
مروری بر مسیری که هوش مصنوعی طی کرد و مسیری که در پیش دارد
آینده هوش مصنوعی
 سید محمدجواد فیاض
سید محمدجواد فیاض- ۱۷ مرداد ۱۴۰۴
تصور غالبی که گاه در روایتهای عامیانه و برخی رسانهها مطرح میشود، این است که هوش مصنوعی در آیندهای نهچندان دور تمام مشاغل انسانی را تصاحب خواهد کرد و انسان را از گردونه کار و تصمیمگیری خارج میکند.
با اینکه چنین تصویر اغراقشدهای از آینده چندان واقعگرایانه نیست، اما شکی نیست که شتاب یادگیری و بهبود عملکرد الگوریتمهای هوشمند، ما را در آستانه تغییراتی بنیادین قرار داده است؛ تغییراتی که نه فقط در محیط کار، بلکه در سبک زندگی، روابط انسانی و حتی ساختارهای اجتماعی و سیاسی نمود پیدا میکنند.
آهسته و پیوسته
هوش مصنوعی امروز دیگر پدیدهای آیندهنگرانه یا صرفاً موضوعی آکادمیک نیست، بلکه به شکل ملموس در زندگی روزمره ما حضور دارد. از گویندههای هوشمندی که سفارش خرید روزمرهمان را ثبت میکنند گرفته تا ابزارهای سرگرمی مانند فیلترهای چهره در تماسهای تصویری و اپلیکیشنهای ویرایش تصویر، همهوهمه نشانههایی از نفوذ آرام اما عمیق هوش مصنوعی در زیست روزانه انسان است.
اما این فقط ظاهر ماجراست. در لایههای عمیقتر، تحولاتی جدیتر در جریان است. شرکتهای فناوری با سرمایهگذاریهای کلان در حوزه هوش مصنوعی، زمینهساز تحولات گسترده در بسیاری از حوزهها شدهاند. مهمترین پیشران این تحولات، پیشرفت چشمگیر در «یادگیری ماشین» (Machine Learning) و بهویژه زیرشاخه آن یعنی «یادگیری عمیق» (Deep Learning) است؛ فناوریهایی که به الگوریتمها اجازه میدهند نه با دستورهای صریح انسانی، بلکه از طریق تحلیل حجم عظیمی از دادهها، الگوها را کشف کرده و به طور مستقل تصمیمگیری کنند.
با اینهمه، رشد فزاینده هوش مصنوعی صرفاً نویدبخش آیندهای روشن نیست. همانطور که الگوریتمها میتوانند دقت، سرعت و کارایی را افزایش دهند، گاه نیز میتوانند به طور ناخواسته تعصبات انسانی را بازتولید کرده یا حتی آنها را تقویت کنند. مواردی از تبعیض نژادی یا جنسیتی در سیستمهای استخدام، تشخیص چهره، یا الگوریتمهای وامدهی بانکی نشان دادهاند که آموزش نامناسب یا دادههای دارای سوگیری میتوانند منجر به تصمیمگیریهای ناعادلانه شوند.
امروز بیش از هر زمان دیگری نیاز است که توسعه هوش مصنوعی با ملاحظات اخلاقی، حقوقی و اجتماعی همراه باشد. اگرچه این فناوری میتواند کیفیت زندگی بشر را ارتقا دهد، اما این ارتقا بدون نظارت، شفافیت و مشارکت اجتماعی گسترده میتواند هزینههای ناخواسته و بعضاً جبرانناپذیری در پی داشته باشد.
خلاصه خط زمانی برخی از رویدادهای کلیدی تاریخ هوش مصنوعی
سال ۱۹۵۶: پروژه تحقیقات تابستانی دانشگاه دارتموث با محوریت «هوش صنوعی» باعث ابداع رشته جدیدی شد که با تولید نرمافزارهای هوشمند سروکار دارد.
سال ۱۹۵۶: «جوزف وایزنبوم» در MIT موفق به ساخت «اِلیزا» نخستین ربات مکالمه شد. این ربات نقش یک رواندرمان را ایفا میکرد.
سال ۱۹۷۵: «مِتا-درندرال» نرمافزاری است که در استنفورد برای انجام تحلیلهای شیمیایی ساخته شد. این نرمافزار با رایانه اکتشافاتی انجام داد که در یک مجله داوریشده منتشر شد.
سال ۱۹۸۷: یک دستگاه وَن مرسدس بنز به کمک دو دوربین و چند راننده رایانهای، موفق شد مسافت 20 کیلومتری را در یکی از بزرگراههای آلمان با سرعت بیش از 55 مایل طی کند. مهندسی به نام «ارنست دیکمانس» سرپرستی این پروژه دانشگاهی را بر عهده داشت.
