
گزارش شاخص تسلط بر هوش مصنوعی Anthropic
 سید محمدجواد فیاض
سید محمدجواد فیاض- ۶ اسفند ۱۴۰۴
صرف پذیرش ابزارهای هوش مصنوعی چیز زیادی درباره تأثیرشان به ما نمیگوید. پرسش مهمتر و به همان اندازه اساسی این است: آیا با جاافتادن هوش مصنوعی در زندگی روزمره، افراد مهارتهای لازم برای استفاده مؤثر از آن را نیز کسب میکنند؟
به نقل از بلاگ Anthropic، گزارشهای پیشین آموزش Anthropic نحوه استفاده دانشجویان و استادان دانشگاه از Claude را بررسی کرده بودند. یافتهها نشان داد که دانشجویان از Claude برای تهیه گزارش و تحلیل نتایج آزمایشگاهی و استادان برای ساخت محتوای درسی و خودکارسازی کارهای روتین استفاده میکنند.
روششناسی
اما میدانیم که هر کسی که از هوش مصنوعی استفاده کند، به احتمال زیاد در کار خود پیشرفت خواهد کرد. میخواستیم این موضوع را عمیقتر بررسی کنیم و بفهمیم چگونه کاربران هوش مصنوعی بهمرورزمان به این فناوری تسلط پیدا میکنند. در این گزارش، به پاسخ به این پرسش میپردازیم. ما حضور یا عدم حضور مجموعهای از رفتارها را که آنها را نمایانگر تسلط بر هوش مصنوعی میدانیم، در نمونه بزرگی از مکالمات ناشناسسازیشده ردیابی کردیم.
رایجترین نمود تسلط بر هوش مصنوعی بهنوعی «تکمیلی» (Augmentative) است؛ یعنی نگاه به هوش مصنوعی بهعنوان یک شریک فکری، نه واگذاری کامل کار به آن. در واقع، اینگونه مکالمات بیش از دو برابر گفتگوهای کوتاه و سریع، نشانههای رفتاری تسلط بر هوش مصنوعی را نشان میدهند. اما همچنین دریافتیم که وقتی هوش مصنوعی خروجی Artifact مانند اپلیکیشن، کد، سند، یا ابزارهای تعاملی تولید میکند؛ کاربران کمتر احتمال دارد استدلال آن را زیر سؤال ببرند (۱/۳ درصد) یا زمینههای ناقص را شناسایی کنند (۲/۵ درصد). این الگو با یافتههای مرتبطی که در مطالعه اخیرمان درباره مهارتهای کدنویسی مشاهده کردیم همراستاست.
این یافتههای اولیه، یک خط مبنا به دست میدهند که میتوانیم از آن برای مطالعه رشد تسلط بر هوش مصنوعی در طول زمان استفاده کنیم.
سنجش تسلط بر هوش مصنوعی
برای کمّیسازی تسلط بر هوش مصنوعی، از «چارچوب تسلط چهاربُعدی بر هوش مصنوعی» (4D AI Fluency Framework) استفاده میکنیم که توسط «ریک داکان» (Rick Dakan) و «جوزف فلر» (Joseph Feller) در همکاری با Anthropic توسعه داده شده است. این چارچوب به ما کمک میکند تا ۲۴ رفتار مشخص را که آنها را نمونه همکاری ایمن و مؤثر انسان با هوش مصنوعی میدانیم، تعریف کنیم.
