
پردازش گفتار یکی از فناوریهای بنیادین هوش مصنوعی است که به ماشینها قدرت درک و پردازش گفتار انسانها را میدهد. اهمیت گفتار در برقراری ارتباط از یک سو و افزایش قدرت محاسبات سیستمهای هوشمند از سوی دیگر، رغبتی روزافزون جهت توسعه سیستمهای پردازش گفتار را ایجاد کرده است. با این حال مبهم بودن گفتار انسان، رشد این حوزه از فناوری را به چالش کشیده و تبدیل به یکی از پیچیدهترین زمینههای علوم کامپیوتر کرده است که علاوه بر علم کامپیوتر، مسائلی از قبیل زبانشناسی، ریاضیات و آمار را نیز در خود میگنجاند.
سیستمهای پردازش گفتار به واسطه تسهیل تعامل و برقراری ارتباط با ماشینها فواید زیادی را به همراه داشته و تاکنون در زمینههای مختلفی نظیر حملونقل، پزشکی، بازاریابی و فینتک مورد استفاده قرار گرفته است.
جهت آشنایی با این فناوری، ابتدا به معرفی پردازش گفتار؛ تاریخچه، اهداف، انواع و معیارهای ارزیابی این فناوری پرداخته میشود. سپس به کاربردهای این فناوری در زمینههای مختلف همراه با محصولات مبتنی بر پردازش گفتار اشاره میگردد. در نهایت با معرفی چندین کتاب مرجع، بستری برای فراگیری این فناوری ایجاد میگردد.ی پردازش کرده و معنای آن را درک کنند و علاوه بر آن نیت و احساس شخص را نیز متوجه شوند. NLP با پر کردن شکاف بین ارتباطات انسانی و درک ماشین از انسان، تعامل مؤثر بین انسان و کامپیوتر را تسهیل میکند. از چتباتها و دستیاران مجازی گرفته تا ترجمه زبان و تجزیه و تحلیل احساسات، NLP آینده فناوری و تعامل ما با آن را شکل میدهد.
تعریف پردازش گفتار: زبان مشترک انسان و ماشین
گفتار، یکی از روشهای آسان و کارآمد برقراری ارتباط و مبادله اطلاعات توسط انسانها به حساب میآید. اما درک و تولید آن برای ماشینها و کامپیوترها به سادگی انسانها نیست. قابلیتهای درک و تولید گفتار در ماشین تحت عنوان فناوری «پردازش گفتار» شناخته میشود.
پردازش گفتار (Speech Processing) فناوری پیچیدهای است که به کامپیوترها و دستگاههای هوشمند اجازه میدهد صدای انسان را تشخیص داده، تحلیل کنند و به آن پاسخ دهند. این فناوری شامل مجموعهای از الگوریتمها و تکنیکهاست که سیگنالهای صوتی را به دادههای قابلپردازش تبدیل میکند – درست مانند مترجمی که زبان انسان را به زبان ماشین ترجمه میکند.
اهمیت پردازش گفتار در چیست؟
در دنیای پرشتاب امروز، پردازش گفتار و ارتباط از طریق گفتار با کامپیوترها به بخش جداییناپذیر زندگی روزمره ما تبدیل شده است. ما روزانه از سرویسهای مبتنی بر پردازش گفتار استفاده میکنیم:
• دستیارهای صوتی هوشمند مانند سیری و الکسا که میلیونها نفر روزانه از آنها استفاده میکنند
• سیستمهای امنیتی بانکی که از صدای شما برای تأیید هویت استفاده میکنند
• خودروهای هوشمند که با دستورات صوتی کنترل میشوند
• سیستمهای پزشکی که به تشخیص بیماریهای گفتاری کمک میکنند
این فناوری نه تنها زندگی را راحتتر کرده، بلکه برای افراد دارای معلولیت نیز فرصتهای جدیدی ایجاد کرده است. برای مثال، افراد نابینا میتوانند با استفاده از فرمانهای صوتی، گوشیهای هوشمند خود را کنترل کنند.
جایگاه پردازش گفتار در هوش مصنوعی
پردازش گفتار یکی از ستونهای اصلی هوش مصنوعی مدرن است. این فناوری با بهرهگیری از یادگیری عمیق (Deep Learning)؛ شبکههای عصبی (Neural Networks)؛ پردازش زبان طبیعی (NLP) به سیستمهای هوشمند این امکان را میدهد که:
۱- صدای انسان را با دقتی نزدیک به ۹۵% تشخیص دهند
۲- متن را به گفتار و گفتار را به متن تبدیل کنند
۳- احساسات و حالات عاطفی را از طریق تُن صدا تشخیص دهند
امروزه، پردازش گفتار نقش کلیدی در توسعه سیستمهای هوش مصنوعی پیشرفته ایفا میکند. این فناوری به هوش مصنوعی اجازه میدهد تا به شکلی طبیعیتر با انسانها تعامل کند و درک عمیقتری از ارتباطات انسانی داشته باشد.