سال ۱۹۹۷: رایانه «Deep Blue» متعلق به «IBM» موفق به شکست گَری کاسپاروف قهرمان شطرنج جهان شد.
سال ۲۰۰۴: پنتاگون «چالش گرَند دارپا» را کلید زد؛ مسابقه خودروهای رباتیک در صحرای موجاوه که تحولی در صنعت اتومبیلهای خودران پدید آورد.
سال ۲۰۱۲: محققان در حوزهای تحت عنوان یادگیری عمیق، زمینه را برای علاقهمندیِ شرکتها به هوش مصنوعی فراهم آوردند. آنان نشان دادند که ایدههایشان میتواند تشخیص عکس و گفتار را دقیقتر کند.
سال ۲۰۱۶: «آلفاگو» محصول شرکت گوگل موفق به شکست قهرمان جهان در بازی «Go» شد.
اوایل ۲۰۲۰: آغاز عرضه عمومی چتباتها و همهگیری هوش مصنوعی مولد
از رؤیاهای علمی تا جنبشی فناورانه
هوش مصنوعی، آنگونه که امروز آن را میشناسیم، ریشه در رؤیاهای علمیِ جسورانه و بلندپروازانه دارد؛ رؤیاهایی که در میانه قرن بیستم شکل گرفتند و بهتدریج، از کارگاههای تحقیقاتی دانشگاهی به بخشی جدانشدنی از صنعت و زندگی روزمره انسان تبدیل شدند.
نقطه آغاز رسمی این مسیر، تابستان سال ۱۹۵۶ بود؛ جایی که «جان مککارتی»، استاد ریاضی دانشگاه «دارتموث»، کارگاهی تحقیقاتی برگزار کرد که بهدرستی میتوان آن را لحظه تولد واژه و مفهوم «هوش مصنوعی» دانست. مککارتی با دعوت از گروه کوچکی از ریاضیدانان و دانشمندان رایانه، تلاش کرد تعریفی برای ماشینهای هوشمند ارائه دهد و مسیری برای توسعه آنها طراحی کند. او امیدوار بود که با گرد هم آوردن گروهی منتخب از دانشمندان بااستعداد، بتوان ظرف چند هفته، ماشینهایی ساخت که تواناییهایی مشابه انسانمانند درک زبان، حل مسئله و یادگیری را داشته باشند. هرچند این خوشبینی در کوتاهمدت محقق نشد و مککارتی بعدها اذعان کرد که بیش از حد امیدوار بوده، اما کارگاه دارتموث پایهگذار یکی از مهمترین رشتههای فناورانه قرن بیستم شد.
دهههای نخست: شوق آغاز، محدودیت داده
در دهههای ۱۹۵۰ تا ۱۹۷۰، بیشتر تلاشها در حوزه هوش مصنوعی معطوف به الگوریتمهای نمادین و حل مسائل منطقی بود. «آرتور ساموئل» در این سالها نرمافزاری طراحی کرد که توانست بازی «چِکِر» را یاد بگیرد و حتی در سال ۱۹۶۲ توانست یکی از استادان این بازی را شکست دهد. این اولین نمونه از یادگیری ماشین مبتنی بر تجربه بود. در سال ۱۹۶۵، «جوزف وایزنبام» در MIT، سیستم معروف Eliza را طراحی کرد که یک ربات مکالمهگر ساده و تنها با الگوهای زبانی ساده بود که نقش یک رواندرمانگر را ایفا میکرد.
در سال ۱۹۶۷، پروژه DENDRAL در دانشگاه استنفورد نشان داد که ماشینها میتوانند از منطق متخصصان شیمی تقلید کرده و از دادههای جرم و طیفسنجی، ساختار مولکولهای ناشناخته را شناسایی کنند. این نخستین نمونه از سیستمهای خبره (Expert Systems) بود؛ الگوریتمهایی که به دانش انسانی متکی بودند و میتوانستند در حوزهای خاص، تحلیلهایی شبیه به متخصصان انجام دهند.
دهههای ۸۰ و ۹۰: عبور از آزمایشگاه
دهه ۱۹۸۰ شاهد ظهور سیستمهای خبره و تلاشهای صنعتی برای تجاریسازی هوش مصنوعی بود. اگرچه این موج به دلیل هزینههای بالا و محدودیت در انعطافپذیری الگوریتمها خیلی زود فروکش کرد، اما دستاوردهای مهمی به همراه داشت. پروژهای که در سال ۱۹۸۷ در آلمان و با هدایت «ارنست دیکمانس» انجام شد، یک ون مرسدسبنز را با استفاده از دوربین و سامانههای تصمیمگیری رایانهای، قادر ساخت تا با سرعت ۹۰ کیلومتر در ساعت، در یک بزرگراه واقعی حرکت کند. این تجربه یکی از نخستین گامها در مسیر اتومبیلهای خودران بود.
