رمزنگار، کلمه چهارم را پیشبینی کند.
برای سرعت بخشیدن به فرایند آموزش (هنگامیکه مدل به جملات هدف دسترسی دارد)، رمزگشا کل هدف را میگیرد. اما اجازه استفاده از کلمات بعدی را ندارد. چون اگر در هنگام تلاش برای پیشبینی کلمه دوم، به کلمه دوم دسترسی داشته باشد، دیگر چیزی برای پیشبینی وجود نخواهد داشت. به عنوان مثال، وقتی مدل میخواهد کلمه چهارم را پیشبینی کند، لایه توجه فقط به کلمات موجود در موقعیتهای 1 تا 3 دسترسی خواهد داشت.
از طریق این لینک میتوانید به قسمتهای دیگر دوره آموزشی پردازش زبان طبیعی دسترسی داشته باشید:
[button href=”https://hooshio.com/%D8%B1%D8%B3%D8%A7%D9%86%D9%87-%D9%87%D8%A7/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-%D9%BE%D8%B1%D8%AF%D8%A7%D8%B2%D8%B4-%D8%B2%D8%A8%D8%A7%D9%86-%D8%B7%D8%A8%DB%8C%D8%B9%DB%8C/” type=”btn-default” size=”btn-lg”]آموزش پردازش زبان طبیعی[/button]