پردازش گفتار با پردازش صدا چه تفاوتی دارد؟
در بسیاری از موارد، سیستم پردازش گفتار با پردازش صدا (Voice Recognition) یکسان در نظر گرفته میشود. در حالی که این دو حوزه فناوری، اندکی با یکدیگر متفاوت هستند. تمرکز سیستمهای پردازش گفتار، بیشتر بر کلمات و عبارات گفتهشده میباشد که تبدیل گفتار از قالب کلامی به متن و انجام تجزیه و تحلیل بر روی آن یکی از برجستهترین کاربردهای این حوزه است. از طرف دیگر، هدف اصلی سیستمهای پردازش صدا، شناسایی و پردازش بخش صوتی گفتار است که میتوان به احراز هویت از طریق صوت در این زمینه اشاره کرد.
زنجیره گفتار؛ فرایند تولید و درک گفتار در انسان
گفتار با یک مفهوم و یا یک ایده در ذهن گوینده آغاز میشود. این ایده، لازم است به کدهای زبانی تبدیل شود. سپس سیگنالهای الکتروشیمیایی ایجاد شده از طریق اعصاب حرکتی، عضلات صوتی دهان را فعال کرده و گفتار تولید میشود.
گفتار تولید شده به عنوان امواج صوتی به سمت گوش شنونده حرکت کرده و در آنجا به سیگنالهای الکتروشیمیایی تبدیل شده و از طریق اعصاب حسی به مغز شنونده ارسال میگردد و طی فرایند دکدینگ کدهای زبانی، مفهوم یا ایده اصلی را بازسازی مینماید. به طور همزمان، به عنوان بازخورد، این امواج صوتی به گوش گوینده نیز برمیگردد. این بازخورد به گوینده کمک میکند که با تنظیم دقیق و پیوسته حرکات ظریف اندامهای صوتی به تولید گفتار قابلفهمتر بپردازد.
در هنگام گفتوگو، بسیاری از اتفاقات به وقوع پیوسته جهت پردازش گفتار در مغز گوینده و شنونده همچنان ناشناخته باقیمانده است. اما ساختار زبان توانسته راهنمایی تقریبی برای دستیابی به این اطلاعات را فراهم نماید. زبانشناسان، گفتار را به سطوح مختلف زبان متشکل از معناشناسی (semantic)، نحو (Syntax)، واژهخوانی (lexicon)، ریختشناسی (morphology)، آواشناسی phonetics)) و صوتشناسی (acoustics) تقسیمبندی کردهاند که هر لایه، دانش مورد نظر لایههای بالاتر را پس از انجام عملیات مربوطه به لایههای زیرین نگاشت میکند.
کدگذاری زبانی در ذهن، از مدل دانشی world knowledge افراد آغاز میشود. این مدل دانشی مجموعهای از تمامی حقایقی است که فرد در مورد محیط اطراف خود دارد. به عنوان نمونه، اطلاعاتی مبنی بر اینکه انسانها در خانه زندگی میکنند و یا زرافه حیوانی چهارپا با گردنی بلند است، جز مدل دانشی انسان محسوب میشود.