در سال ۱۹۹۷، رایانه Deep Blue شرکت IBM توانست «گری کاسپاروف»، اسطوره شطرنج جهان را شکست دهد. این پیروزی، نقطه عطفی در ادبیات عمومی پیرامون هوش مصنوعی بود و نشان داد که ماشینها میتوانند در برخی زمینهها، نهتنها به سطح انسان، بلکه به فراتر از آن نیز برسند.

دهه ۲۰۰۰: بازگشت دادهها، جهش یادگیری
آغاز دهه ۲۰۰۰ همزمان شد با رشد نمایی قدرت پردازش رایانهها و افزایش حجم دادههای دیجیتال. در سال ۲۰۰۴، پنتاگون پروژهای به نام Grand DARPA Challenge را برگزار کرد که در آن خودروهای خودران میبایست در شرایط واقعی در صحرا رقابت میکردند. هرچند شرکتکنندگان در اولین دوره، شکست خوردند، اما همین چالش منجر به شکلگیری نسل جدیدی از تحقیقات در زمینه خودرانها شد.

نقطه عطف بعدی در سال ۲۰۱۲ رقم خورد؛ جایی که پژوهشگرانی مانند «جفری هینتون» و «یان لیکان»، با استفاده از «شبکههای عصبی عمیق» (Deep Neural Networks)مدلهایی ارائه کردند که در تشخیص تصویر و گفتار بسیار دقیقتر از روشهای قبلی عمل میکردند. این تحولات موجب جلبتوجه شرکتهای بزرگی چون گوگل، فیسبوک و آمازون به یادگیری عمیق شد.
دهه ۲۰۱۰: بازتعریف مرزها
در سال ۲۰۱۶، سامانه هوش مصنوعی AlphaGo متعلق به شرکت DeepMind (زیرمجموعه گوگل)، توانست «لی سِدول»، قهرمان افسانهای بازی پیچیده و استراتژیک «Go» را شکست دهد. اتفاقی که تا پیش از آن، بسیاری از متخصصان آن را تا دو دهه دورتر پیشبینی کرده بودند. اهمیت این رویداد در آن بود که بازی Go به دلیل پیچیدگی بینظیر، همیشه نمادی از ناتوانی الگوریتمها در برابر خلاقیت انسانی تلقی میشد. AlphaGo با تحلیل میلیاردها حرکت و یادگیری تقویتی، توانست فراتر از تاکتیکهای انسانی عمل کند؛ و همین امر باعث شد این پیروزی، آغاز فصل تازهای در درک عمومی از تواناییهای هوش مصنوعی بود؛ الگوریتمهایی که میتوانند خلاقیت، استراتژی و حتی تصمیمگیری در شرایط پیچیده را از انسان فراتر ببرند.

دهه ۲۰۲۰: جنبش چتباتها
مفهوم چتباتها به طور گسترده و عمومی در اوایل دهه ۲۰۲۰ مطرح شد. سامانهای که میتواند با کاربر مکالمه کند، بشنود و پاسخهایی که ارائه دهد که حتی از چندین ساعت جستوجو در فضای آنلاین هم بهتر و مؤثرتر هستند. چتباتهای مفهوم هوش مصنوعی در زندگی روزمره با بیشتر از هر فناوری دیگری برای عامه مردم و غیرحرفهایها روشن و واضح کردند. کمتر فناوریای را میتوان مثال زد که به این سرعت توانسته باشند در سطح جهانی مورداستفاده قرار بگیرد و محبوب شود.
