TPUها در مقابل GPUها در هوش مصنوعی
 تیم تحریریه
تیم تحریریه- ۱۱ آذر ۱۴۰۳
رشد و پیشرفت هوش مصنوعی (AI) منجر به افزایش چشمگیر تقاضا برای قدرت پردازشی شده و نیاز به راهحلهای سختافزاری قدرتمند را بیشتر کرده است. در این راستا، واحدهای پردازش گرافیکی (Graphics Processing Unit) که به اختصار GPU گفته میشود و واحدهای پردازش تانسور (Tensor processing unit) که به اختصار TPU گفته میشود به عنوان فناوریهای کلیدی برای پاسخگویی به این نیازها شناخته شدهاند.
پردازش هوشمند
GPUها که در ابتدا برای انجام عملیات رندرینگ گرافیک طراحی شده بودند و به دلیل تواناییهای پردازش موازی خود به پردازندههای چندمنظورهای تبدیل شدهاند که میتوانند به طور مؤثر وظایف مرتبط با هوش مصنوعی را انجام دهند. از سوی دیگر، TPUها که توسط گوگل توسعه یافتهاند، به طور خاص برای محاسبات هوش مصنوعی بهینهسازی شدهاند و عملکرد بهتری در انجام کارهایی مانند پروژههای یادگیری ماشین ارائه میدهند.
در این مقاله، به بررسی مقایسهای بین GPUها و TPUها خواهیم پرداخت و این دو فناوری را بر اساس معیارهایی نظیر عملکرد، هزینه، اکوسیستم و سایر جنبهها تحلیل خواهیم کرد. همچنین، خلاصهای از کارایی انرژی، تأثیرات زیستمحیطی و قابلیت مقیاسپذیری آنها در برنامههای سازمانی را نیز ارائه خواهیم داد.

GPU چیست؟
GPUها پردازندههای تخصصی هستند که در ابتدا برای تولید تصاویر و گرافیک در کامپیوترها و کنسولهای بازی طراحی شدهاند. این پردازندهها با تقسیم مسائل پیچیده به چندین وظیفه و انجام همزمان آنها، به جای پردازش یکی پس از دیگری مانند CPUها، عملکرد بهتری ارائه میدهند.
به دلیل تواناییهای پردازش موازی، قابلیتهای آنها به طرز چشمگیری فراتر از پردازش گرافیک توسعهیافته و به بخشهای ضروری در برنامههای محاسباتی مختلف، از جمله توسعه مدلهای هوش مصنوعی، تبدیل شده است. اما بیایید کمی به عقب برگردیم. GPUها برای نخستین بار در دهه 1980 به عنوان سختافزار تخصصی برای تسریع در رندرینگ گرافیک معرفی شدند. شرکتهایی نظیر NVIDIA و ATI (که اکنون بخشی از AMD است) در این زمینه نقشهای کلیدی ایفا کردند. با این حال، این فناوری تا اواخر دهه 1990 و اوایل دهه 2000 به محبوبیت عمومی نرسید. پذیرش گسترده آنها به دلیل معرفی شیدرهای قابل برنامهریزی بود که به توسعهدهندگان این امکان را میداد تا از پردازش موازی برای انجام کارهایی فراتر از گرافیک استفاده کنند.
در دهه اول قرن ۲۱، تحقیقات بیشتری در زمینه کاربردهای محاسباتی عمومی فراتر از گرافیک بر روی GPUها انجام شد. فناوری CUDA (معماری دستگاه محاسباتی یکپارچه) از سوی NVIDIA و Stream SDK از سوی AMD به توسعهدهندگان این امکان را داد تا از توان پردازش GPU برای شبیهسازیهای علمی، تحلیل دادهها و سایر کاربردها استفاده کنند. حالا، زمان ظهور هوش مصنوعی و یادگیری عمیق فرا رسید.