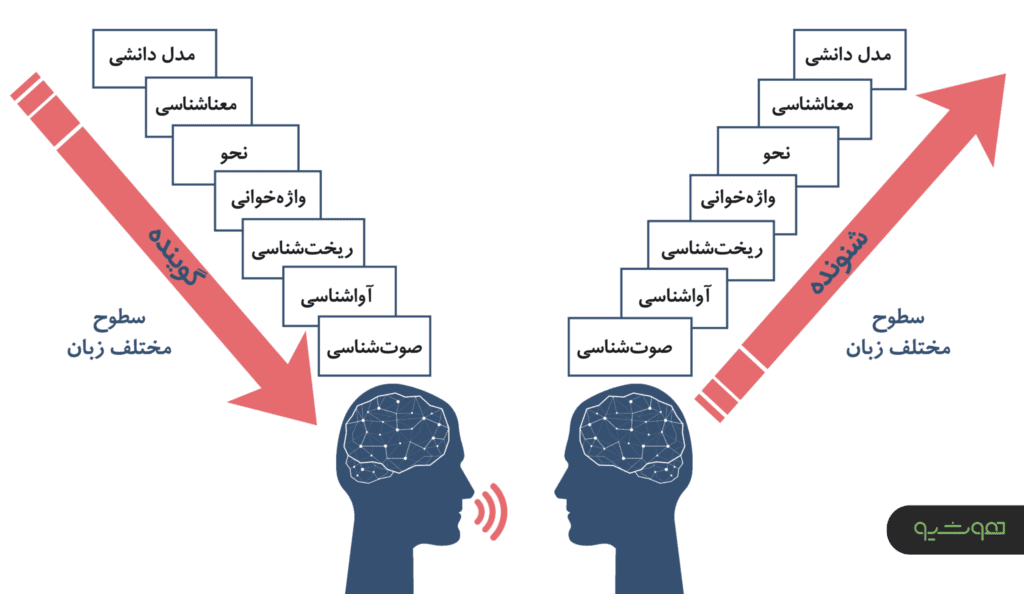
نحوه کار سیستمهای پردازش گفتار
سیستمهای پردازش گفتار به طور معمول دارای یک فرایند چندمرحلهای هستند. ابتدا، ویژگیهای مربوطه از سیگنال گفتار استخراج میشوند. سپس، مدلهای مرجع با استفاده از این ویژگیها طراحی مییابند. در مرحله سوم، بردارهای ویژگی استخراج شده از گفتار به مدلهای مرجع ارسال میشوند.
لازم است مدلهای مرجع برای هر واحد صدا (واج) ایجاد شوند. مدلی که بالاترین میزان اطمینان را ایجاد میکند، هویت واحد صدا را نشان میدهد. همچنین، توالی واحدهای صوتی شناسایی شده با استفاده از مدلهای زبانی اعتبارسنجی میشود. به عبارت دیگر، از مدلهای زبانی برای تبدیل دنباله واحدهای صوتی به متن استفاده میشود.
مراحل اصلی پردازش گفتار
گام ۱
تبدیل صدا به سیگنال دیجیتال
در این مرحله، سیگنالهای آنالوگ صوتی به دادههای دیجیتال تبدیل میشوند. این فرآیند شامل نمونهبرداری، کوانتیزاسیون و کدگذاری است.
گام ۲
پیشپردازش و حذف نویز
سیستمهای مدرن از الگوریتمهای پیشرفته برای حذف نویزهای محیطی و بهبود کیفیت سیگنال استفاده میکنند. این مرحله برای افزایش دقت تشخیص بسیار حیاتی است.
گام ۳
استخراج ویژگیهای صوتی
در این مرحله، ویژگیهای مهم صوتی مانند:
• فرکانس پایه
• فرمنتها
• انرژی سیگنال
• ضرایب کپسترال استخراج میشوند.
گام ۴
تحلیل و تفسیر دادهها
دادههای استخراج شده با استفاده از مدلهای آماری و الگوریتمهای یادگیری ماشین تحلیل میشوند.
رویکردهای پردازش گفتار
از نظر مفهومی، رویکردهای ایجاد سیستمهای پردازش گفتار به دو نوع مبتنی بر الگو و یا مدل تقسیمبندی میشوند. در رویکرد مبتنی بر الگو، ابتدا سیستم با استفاده از الگوهای گفتاریِ شناخته شده آموزش داده میشود. سپس، با مقایسه سیگنالهای گفتاری ناشناخته با الگوهای احتمالی آموخته شده در مرحله آموزش، پردازش انجام میشود.
توالی احتمالی کلمات که فاصله بین الگوهای ناشناخته و الگوی شناخته شده را به حداقل میرساند، به عنوان توالی بهینه انتخاب میشود. الگوریتم پیچش زمانی پویا Dynamic Time Warping (DTW) و کوانتیزاسیون برداری vector quantization (VQ) از جمله روشهای رایج در این زمینه هستند. در سیستمهای مبتنی بر مدل، ویژگیهای مناسب برای هر واحد صدا (واج) از دادههای آموزش استخراج میشوند. لازم است مدلهای مرجع برای هر واحد صدا ایجاد شوند.