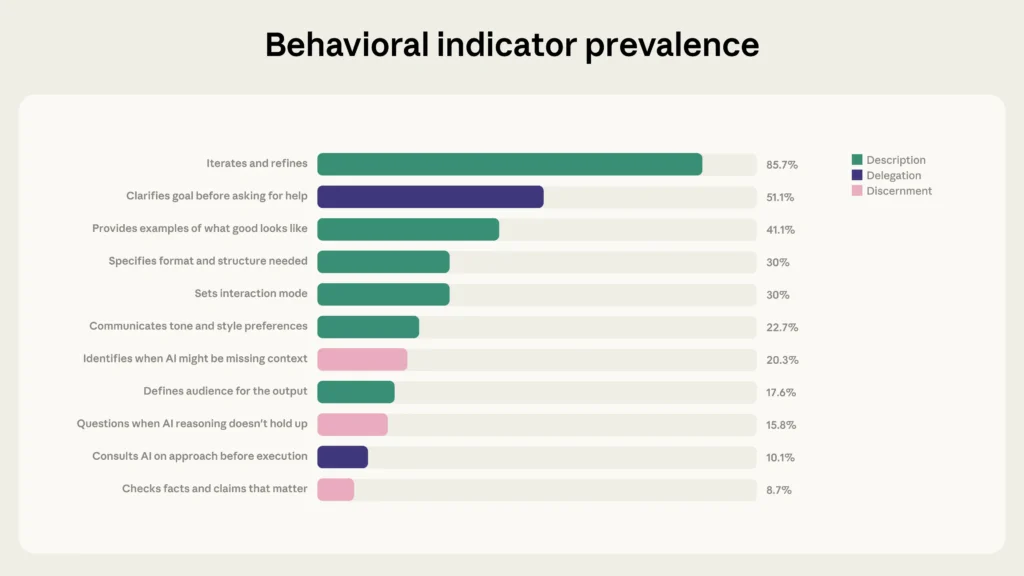
از این ۲۴ رفتار، ۱۱ مورد که در نمودار ۱ فهرست شدهاند هنگام تعامل کاربران با Claude در Claude.ai یا Claude Code به طور مستقیم قابلمشاهده هستند. ۱۳ رفتار دیگر از جمله صادقبودن درباره نقش هوش مصنوعی در کار یا سنجیدن پیامدهای اشتراکگذاری خروجیهای تولیدشده توسط هوش مصنوعی؟ خارج از رابط گفتگوی Claude.ai رخ میدهند و ردیابی آنها بسیار دشوارتر است. این رفتارهای غیرقابلمشاهده بحثبرانگیز از مهمترین ابعاد تسلط بر هوش مصنوعی هستند؛ ازاینرو در پژوهشهای آینده قصد داریم از روشهای کیفی برای ارزیابی آنها بهره بگیریم.
در این مطالعه، تمرکز Anthropic بر ۱۱ رفتار مستقیماً قابلمشاهده بود. از ابزار تحلیل حفظ حریم خصوصی Anthropic برای بررسی ۹٬۸۳۰ مکالمه استفاده شد که طی یک بازه هفتروزه در ژانویه ۲۰۲۶ شامل چندین ردوبدل با Claude در Claude.ai بودند. سپس حضور یا غیاب ۱۱ رفتار اندازهگیری شد؛ هر مکالمه میتوانست نشانههای چندین رفتار را نشان دهد. پایایی نمونه با بررسی ثبات نتایج در هر روز هفته و در زبانهای مختلف موجود در نمونه تأیید و ثابت شد. در نهایت، شاخص تسلط بر هوش مصنوعی حاصل شد؛ یک اندازهگیری پایهای از چگونگی همکاری امروز کاربران با هوش مصنوعی و ساختاری برای ردیابی تحول این رفتارها در طول زمان با تغییر مدلها.
نتایج
در این اولین مطالعه، دو الگوی اصلی در استفاده از Claude شناسایی کردیم؛ رابطه قوی میان تسلط بر هوش مصنوعی و تکرار و اصلاح از طریق مکالمات طولانیتر با Claude و تغییر رفتارهای کاربران هنگام کدنویسی یا ساخت دیگر خروجیها.