به دلیل قابلیتهای خود در پردازش حجم بالای دادهها و انجام محاسبات به صورت همزمان، GPUها به ابزارهای حیاتی برای آموزش و پیادهسازی مدلهای یادگیری عمیق تبدیل شدهاند.
فریمورکهایی نظیر TensorFlow و PyTorch از شتابدهندههای GPU بهره میبرند و به این ترتیب، یادگیری عمیق را برای پژوهشگران و توسعهدهندگان در سرتاسر جهان در دسترس قرار میدهند.
TPU چیست؟
واحدهای پردازش تانسور (TPUها) نوعی مدار مجتمع با کاربرد خاص (ASIC) هستند که توسط گوگل طراحی شدهاند تا به نیازهای فزاینده محاسباتی در زمینه یادگیری ماشین پاسخ دهند.
برخلاف GPUها که در ابتدا برای پردازش گرافیک توسعهیافته و سپس برای پاسخ به نیازهای هوش مصنوعی بهینهسازی شدند، TPUها به طور ویژه برای تسریع در بارهای کاری یادگیری ماشین طراحی شدهاند.
TPUها به طور خاص برای انجام عملیات تانسور طراحی شدهاند و به همین دلیل برای الگوریتمهای یادگیری عمیق که از اهمیت بالایی برخوردارند، بهینهسازی شدهاند.
به دلیل طراحی خاص خود که برای انجام عملیات ضرب ماتریسی، یکی از مراحل اساسی درپ محاسبات شبکههای عصبی، بهینهسازی شده است، این سیستمها قادرند به طور مؤثر حجمهای بزرگ دادهها را پردازش کرده و شبکههای عصبی پیچیده را با سرعت بالا در زمانهای آموزش و استنتاج اجرا کنند.
این بهینهسازی ویژه TPUها را برای استفاده در زمینههای هوش مصنوعی ضروری میکند و به پیشرفت در تحقیقات و پیادهسازی یادگیری ماشین کمک مینماید.
TPU در مقابل GPU: مقایسه عملکرد
TPUها و GPUها هر کدام ویژگیهای خاصی دارند و برای انواع مختلفی از وظایف محاسباتی طراحی شدهاند. اگرچه هر دو قادر به تسریع بارهای کاری یادگیری ماشین هستند، اما ساختار و بهینهسازیهای آنها باعث ایجاد تفاوتهایی در عملکرد بر اساس وظیفه خاص میشود.

معماری محاسباتی
برای آغاز، هم GPUها و هم TPUها به عنوان شتابدهندههای سختافزاری تخصصی شناخته میشوند که به منظور بهبود عملکرد در وظایف هوش مصنوعی طراحی شدهاند. با این حال، آنها در معماریهای محاسباتی خود تفاوتهایی دارند که تأثیر قابلتوجهی بر کارایی و اثربخشی آنها در انجام انواع خاصی از محاسبات میگذارد.
GPUها
GPUها شامل هزاران هسته کوچک و بهینه هستند که برای پردازش موازی طراحی شدهاند. این نوع معماری به آنها این امکان را میدهد که چندین وظیفه را به صورت همزمان انجام دهند که این ویژگی آنها را در انجام کارهایی که قابلیت موازیسازی دارند، مانند رندرینگ گرافیک و یادگیری عمیق، بسیار کارآمد میسازد.
GPUها به طور خاص در انجام عملیات ماتریس که در محاسبات شبکههای عصبی متداول است، بسیار کارآمد هستند. قابلیت آنها در پردازش حجمهای وسیع داده و انجام محاسبات به صورت همزمان، آنها را برای وظایف هوش مصنوعی که نیاز به پردازش دادههای کلان و انجام محاسبات پیچیده ریاضی دارند، ایدهآل میسازد.