از روشهای متداول این نوع از مدلسازی میتوان به این موارد اشاره کرد که از این بین مدلهای پنهان مارکوف و شبکههای عصبی از مدلهای رایج پردازش گفتار هستند:
• مدل پنهان مارکوف Hidden Markov Model (HMM)
• مدل مخلوط گوسی Gaussian Mixture Model (GMM)
• شبکه عصبی Neural Network (NN)
• ماشین بردار پشتیبان Support Vector Machine (SVM)
مدلهای پنهان مارکوف و شبکههای عصبی در پردازش گفتار
پس از دریافت سیگنالهای گفتاری و تبدیل آنها به سیگنالهای دیجیتال، به طور معمول از مدلهای پنهان مارکوف و یا شبکههای عصبی جهت پردازش گفتار استفاده میشود که در ادامه هر یک از این روشها به زبان بسیار ساده، شرح داده میشود.
بسیاری از سیستمهای بازشناسی گفتار بر اساس مدلهای پنهان مارکوف بنا شدهاند. روش HMM که بر اساس اصول احتمالات عمل میکند، پردازش گفتار را در سه سطح کلی انجام میدهد. در سطح نخست، شناسایی واجها و یا واحدهای صدا انجام میگیرد.
در مرحله دوم، توالی واجها و ساخت کلمات مورد بررسی قرار میگیرد. بدین منظور، واجهایی که در کنار هم بیشترین احتمال را دارند، انتخاب شده و کلمات را تشکیل میدهند. هدف مرحله سوم، ایجاد توالی بهینه کلمات و ایجاد جمله است. در این مرحله احتمال وجود فعلها، اسمها، قید و یا صفت در کنار هم ارزیابی میشود و ترکیبی که دارای بیشترین احتمال است به عنوان گزینه نهایی انتخاب میگردد. از مزایای این روش دقت بالای آن در شناسایی توالی کلمات است. با این حال در شناسایی واجها با تلفظها و یا لهجههای مختلف دارای انعطاف کمی میباشد.
شبکههای عصبی همانطور که از نامش نیز مشخص است، شبکههایی از گرههای به هم پیوسته میباشد که نحوه عملکرد آن مشابه با مغز انسان است. ارتباطات بین این گرهها توسط شاخص وزنها مشخص میشود که با آموزش شبکه، مقدار آنها به طور بهینه تعیین میگردد. انعطافپذیری بالا از مزیتهای ارزشمند این روش است.
ارزیابی سیستمهای تشخیص گفتار
به طور کلی، عملکرد سیستمهای تشخیص گفتار از نظر میزان دقت و سرعت ارزیابی میشوند. عواملی نظیر تلفظ، لهجه، اندازه واژگان، نوع صدا، بلندی صدا و صدای پسزمینه میتوانند بر این معیارها تأثیر بگذارند.
یکی از معیارهای برجسته جهت ارزیابی سیستمهای تشخیص گفتار، تعداد کلمات در گفتار است که به درستی تشخیص داده شود. به طور معمول سیستمهای تشخیص گفتار سه نوع خطای تشخیص کلمه با عناوین جایگزینی (substitution)، درج (insertion) و حذف (deletion) را تجربه میکنند.
• خطای جایگزینی: این نوع از خطا زمانی رخ میدهد که یک کلمه در عبارت به عنوان یک کلمه متفاوت دیگر رونویسی میشود.
• خطای درج: به مواقعی اشاره دارد که کلمهای که در رونویسی ظاهر میشود در گفتار مورد نظر نباشد.
• خطای حذف: این خطا زمانی رخ میدهد که یک کلمه در گفتار به طور کامل در رونویسی از دست رفته باشد.
میزان خطای کلمه (WER) به عنوان نسبت مجموع هر سه نوع خطا به تعداد کل کلمات موجود در رونوشت مرجع تعریف میشود. سیستمهایی با WER کوچکتر بر سیستمهایی با WER بزرگتر ارجحیت دارند.
از سوی دیگر، عامل زمان واقعی Real Time Factor (RTF) یکی از معیارهای سنجش سرعت سیستمهای پردازش گفتار است که سرعت رمزگشایی یک سیستم بازشناسی خودکار گفتار را نشان میدهد.
این شاخص نسبت زمان تشخیص گفتار به کل مدتزمان بیان را اندازهگیری مینماید. به طور معمول، میانگین این شاخص (برای تمامی گفتهها) و صدک 90ام آن جهت ارزیابی عملکرد این نوع از سیستمها مورد استفاده قرار میگیرد.