یادگیری عمیق: احیای یک ایده کهنه با قدرتی نوین
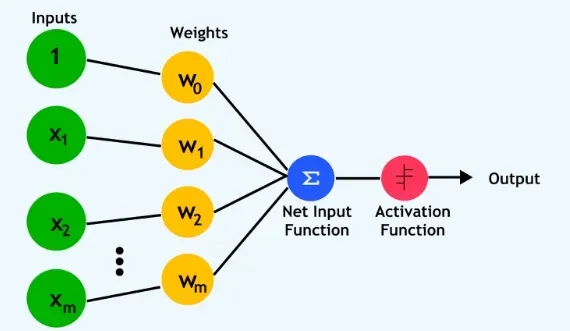
پیشرفت شگفتانگیز هوش مصنوعی در دهه اخیر، بیش از هر چیز مدیون احیای دوباره یکی از قدیمیترین ایدههای این حوزه یعنی شبکه عصبی مصنوعی است و به سوخت اصلی انقلاب هوش مصنوعی مدرن تبدیل شده است. اصلیترین زیرشاخه شبکه عصبی مصنوعی یعنی یادگیری عمیق بر پایه مفهومی بهظاهر ساده اما بسیار پیچیده بنا شده است؛ الهامگیری از ساختار مغز انسان برای ساخت مدلهایی محاسباتی که بتوانند از دادهها بیاموزند. در این سیستمها، دادهها از میان لایههایی از گرههای محاسباتی (نرونهای مصنوعی) عبور میکنند. هر لایه، ویژگیهایی پیچیدهتر از داده را استخراج کرده و به لایه بعد منتقل میکند. فرایند آموزش این شبکهها شامل تنظیم وزنها ریاضی میان این گرهها بر اساس دادههای ورودی و نتایج موردانتظار است.
از پِرسپترون تا بحران
ایده شبکه عصبی مصنوعی اصلاً جدید نیست. تنها دو سال پس از کارگاه دارتموث، در سال ۱۹۵۸، «فرانک روزنبلات»، روانشناس و دانشمند علوم کامپیوتر، مدل Perceptron را معرفی کرد؛ ماشینی که میتوانست میان اشکال هندسی ساده تمایز قائل شود. این پروژه توجه عمومی و رسانهها را برانگیخت و روزنامه نیویورکتایمز از آن با عنوان «جنینی از رایانهای که میتواند بیاموزد» یادکرد.
اما این شور اولیه چندان طولانی نشد. در سال ۱۹۶۹، کتابی از «ماروین مینسکی» و «سیمور پاپرت» با عنوان Perceptrons منتشر شد که در آن به محدودیتهای شدید شبکههای عصبی تکلایه پرداخته شد. این نقد هرچند بهصورت فنی دقیق بود؛ اما سبب شد تا تمامی بودجهها و توجهات از این مسیر پژوهشی منحرف شوند. یادگیری آماری و الگوریتمهای نمادین جای آن را گرفتند و شبکههای عصبی تا مدتها در حاشیه ماندند.
بازگشت از تبعید: یادگیری عمیق در عصر دادههای عظیم
دهه ۲۰۱۰ صحنه بازگشت شکوهمند این فناوری بود. در سال ۲۰۱۲، تیمی به رهبری «جفری هینتون»در دانشگاه تورنتو، با استفاده از شبکهای عمیق و کلاندادههای تصویری ImageNet، توانست به شکل چشمگیری خطای تشخیص تصویر را در مسابقهای جهانی کاهش دهد. این لحظه، نقطه عطفی در تاریخ یادگیری ماشین بود و نشان داد که شبکههای عصبی، در صورت برخورداری از قدرت پردازشی بالا و دادههای کافی، میتوانند به شکل بیسابقهای مؤثر باشند.
همزمان، شرکتهایی چون گوگل، IBM، و مایکروسافت نیز در زمینه تشخیص گفتار، با استفاده از یادگیری عمیق، به نتایجی دست یافتند که سطح دقت را به مرزهای عملکرد انسانی نزدیک میکرد. این موفقیتها موجی از رقابت را در سیلیکونولی به راه انداخت و شرکتهای بزرگ، با صرف بودجههای کلان، اقدام به جذب سریع متخصصان یادگیری عمیق کردند. برخی از این استخدامها، با پیشنهادهایی میلیونی و شرایط ویژه صورت میگرفتند.

فراتر از الهام عصبی
هرچند شبکههای عصبی مصنوعی از مغز انسان الهام گرفته شدهاند، اما ساختار و عملکرد آنها از بسیاری جهات با مغز واقعی متفاوت است. پژوهشهای اخیر در حوزه شبکههای عصبی گرافی (Graph Neural Networks)، شبکههای توجهمحور (Transformers) و مدلهای مولد خودنظارتی (Self-supervised Generative Models) نشان دادهاند که میتوان از روشهایی پیچیدهتر و مؤثرتر برای فهم و تولید اطلاعات استفاده کرد، بدون آنکه لزوماً به شبیهسازی دقیق مغز وفادار ماند.
در میان پیشرفت فناورانه و مسئولیت اخلاقی
هیچ تردیدی نیست که هوش مصنوعی در سالهای آینده تأثیر عمیقی بر تمامی ابعاد زندگی بشر خواهد داشت. بسیاری از شرکتهای بزرگ فناوری سرمایهگذاریهای کلانی در این حوزه انجام دادهاند و رقابت برای جذب نیروهای متخصص در این حوزه به یکی از داغترین بازارهای استخدام در دنیای فناوری تبدیل شده است.