TPUها
TPUها به جای تمرکز بر روی پردازشهای عمومی، بر روی عملیات تانسور متمرکز هستند که این ویژگی به آنها امکان میدهد محاسبات را به شکل بهینهتری انجام دهند. هرچند TPUها ممکن است به اندازه GPUها هسته نداشته باشند، اما معماری تخصصی آنها به آنها این قابلیت را میدهد که در برخی از وظایف هوش مصنوعی، به ویژه آنهایی که به شدت به عملیات تانسور وابستهاند، از GPUها پیشی بگیرند.
با این حال، GPUها در کارهایی که از پردازش موازی بهرهمند میشوند و برای محاسبات مختلف فراتر از هوش مصنوعی، مانند رندرینگ گرافیک و شبیهسازیهای علمی، مناسب هستند، برتری دارند.
از طرف دیگر، TPUها به طور خاص برای پردازش تانسور بهینهسازی شدهاند و این ویژگی آنها را در انجام وظایف یادگیری عمیق که شامل عملیات ماتریسی هستند، بسیار کارآمد میسازد. بسته به نیازهای خاص بار کاری هوش مصنوعی، ممکن است GPUها یا TPUها عملکرد و کارایی بهتری را ارائه دهند.
عملکرد
سرعت و کارایی
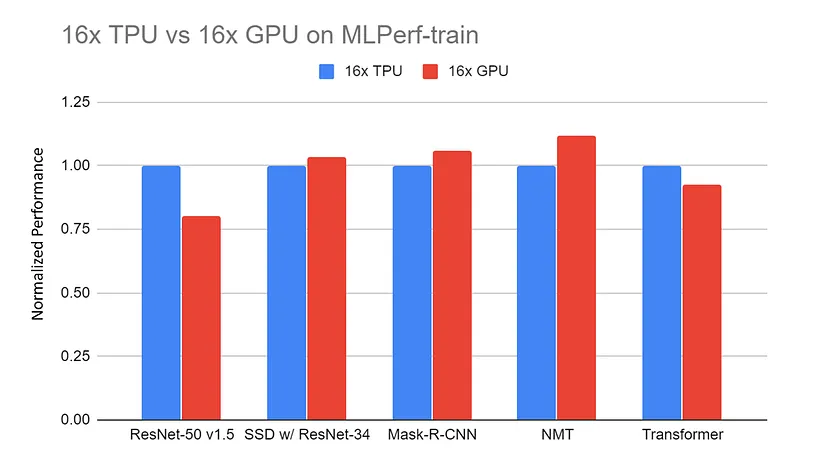
GPUها به خاطر قابلیتهای خود در مدیریت انواع مختلف وظایف هوش مصنوعی، از جمله آموزش مدلهای یادگیری عمیق و انجام عملیات استنتاج، شناخته شدهاند. این امر به دلیل معماری GPU است که بر پایه پردازش موازی بنا شده و سرعت آموزش و استنتاج را در مدلهای مختلف هوش مصنوعی به طور چشمگیری افزایش میدهد. به عنوان نمونه، پردازش یک دسته 128 تایی از دنبالهها با استفاده از یک مدل BERT بر روی یک GPU V100 به 3.8 میلیثانیه زمان نیاز دارد، در حالی که این زمان بر روی یک TPU v3 به 1.7 میلیثانیه کاهش مییابد.
بر خلاف این، TPUها به طور خاص برای انجام سریع و بهینه عملیات تانسور که اجزای کلیدی شبکههای عصبی هستند، طراحی شدهاند. این ویژگی به TPUها این امکان را میدهد که در برخی وظایف خاص یادگیری عمیق، به ویژه آنهایی که توسط گوگل بهینهسازی شدهاند، مانند آموزش شبکههای عصبی بزرگ و مدلهای پیچیده یادگیری ماشین، از GPUها پیشی بگیرند.
مقایسههای انجام شده بین TPUها و GPUها در وظایف مشابه معمولاً نشان میدهد که TPUها به دلیل طراحی خاص خود، قادر به ارائه دورههای آموزشی سریعتر و پردازش مؤثرتری هستند.