کاربردهای پردازش گفتار
تاریخچه پردازش گفتار: سفری از صدا به هوش مصنوعی
پردازش گفتار، داستان شگفتانگیز تلاش انسان برای آموزش «شنیدن» و «درک» به ماشینهاست. بیایید با هم نگاهی به این سفر جذاب بیندازیم:
نخستین گامها (دهه ۱۹۳۰-۱۹۴۰)
نخستین تلاشها برای پردازش گفتار آغاز شد. در این زمان، آلن تورینگ مقاله معروف خود را درباره آزمایش تورینگ منتشر کرد که به طور غیرمستقیم به چالشهای درک زبان طبیعی توسط ماشینها اشاره داشت. این دهه، دورهای بود که پژوهشگران به دنبال یافتن راههایی برای ترجمه ماشینی و درک گفتار انسان توسط کامپیوترها بودند.
در این دوران، دانشمندان با ساخت دستگاههای سادهای که میتوانستند صداهای پایه را تشخیص دهند، اولین قدمها را برداشتند. آزمایشگاه بل (Bell Labs) با ساخت دستگاه «Voder»، اولین ماشین سنتز گفتار را معرفی کرد – هرچند صدایش بیشتر شبیه رباتهای علمی – تخیلی بود.
نخستین گامها (دهه ۱۹۳۰-۱۹۴۰)
عصر طلایی آغازین (دهه ۱۹۵۰-۱۹۶۰)
• آزمایشگاههای بل اولین سیستم تشخیص گفتار به نام «آدری» را ساخت که قادر بود اعداد تکرقمی 1 تا 9 را تشخیص دهد.

• شرکت آیبیام، دستگاه «IBM Shoebox» را در نمایشگاه جهانی 1962 معرفی کرد، این دستگاه قادر بود 16 کلمه را بفهمد که در آن زمان اینس دستگاه را به پیشرفتهترین سیستم تشخیص گفتار در جهان تبدیل میکرد.

• دانشمندان شروع به درک اهمیت فرکانسها و الگوهای صوتی کردند
عصر طلایی آغازین (دهه ۱۹۵۰-۱۹۶۰)
دوران بلوغ (دهه ۱۹۷۰-۱۹۸۰)
• معرفی مدل مارکوف پنهان (Hidden Markov Models) انقلابی در پردازش گفتار ایجاد کرد
• DARPA پروژههای بزرگی را برای تشخیص گفتار آغاز کرد. برنامه تحقیق برای درک گفتار (Speech Understanding Research) در نهایت منجر به توسعه سیستم هارپی (Harpy) شد.
• «کارنگی ملون» بر اساس نتایج دارپا موفق به توسعه هارپی شد که میتوانست 1011 کلمه یا واژگان را بفهمد. این مجموعه کلمات داره واژگان یک کودک سه ساله را شامل میشد.
• در این دهه، تمرکز بر توسعه هستیشناسیهای مفهومی بود که اطلاعات دنیای واقعی را به دادههای قابلفهم برای کامپیوتر تبدیل میکردند. این دوره شاهد ظهور اولین رباتهای گفتگو نیز بود که تلاش میکردند تعاملات پیچیدهتری با کاربران داشته باشند.
دوران بلوغ (دهه ۱۹۷۰-۱۹۸۰)
انقلاب دیجیتال (دهه ۱۹۹۰)
• کامپیوترهای شخصی قدرتمندتر شدند
• نرمافزارهای تشخیص گفتار مانند Dragon NaturallySpeaking وارد بازار شدند
• دقت تشخیص گفتار به طور چشمگیری افزایش یافت و شاهد استفادههای تجاری از این تکنولوژی بودیم.
انقلاب دیجیتال (دهه ۱۹۹۰)
عصر هوش مصنوعی (۲۰۰۰-۲۰۱۰)
• با رشد وب و دسترسی به حجم عظیمی از دادههای خام، تحقیقات به سمت الگوریتمهای یادگیری بدون نظارت و نیمه نظارت متمرکز شد. این الگوریتمها توانستند از دادههای بدون برچسب برای بهبود مدلهای پردازش گفتار استفاده کنند.