تسلط با مکالماتی که تکرار و اصلاح دارند، ارتباط قوی دارد
یکی از قویترین الگوها، رابطه میان تکرار و اصلاح و سایر رفتارهای تسلط بر هوش مصنوعی است. ۸۵.۷ درصد از مکالمات نمونه نشانههای تکرار و اصلاح را داشتند؛ یعنی بر پایه تبادلهای پیشین ادامه دادند تا کار کاربر را اصلاح کنند، نه اینکه اولین پاسخ را بپذیرند و سراغ موضوع جدیدی بروند. این مکالمات نرخهای بهمراتب بالاتری از سایر رفتارهای تسلط را نشان دادند، همانطور که نمودار زیر مینماید:
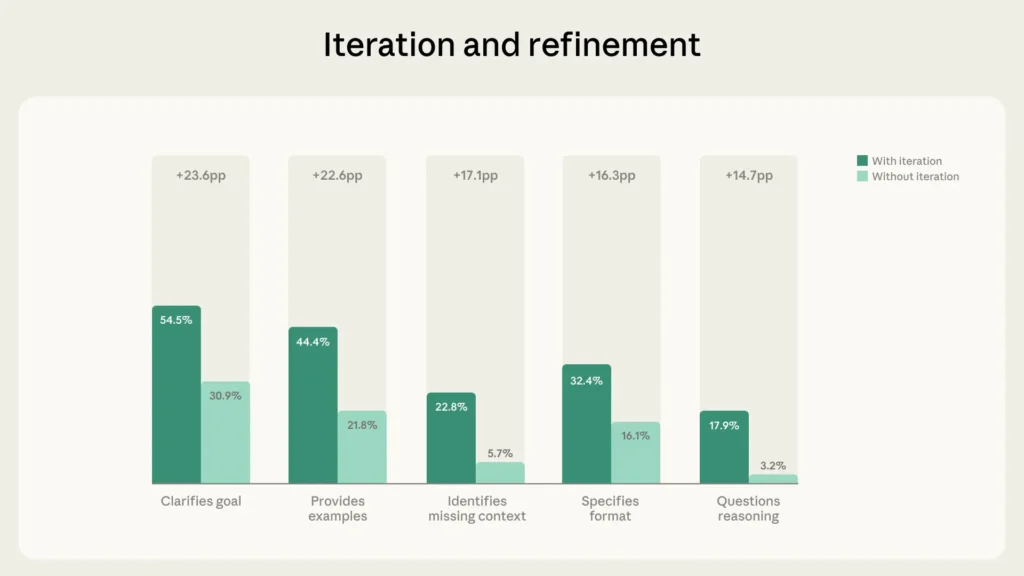
به طور میانگین، مکالمات با تکرار و اصلاح ۲.۶۷ برابر بیشتر نشاندهنده تسلط کاربر هستند؛ تقریباً دو برابر نرخ ۱.۳۳ برابری برای مکالمات غیرتکرارشونده. این تفاوت برای رفتارهای مرتبط با ارزیابی خروجیهای Claude برجستهتر است. مکالمات با تکرار و اصلاح ۵.۶ برابر بیشتر احتمال دارد که در آن کاربر استدلال Claude را زیر سؤال ببرد و ۴ برابر بیشتر احتمال دارد که کاربر زمینه ناقص را شناسایی کند.
در خلق خروجیها، کاربران بیشتر هدایتگرتر هستند تا ارزیاب
۱۲.۳ درصد از مکالمات نمونه ما شامل Artifactهای Claude بود، از جمله کد، اسناد، ابزارهای تعاملی و دیگر خروجیها. در این مکالمات، نحوه همکاری کاربران با Claude تفاوت قابلتوجهی داشت.
به طور مشخص، نرخهای بهمراتب بالاتری از رفتارهایی در قالب «توصیف» و «تفویض» مشاهده شد. برای مثال، این مکالمات نسبت به مکالمات بدون خروجی، بیشتر شاهد این بودند که کاربران هدف خود را روشن کنند (۱۴.۷ درصد)، قالب را مشخص کنند (۱۴.۵درصد)، مثال ارائه دهند (۱۳.۴ درصد) و تکرار کنند (۹.۷ درصد). به بیان دیگر، از همان ابتدا بیشتر تلاش میکنند تا هوش مصنوعی را هدایت کنند.
اما این هدایتگری با سطح بالاتری از ارزیابی یا تشخیص همراه نیست. در واقع برعکس است؛ در مکالماتی که خروجی آن Artifact است، کاربران کمتر احتمال دارد زمینه ناقص را شناسایی کنند (۵.۲ درصد)، واقعیات را بررسی کنند (۳.۷ درصد)، یا استدلال مدل را با خواستن توضیح از آن زیر سؤال ببرند (۳.۱ درصد). شاخص اقتصادی Anthropic نیز نشان میدهد که پیچیدهترین وظایف جایی هستند که Claude بیشترین ضعف را دارد، ازاینرو این الگو به نظر میرسد که قابلتوجه باشد.