به عنوان نمونه، آموزش یک مدل ResNet-50 بر روی مجموعه داده CIFAR-10 به مدت 10 دوره با استفاده از یک GPU NVIDIA Tesla V100 تقریباً 40 دقیقه زمان میبرد که به طور میانگین 4 دقیقه برای هر دوره است. در مقایسه، با استفاده از یک Google Cloud TPU v3، همان فرآیند آموزشی تنها 15 دقیقه طول میکشد و به طور متوسط 1.5 دقیقه برای هر دوره زمان نیاز دارد.
با این حال، به دلیل انعطافپذیری و تلاشهای چشمگیر بهینهسازی که توسط جامعه انجام شده است، GPUها در مجموعهای گسترده از برنامهها همچنان عملکرد رقابتی خود را حفظ میکنند.
GPU در مقابل TPU: هزینه و دسترسی
انتخاب میان GPU و TPU به عوامل مختلفی از جمله بودجه، نیازهای محاسباتی و دسترسی بستگی دارد. هر یک از این گزینهها مزایای خاصی را برای کاربردهای متفاوت فراهم میآورند. در این بخش، به بررسی مقایسه هزینه و دسترسی بازار این دو فناوری خواهیم پرداخت.
هزینه سختافزار
GPUها از نظر هزینهها نسبت به TPUها بسیار انعطافپذیرتر هستند. به این معنا که TPUها به صورت مستقل قابل خریداری نیستند و تنها به عنوان یک سرویس ابری از طریق ارائهدهندگانی مانند Google Cloud Platform (GCP) ارائه میشوند. در حالی که GPUها امکان خرید جداگانه را دارند.
هزینه تقریبی یک واحد GPU NVIDIA Tesla V100 بین 8000 تا 10000 دلار و یک واحد GPU NVIDIA A100 بین 10000 تا 15000 دلار است. همچنین، شما میتوانید از گزینه قیمتگذاری ابری به صورت درخواستی نیز استفاده کنید.
استفاده از GPU NVIDIA Tesla V100 برای آموزش یک مدل یادگیری عمیق تقریباً هزینهای معادل 2.48 دلار در ساعت خواهد داشت، در حالی که NVIDIA A100 حدود 2.93 دلار در ساعت هزینه خواهد کرد. از سوی دیگر، هزینه استفاده از Google Cloud TPU V3 حدود 4.50 دلار در ساعت و Google Cloud TPU V4 حدود 8.00 دلار در ساعت خواهد بود.
به عبارت دیگر، TPUها از نظر انعطافپذیری نسبت به GPUها بسیار محدودتر هستند و معمولاً هزینههای ساعتی بالاتری برای محاسبات ابری درخواستی دارند. با این حال، TPUها معمولاً عملکرد سریعتری را ارائه میدهند که میتواند زمان کلی محاسبات موردنیاز برای وظایف یادگیری ماشین در مقیاس بزرگ را کاهش دهد و در نتیجه، با وجود نرخهای ساعتی بالاتر، منجر به صرفهجویی کلی در هزینهها شود.
دسترسی در بازار
دسترسپذیری TPUها و GPUها در بازار به طور قابلتوجهی متفاوت است و این موضوع بر میزانپذیرش آنها در صنایع و مناطق گوناگون تأثیر میگذارد.
TPUها که توسط گوگل طراحی و توسعه یافتهاند، عمدتاً از طریق پلتفرم ابری گوگل (GCP) برای انجام وظایف هوش مصنوعی در دسترس قرار دارند. این موضوع نشان میدهد که این پردازندهها بیشتر توسط کاربرانی که به GCP برای نیازهای محاسباتی خود وابستهاند، مورد استفاده قرار میگیرند. به همین دلیل، ممکن است در حوزهها و صنایعی که به محاسبات ابری وابستهاند، مانند مراکز فناوری یا مکانهایی با اتصال اینترنتی قوی، محبوبیت بیشتری پیدا کنند.