• گوگل موتور جستجوی صوتی خود را معرفی کرد
عصر هوش مصنوعی (۲۰۰۰-۲۰۱۰)
انقلاب دستیارهای صوتی (۲۰۱۰ تا کنون)
• سیری اپل در ۲۰۱۱ معرفی شد و دنیا را شگفتزده کرد
• الکسای آمازون (۲۰۱۴) بازار را متحول کرد
• گوگل اسیستنت (۲۰۱۶) با قابلیتهای پیشرفته معرفی شد
• شبکههای عصبی عمیق دقت تشخیص گفتار را به سطح انسانی رساندند
انقلاب دستیارهای صوتی (۲۰۱۰ تا کنون)
آینده پردازش گفتار
امروزه، پردازش گفتار به بخش جداییناپذیر زندگی ما تبدیل شده است. از دستیارهای صوتی که چراغهای خانه را روشن میکنند تا سیستمهای پیچیدهای که میتوانند مکالمات طبیعی داشته باشند. آینده این فناوری حتی هیجانانگیزتر به نظر میرسد:
• هوش مصنوعی قادر به درک احساسات از طریق صدا
• مترجمهای همزمان با دقت بالا
• تعامل طبیعیتر با ماشینها
• سیستمهای تشخیص گفتار با دقت ۹۹.۹٪
آینده پردازش گفتار
فناوری پردازش گفتار یکی از فناوریهای رو به رشد است که توانسته اعتماد بسیاری از افراد و کسبوکارها را جذب نماید. این فناوری به کاربران این امکان را میدهد که بتوانند درخواستها و دغدغههایشان را با ماشینهای هوشمند به اشتراک گذارند. همچنین سیستمهای مجهز به پردازش گفتار غالباً با تبدیل درخواستهای افراد به متن و پردازش آنها، میتوانند پاسخ مناسبی را به آنها ارائه دهند. در ذیل به برخی از مهمترین کاربردهای پردازش گفتار در زمینههای مختلف اشاره میشود.
کاربردهای تجاری
دستیارهای صوتی هوشمند
سیری، الکسا و گوگل اسیستنت که امکان ارائه خدمات به صورت 24 ساعته را فراهم میکنند.
سیستمهای پاسخگویی خودکار
در مراکز تماس و خدمات مشتری
خدمات مشتری مبتنی بر صدا
سیستمهای پاسخگویی هوشمند و چتباتهای صوتی
کاربردهای پزشکی
تشخیص بیماریهای گفتاری
شناسایی اختلالات گفتاری در مراحل اولیه
کمک به افراد دارای مشکلات شنوایی
سمعکهای هوشمند و سیستمهای کمکشنوایی
توانبخشی گفتار
برنامههای آموزشی و درمانی برای بهبود گفتار
کمک به معاینه بیمار
در طول معاینات بیمار، دیگر نیاز نیست پزشکان و یا سایر کادر درمان وقت خود را صرف یادداشتبرداری از علائم بیماران کنند. بلکه میتوان از نرمافزارهای مبتنی بر پردازش گفتار برای ضبط یادداشتهای مربوط به بیمار استفاده کرد. به لطف این فناوری، پزشکان میتوانند میانگین قرار ملاقات را کوتاه کرده تا در ساعات کاری خود به بیماران بیشتری مراجعه کنند.
تشخیص وضعیت روحی و روانی
ماشینهای هوشمند میتوانند با تجزیه و تحلیل صدای فرد، وضعیت روانی او را تخمین بزنند. به عنوان نمونه، تاکنون از این مدلها در تخمین اینکه آیا بیمار افسرده است یا قصد خودکشی دارد، استفاده شده است.
کاربردهای امنیتی
تشخیص هویت از طریق صدا
سیستمهای احراز هویت صوتی
سیستمهای نظارتی صوتی
تشخیص صداهای غیرعادی و هشدار
تشخیص تقلب صوتی
شناسایی صداهای جعلی و دستکاری شده
کاربردهای عمومی پردازش گفتار
ترجمه آنلاین و یا ایجاد زیرنویس خودکار
امروزه محتواهای زیادی به زبانهای مختلف تولید میشود که افراد علاقهمند به استفاده از آنها هستند؛ اما زبان آن را متوجه نمیشوند. متخصصان هوش مصنوعی توانستند با بهرهگیری از الگوریتمها، نرمافزارها و پلتفرمهای مجهز به پردازش گفتار، در لحظه این محتواها را به زبان دلخواه ترجمه کنند.
سیستمهای پردازش گفتار داخل خودرو
امروز به یک ویژگی استاندارد برای اکثر خودروهای مدرن تبدیل شده است. هدف این سیستمها، حذف حواسپرتی حاصل از نگاه کردن به تلفن همراه در حین رانندگی است. به کمک این سیستمها، رانندگان میتوانند از دستورات صوتی ساده برای شروع تماسهای تلفنی، اخذ راهنمایی جهت یافتن مسیر مناسب، انتخاب کانال رادیویی مورد نظر و یا پخش موسیقی استفاده کنند.