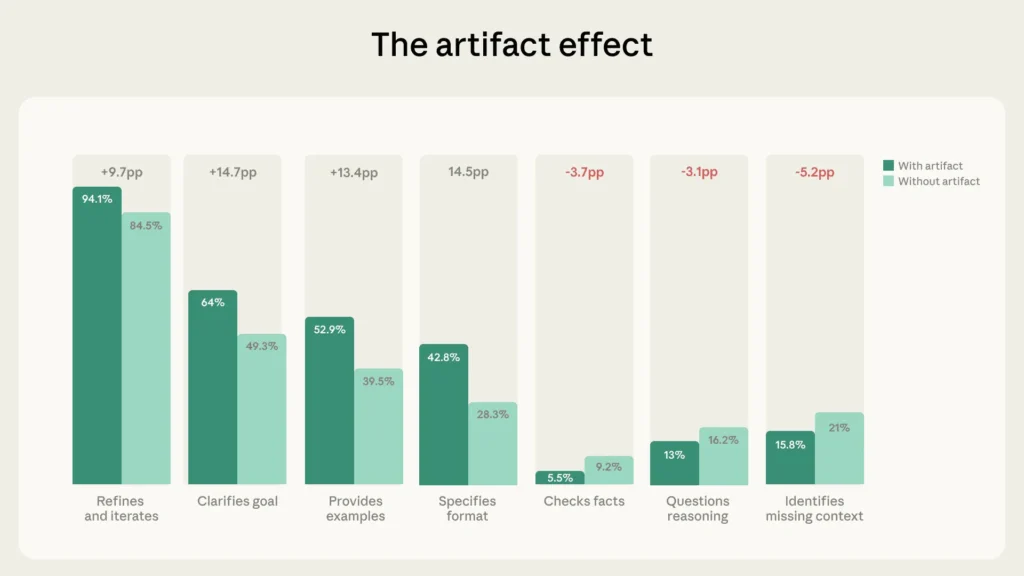
برای این الگو چند توضیح احتمالی وجود دارد. شاید Claude خروجیهایی با ظاهر کاربردی و شفافتری تولید میکند که در ذهن کاربر پرسشگری بیشتر را ضروری به نظر نمیرساند. اگر کار تمامشده به نظر برسد، کاربران هم شاید آن را همینطور در نظر بگیرند. اما ممکن است مکالمات با خروجی Artifact شامل وظایفی باشند که در آنها دقت واقعی کمتر از زیباییشناسی یا عملکرد اهمیت دارد (مانند طراحی یک رابط کاربری در مقایسه با نوشتن یک تحلیل حقوقی). شاید کاربران خروجیهای Artifact را بهجای اینکه ارزیابیشان را در همان مکالمه اولیه ابراز کنند، آن را از طریق کانالهایی که Anthropic نمیتواند مشاهده کند ارزیابی میکنند، مانند اجرای کد، آزمایش یک اپ در محیط دیگر، به اشتراک گذاشتن پیشنویس با یک همکار و…. .
هر توضیحی که باشد، این الگو ارزش توجه را دارد. با افزایش توانایی مدلهای هوش مصنوعی در تولید خروجیهای تمیز، توانایی ارزیابی انتقادی این خروجیها چه در مکالمه مستقیم، چه از طریق دیگر روشها ارزشمندتر خواهد شد، نه کمتر.
توسعه تسلط شخصی بر هوش مصنوعی
مانند همه مهارتها، تسلط بر هوش مصنوعی نیز یک مسئله اندازهگیری است. برای بیشتر افراد پیشرفت در تواناییها امکانپذیر است. بر اساس الگوهای موجود در دادهها، Anthropic سه حوزه را شناسایی کرده است که بسیاری از کاربران میتوانند مهارتهایشان در این حوزهها را ارتقا دهند:
- ماندن در مکالمه. تکرار و اصلاح قویترین همبستگی را با سایر رفتارهای تسلط در دادههای موردبررسی دارد. پس وقتی پاسخ اولیه را دریافت کردید، بهتر است آن را فقط یک نقطه شروع بدانید، سؤالات پیگیرانه بپرسید، بر بخشهایی که درست به نظر نمیرسند تأکید کنید و آنچه را که دنبالش هستید اصلاح کنید.
- زیرسؤالبردن خروجیهای شفاف. وقتی مدلهای هوش مصنوعی چیزی که خوب به نظر میرسد را تولید میکنند، دقیقاً همان لحظه است که باید مکث کرد و پرسید: آیا این خروجی دقیق است؟ آیا چیزی کم دارد؟ آیا این استدلال صحیح است؟ همانطور که پیشتر اشاره شد؛ دادهها نشان میدهند که خروجیهای شفاف با نرخهای پایینتر ارزیابی انتقادی همراه هستند حتی با اینکه کاربران در همان گامهای اول بیشتر تلاش کردهاند تا Claude را هدایت کنند.
