هوش مصنوعی گوگل در کمتر از 6 ساعت تراشه طراحی میکند
 تیم تحریریه
تیم تحریریه- ۱۶ اسفند ۱۳۹۹
طی کردن مراحل طراحی و ساخت محصول، فرایند زمانبری است که به چند هفته زمان نیاز دارد. بنابراین، تمام کارهای طراحی به دوش متخصصان است و باید از مدل یادگیری ماشین مناسبی که توان پیادهسازی طرح را در تراشه دارد، استفاده کنیم.»
محققان هوش مصنوعی گوگل میخواهند در روش پیشنهادیشان یک نمودار از گِیتهای منطقی، حافظه و چند چیز دیگر را در تراشه جایگذاری کنند؛ به گونهای که طرح بتواند به بهینهسازیِ قدرت، عملکرد و مساحت کمک کند و در عین حال به محدودیتهای ازدحام مسیریابی و تراکم جایگذاری پایبند باشد. اندازه نمودارها میتواند از چند میلیون تا چند میلیارد گره باشد که این گرهها در هزاران دسته قرار دارند.
[irp posts=”15895″]محققان چارچوبی طراحی کردهاند که برای بهینهسازیِ فرایند جایگذاری تراشه، از یک عامل که بوسیله یادگیری تقویتی آموزش می بیند، استفاده میکند. این مدل هوش مصنوعی با توجه به فهرست شبکهها، شناسۀ گره فعلی که قرار است جایگذاری شود، فرادادههای فهرست شبکه و فنآوری نیمههادی، یک توزیع احتمال برای نقاط جایگذاری موجود ارائه میکند.
عاملی که در فوق به آن اشاره شد، اجزا را به طور متوالی جایگذاری میکند، تا جایی که فهرست شبکهها را تکمیل کرده و تا پایان هیچ پاداشی دریافت نمیکند. برای اینکه عاملِ مورد نظر در انتخاب اجزا برای جایگذاری در وهله اول راهنمایی کافی بگیرد، اجزا به ترتیب اندازه از کم به زیاد چیده میشوند. جایگذاری اجزای بزرگتر در ابتدایِ کار باعث میشود بعدها امکان جایگذاری وجود نداشته باشد.
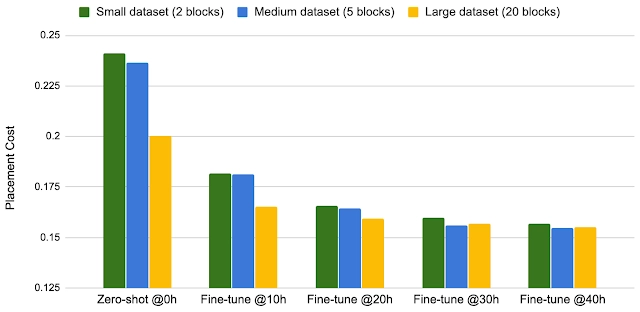
آموزشِ عامل (Agent)، مستلزمِ ساخت مجموعهدادهای متشکل از 10.000 جایگذاری تراشه بود. بر این اساس، ورودی به وضعیتی اشاره میکند که با جایگذاری ارتباط دارد و برچسب به منزلۀ پاداش برای جایگذاری است. محققان آن را با انتخاب 5 فهرست مختلف تراشه ساختهاند و یک الگوریتم هوش مصنوعی در آن به کار گرفته شده تا 2000 جایگذاری مختلف در هر فهرست شبکه، ممکن شود.
محققان بر اساس آزمایشها فهمیدند وقتی چارچوب را در تراشههای بیشتری آموزش دهند، میتوانند سرعت فرایند آموزش را افزایش دهند و سریعتر به نتایج بهتری برسند. در واقع، آنان مدعی شدهاند که این چارچوب توانست عملکرد بهتری در واحدهای پردازش تنسور (TPU)Tensor processing unit گوگل موسوم به «TPU» داشته باشد.
محققان در پایان نتیجه گرفتند: «برخلاف روشهای موجود که فرایند جایگذاری را از ابتدا در تراشههای جدید بهینهسازی میکنند، چارچوبِ ما از دانش بدست آمده از جایگذاری تراشههای پیشین استفاده میکند تا با گذشت زمان، خود را ارتقاء بخشد. افزون بر این، روش ما زمینه را برای بهینهسازیِ مستقیم متریکهایی از قبیل طول سیم، تراکم و ازدحام فراهم میکند. این روش نه تنها بهکارگیری توابع هزینه جدید را آسانتر میکند، بلکه این فرصت را در اختیارمان میگذارد تا اهمیت آنها را بر اساس نیازهای تراشه بسنجیم.»