چالشها و محدودیتهای پردازش گفتار
پردازش گفتار، با وجود پیشرفتهای چشمگیر، همچنان با چالشها و محدودیتهای متعددی روبرو است. مقابله با نویز محیطی، تنوع لهجهها و زبانها، و محدودیتهای فنی، نیازمند تحقیق و توسعه مستمر است. با این حال، با پیشرفتهای مداوم در فناوری و الگوریتمهای نوین، میتوان امیدوار بود که این چالشها به مرور زمان کاهش یابند و پردازش گفتار به ابزاری قدرتمندتر و کارآمدتر تبدیل شود.
نویز محیطی: تأثیر منفی صداهای محیطی بر دقت تشخیص
یکی از بزرگترین چالشها در پردازش گفتار، مقابله با نویزهای محیطی است. صداهای پسزمینه، مانند صدای ترافیک، باد، یا حتی مکالمات دیگر، میتوانند به شدت دقت سیستمهای تشخیص گفتار را کاهش دهند. این نویزها باعث میشوند که سیستم نتواند به درستی گفتار را از سایر صداها تفکیک کند که منجر به اشتباهات در تشخیص و تحلیل گفتار میشود.
راهکارهای مقابله با نویز محیطی:
• فیلترهای دیجیتال: استفاده از فیلترهای تطبیقی برای حذف نویزهای خاص
• میکروفونهای جهتدار: تمرکز بر منبع صدای اصلی و کاهش نویزهای اطراف
• الگوریتمهای حذف نویز: توسعه الگوریتمهای پیشرفته برای تشخیص و حذف نویز
تنوع لهجهها و زبانها: چالشهای مرتبط با تنوع زبانی و لهجهای
تنوع زبانی و لهجهای یکی دیگر از موانع بزرگ در پردازش گفتار است. هر زبان دارای لهجهها و گویشهای مختلفی است که میتواند بر دقت سیستمهای تشخیص تأثیر بگذارد. این مسئله به ویژه در سیستمهای چندزبانه که باید قادر به تشخیص و تحلیل گفتار در زبانها و لهجههای مختلف باشند، چالشبرانگیز است.
راهکارهای مقابله با تنوع زبانی و لهجهای:
• مدلهای چندزبانه: توسعه مدلهایی که بتوانند چندین زبان و لهجه را پشتیبانی کنند
• یادگیری انتقالی: استفاده از دادههای یک زبان برای بهبود عملکرد در زبانهای دیگر
• پایگاههای داده گسترده: جمعآوری و استفاده از دادههای گفتاری متنوع برای آموزش مدلها
محدودیتهای فنی: محدودیتهای پردازشی و حافظه
محدودیتهای فنی، به ویژه در زمینه پردازش و حافظه، یکی دیگر از چالشهای اصلی در پردازش گفتار است. سیستمهای تشخیص گفتار نیازمند پردازش سریع و دقیق حجم زیادی از دادهها هستند که این امر به قدرت محاسباتی بالا و حافظه زیادی نیاز دارد. این محدودیتها میتوانند عملکرد سیستمها را در دستگاههای با منابع محدود، مانند تلفنهای همراه یا دستگاههای اینترنت اشیاء، تحت تأثیر قرار دهند.
راهکارهای مقابله با محدودیتهای فنی:
• فشردهسازی دادهها: استفاده از تکنیکهای فشردهسازی برای کاهش حجم دادهها
• پردازش ابری: انتقال بخشی از پردازش به سرورهای ابری برای کاهش بار محاسباتی دستگاههای محلی
• الگوریتمهای بهینهسازی: توسعه الگوریتمهایی که با منابع محدود کارایی بالایی داشته باشند
انواع سیستمهای پردازش گفتار
پردازش گفتار غالباً با هدف استخراج اطلاعات، فهم، پردازش و دستهبندی فایلهای صوتی انجام میشود و در موارد مختلفی نظیر تبدیل دادههای صوتی به متن قابل ویرایش و برعکس، شناسایی کلیدواژهها، تشخیص حالات و احساسات و دستیارهای صوتی کاربرد دارد.
با توجه به نوع کارکرد سیستمهای پردازش گفتار، این سیستمها قابل دستهبندی به گروههای پایه، بازشناسی خودکار گفتار، تحلیل صوت، سنتز گفتار و موسیقی میباشند که در ذیل به تشریح هر یک از این موارد پرداخته میشود.

سیستمهای پردازش گفتار پایه
هدف از ارائه این سیستمها، آمادهسازی و بهسازی فایلهای صوتی برای پردازش توسط سایر سیستمهای پردازش گفتار است. فعالیتهای زیر به طور معمول توسط این سیستمها انجام میشود.