- تعیین شرایط همکاری. تنها در ۳۰ درصد از مکالمات، کاربران به Claude میگویند که چگونه میخواهند با آنها تعامل داشته باشد. تلاش کنید صریح باشید و دستورالعملهایی مثل موارد زیر اضافه کنید: «اگر فرضهایم اشتباه بود، مخالفت کن»، «پیش از جواب، منطق استدلالت را شرح بده» یا «بگو در چه موضوعاتی مطمئن نیستی.» تعیین این انتظارات از ابتدا میتواند پویایی مکالمات بعدی را تغییر دهد.
محدودیتها
این پژوهش با محدودیتهای مهمی همراه است:
- محدودیتهای نمونه: نمونه ما کاربران Claude.ai هستند که در طول یک هفته در ژانویه ۲۰۲۶، مکالمات چند پرامپتی داشتند. ازآنجاکه فکر میکنیم هنوز در مراحل نسبتاً اولیه ارائه ابزارهای هوش مصنوعی هستیم، این کاربران احتمالاً به سمت پذیرندگان اولیهای متمایل میشوند که از قبل با هوش مصنوعی راحت هستند؛ یعنی ممکن است نماینده جمعیت گستردهتر نباشند. نمونه ما باید بهعنوان ارائه یک خط مبنا برای این جمعیت در نظر گرفته شود، نه یک معیار جهانی. ازآنجاکه دادهها صرفاً منحصر به یک هفته هستند، هیچ اثر زمانی را نمیتواند در بر بگیرد و چون بر Claude.ai متمرکز است، نحوه تعامل کاربران با سایر پلتفرمهای هوش مصنوعی را شامل نمیشود.
- پوشش ناقص چارچوب: در این مطالعه، تنها ۱۱ عدد از ۲۴ شاخص رفتاری را که به طور مستقیم در مکالمات Claude.ai قابلمشاهده هستند ارزیابی شد. تمام رفتارهای مرتبط با استفاده مسئولانه و اخلاقی از خروجیهای هوش مصنوعی خارج از این مکالمات رخ میدهند و ثبت نمیشوند.
- طبقهبندی دوگانه: برای هر مکالمه در نمونه موردبررسی، هر رفتار یا حاضر یا غایب طبقهبندی شده است؛ اما این امر احتمالاً سبب ازدسترفتن نکات ظریف مهمی مانند رفتارهایی که به طور جزئی یا قابلبحث نشان داده میشوند یا سیگنالهای همپوشانی میان آنها میشود.
- رفتارهای ضمنی: کاربران ممکن است رفتارهای تسلط را ذهن خود انجام دهند (مثل بررسی ادعاهای Claude در برابر دانش خودشان) بدون اینکه این رفتارها را در مکالمه بیان کنند. این موضوع به نظر میرسد برای دادههای ما درباره خروجیهای Artifact بیشتر صدق کند. کاربران ممکن است خروجیهای Claude را از طریق آزمایش و استفاده عملی ارزیابی کنند، نه از طریق رفتارهای قابلمشاهده در مکالمه.
- یافتههای همبستگی: روابط شناساییشده، مبتنی بر همبستگی هستند. مشخصی نیست که آیا یک رفتار سبب رفتاری دیگری میشود یا هر دو بازتاب یک عامل مشترک زمینهای مانند پیچیدگی وظیفه یا ترجیحات کاربر هستند.
آیندهنگری
این مطالعه یک خط مبنا در اختیار ما قرار میدهد که میتوانیم از آن برای ارزیابی تغییر تسلط بر هوش مصنوعی در طول زمان استفاده کنیم. با تکامل قابلیتهای هوش مصنوعی و افزایش پذیرش، هدف نهایی یادگیری این است که آیا کاربران رفتارهای پیچیدهتری از خود نشان میدهند، کدام مهارتها به طور طبیعی با تجربی به وجود میآیند میکنند و کدام تواناییها نیازمند توسعه آگاهانهتری خواهند بود. انتظار میروند ماهیت تسلط بر هوش مصنوعی در طول زمان به طور قابلتوجهی توسعه و تحول پیدا کند.