از سوی دیگر، گسترش سختافزارهای ویژه هوش مصنوعی مانند تراشههای مخصوص یادگیری عمیق (GPU, TPU, NPU) به همراه انتشار گسترده مدلهای منبعباز موجب شده است که استفاده از هوش مصنوعی در صنایع کوچکتر، نهادهای عمومی و حتی پروژههای فردی نیز روبهافزایش باشد. امروز دیگر تنها شرکتهای بزرگ بازیگر این میدان نیستند؛ اکوسیستم توسعهدهندگان مستقل و پژوهشگران دانشگاهی نیز نقش مهمی در این پیشرفت دارند.
افق پرچالش هوش مصنوعی عمومی
با وجود تمامی این دستاوردها، هنوز فاصله قابلتوجهی با رؤیای ساخت «هوش مصنوعی عمومی» (Artificial General Intelligence – AGI) یعنی ماشینی که همچون انسان بتواند در حوزههای گوناگون بیاموزد، تطبیق یابد، استدلال کند و خلاقانه عمل کند، داریم. اگرچه مدلهای زبانی بزرگ مانند GPT-4، Claude، Gemini یا LLaMA توانستهاند در بسیاری از زمینهها عملکردی شبیه به انسان ارائه دهند، اما همچنان در انجام وظایفی مانند درک ضمنی زبان (فهم کنایه، شوخی یا استعاره)، یادگیری از مثالهای کوچک و یکباره (one-shot learning)، استدلال علتومعلولی و تطبیق سریع در موقعیتهای کاملاً جدید با چالشهای جدی مواجهاند.

فناوری در سایه مسئولیتپذیری
با قدرتگرفتن هوش مصنوعی، پیامدهای اجتماعی، سیاسی و اخلاقی آن نیز پررنگتر شدهاند. دستیارهای صوتی خانگی که دائماً در حال شنود محیط هستند، نگرانیهایی درباره حریم خصوصی ایجاد کردهاند. رباتهای اجتماعی و اندرویدهای انساننما نیز سؤالاتی بنیادی درباره ماهیت هویت، رابطه انسان و ماشین، و مرزهای اخلاقی بهرهکشی از ماشینهایی با «شمایل انسانی» به میان آوردهاند.
پژوهشهای پیشگامانی مانند «هیروشی ایشیگورو» که تلاش میکند اندرویدهایی با رفتار اجتماعی شبیه به انسان بسازد، پیشنمایشی از مسائلی هستند که در دهههای آینده به شکلی فراگیرتر مطرح خواهند شد:
- آیا ما به اندرویدهایی که شبیه انساناند، اعتماد میکنیم؟
- اگر آنها ابراز احساسات کنند، آیا اخلاقاً موظف به احترام به آنها هستیم؟
- آیا شباهت رفتاری به انسان، مساوی با حقوق انسانی است؟
قانونگذاری، شفافیت و نظارت
در پاسخ به این دغدغهها، سازمانهای مدنی، نهادهای بینالمللی و حتی خود شرکتهای فناوری، در تلاش برای تدوین چارچوبهایی برای توسعه مسئولانه و اخلاقمدار هوش مصنوعی هستند. اتحادیه اروپا در سال ۲۰۲۴ قانون جامع AI Act را تصویب کرد که استفاده از هوش مصنوعی را بر اساس سطح خطر (کمخطر، پرخطر، ممنوعه) طبقهبندی میکند. در ایالات متحده نیز گفتگوها برای نظارت بر مدلهای مولد و استفاده از آنها در انتخابات، آموزش، تبلیغات و تشخیص چهره شدت گرفته است. مسائلی مانند شفافیت الگوریتمی (Algorithmic Transparency)، قابلیت توضیحپذیری (Explainability) و مسئولیتپذیری نهادی نیز به مفاهیم کلیدی در آیندهپژوهی فناوری تبدیل شدهاند.
هوش مصنوعی در حال بازتعریف رابطه ما با ماشینها، با یکدیگر و حتی با خودمان است. اما برای بهرهبرداری از ظرفیتهای گسترده این فناوری، باید نهتنها از نظر فناورانه بلکه از لحاظ اجتماعی، اخلاقی، فلسفی و حقوقی نیز آماده باشیم. همانطور که تواناییهای هوش مصنوعی گسترش مییابد، محدودیتها، سوءتفاهمها و مخاطرات آن نیز باید با دقت شناسایی و مدیریت شوند.