• حذف نویز موجود در صوت Denoising
• آشکارسازی فعالیت صوتی Voice Activity Detection
• جداسازی صوت Speech Seperation
• دستهبندی صدا Audio Classification
سیستمهای بازشناسی خودکار گفتار
ماشین به واسطه فناوری بازشناسی گفتار این توانایی را دارد که پس از دریافت فایلهای صوتی، گفتار آن را متوجه شود. این امر منجر به وجود قابلیتهای مختلفی از جمله آرشیوسازی و جستجوی فایلهای صوتی در سیستمهای هوشمند میشود.
در انسانها به دلیل وجود پیوستگی در گفتار، اگر فردی تنها بخشی از گفتههای فرد گوینده را بشنود، میتواند به واسطه پیوستگی در حروف، هجاها، کلمات و جملات، مابقی گفتار را نیز پیشبینی کند. ایجاد این قابلیت در ماشینها به واسطه این سیستمها میتواند تأثیر ارزشمندی در این حوزه ایجاد نماید. برخی از فعالیتهای عمدهای که در این دسته انجام میشوند، به شرح زیر میباشد:
• تبدیل صوت یا گفتار به متن قابل ویرایش Speech to Text
• تشخیص کلیدواژه Keyword Spotting
سیستمهای تحلیل صوت
با توجه به عبارات و لحن استفاده شده در گفتار افراد در کنار سایر ویژگیهای صوتی میتوان ویژگیهای گوینده و نوع گفتار او را تحلیل نمود. به طور کلی، برخی از کارکردهای مهم این نوع از سیستمها به شرح زیر میباشند:
• تشخیص احساس، سن و جنسیت Emotion, Gender and Age Recognition
• تشخیص زبان گفتار Language Identification
• تشخیص و تأیید گوینده Speaker Identification and Verfifcation
• تعیین نوع بیان جمله
• تشخیص میزان هوشیاری یا خوابآلودگی Fatigue Detection
سیستمهای سنتز گفتار
پردازش گفتار، قابلیت ایجاد یک فایل صوتی سفارشی همراه با احساس مورد نظر را دارد. تبدیل متن به گفتار، یکی از برجستهترین کاربردها در این زمینه است که میتواند در موارد مختلف از جمله خواندن اخبار و یا چتباتها مورد استفاده قرار گیرد.
همچنین تبدیل صوت افراد دارای اختلالات گفتاری، به شیوهای قابلفهم، از دیگر قابلیتهای پردازش گفتار در این زمینه است. به طور کلی، کارکرد سیستمهای سنتز گفتار شامل موارد زیر میتواند باشد:
• تبدیل متن به گفتار Text to Speech
• تبدیل صوت Voice Conversion
• تغییر و یا افزودن احساس دلخواه به صوت Emotional Speech Generation
• تولید گفتار سفارشی با صدای فرد مورد نظر Voice Cloning
سیستمهای مربوط به موسیقی
علاوه بر قابلیت بازشناسی، تحلیل و تولید گفتار میتوان از سیستمهای پردازش گفتار در تولید موسیقی و یا تجزیه و تحلیل اثرهای موسیقایی نیز بهره برد. قابلیتهای ارائه شده در این زمینه عبارتند از:
• تولید موسیقی Music Generation
• تشخیص آلات موسیقی Instrument Recognition
• تشخیص ژانر موسیقی Genre Recognition
• تشخیص مود و احساس موسیقی Mood Recognititon
• شناسایی آهنگساز Composer recognition
• یافتن شباهت دو اثر موسیقی
سیستمهای تعاملی
امروزه سرویسهای تعاملی نظیر دستیاران صوتی یکی از رایجترین محصولات در هوش مصنوعی هستند که در جوانب مختلف زندگی بشر مورد استفاده قرار میگیرند. پردازش گفتار یکی از پیشنیازهای اساسی اینگونه از سیستمها جهت تعامل با انسانهاست.
سخن پایانی
پردازش گفتار از یک رویای علمی – تخیلی به واقعیتی روزمره تبدیل شده است. این فناوری نه تنها نحوه تعامل ما با دستگاهها را تغییر داده، بلکه دریچهای به سوی آیندهای باز کرده که در آن، صحبت کردن با ماشینها به اندازه صحبت با انسانها طبیعی خواهد بود.
این سفر هنوز ادامه دارد و هر روز شاهد نوآوریهای جدیدی در این حوزه هستیم. آینده پردازش گفتار، آیندهای است که در آن مرز بین انسان و ماشین در ارتباطات کلامی کمرنگتر و کمرنگتر میشود.