در همین راستا، شرکتهایی نظیر NVIDIA، AMD و Intel اقدام به تولید GPUها کردهاند که در انواع مختلف برای مصرفکنندگان و کسبوکارها در دسترس قرار دارند. این دسترسی گسترده، GPUها را به گزینهای محبوب در صنایع گوناگون از جمله بازی، علم، مالی، بهداشت و درمان و تولید تبدیل کرده است. GPUها قابلیت راهاندازی در محل یا در فضای ابری را دارند و به کاربران این امکان را میدهند که تنظیمات محاسباتی خود را به طور انعطافپذیر تنظیم کنند.
در نتیجه، GPUها به احتمال بیشتری در صنایع و حوزههای مختلف به کار گرفته میشوند، بدون توجه به زیرساختهای فناوری یا نیازهای محاسباتی آنها. به طور کلی، دسترسی به بازار TPUها و GPUها تأثیر زیادی بر میزانپذیرش آنها دارد. TPUها بیشتر در حوزهها و بخشهای متمرکز بر ابر، مانند یادگیری ماشین، رایج هستند، در حالی که GPUها به طور گستردهای در زمینهها و مکانهای متنوع مورد استفاده قرار میگیرند.

اکوسیستم و ابزارهای توسعه
نرمافزار و کتابخانهها
TPUهای گوگل به طور یکپارچه با TensorFlow که یک فریمورک منبعباز پیشرو در زمینه یادگیری ماشین است، کار میکنند. همچنین JAX که یک کتابخانه دیگر برای محاسبات عددی با کارایی بالا به شمار میرود، از TPUها پشتیبانی کرده و امکان انجام یادگیری ماشین و محاسبات علمی به صورت کارآمد را فراهم میآورد.
TPUها به طور کامل در اکوسیستم TensorFlow گنجانده شدهاند و این امر استفاده از قابلیتهای TPU را برای کاربران TensorFlow تسهیل میکند. به عنوان نمونه، TensorFlow ابزارهایی نظیر کامپایلر TensorFlow XLA (الگوریتم جبری خطی شتابدار) را فراهم میآورد که محاسبات را برای TPUها بهینه میسازد.
TPUها به طور خاص برای افزایش سرعت عملیات TensorFlow طراحی شدهاند و عملکرد بهینهای را در زمینه آموزش و استنتاج ارائه میدهند. همچنین، این واحدها از APIهای سطح بالای TensorFlow پشتیبانی میکنند که انتقال و بهینهسازی مدلها برای اجرا بر روی TPU را تسهیل میکند.
در عوض، GPUها به طور گستردهای در صنایع و حوزههای تحقیقاتی مختلف مورد استفاده قرار گرفتهاند و این امر آنها را برای کاربردهای متنوع یادگیری ماشین محبوب میسازد. به عبارت دیگر، آنها نسبت به CPUها قابلیتهای بیشتری دارند و توسط مجموعه وسیعی از فریمورکهای یادگیری عمیق مانند TensorFlow، PyTorch، Keras، MXNet و Caffe پشتیبانی میشوند.
GPUها همچنین از مجموعهای وسیع از کتابخانهها و ابزارها مانند CUDA، cuDNN و RAPIDS استفاده میکنند که به افزایش انعطافپذیری و سهولت ادغام آنها در فرآیندهای مختلف یادگیری ماشین و علم داده کمک میکند.
پشتیبانی و منابع جامعه
در مورد پشتیبانی جامعه، GPUها دارای اکوسیستم گستردهتری با انجمنها، آموزشها و مستندات گسترده در دسترس از منابع مختلف مانند NVIDIA، AMD و پلتفرمهای مبتنی بر جامعه هستند. توسعهدهندگان میتوانند به جوامع آنلاین پر جنبوجوش، انجمنها و گروههای کاربری دسترسی داشته باشند تا کمک بخواهند، دانش خود را به اشتراک بگذارند و در پروژهها همکاری کنند. علاوه بر این، منابع آموزشی، دورهها و مستندات بیشماری، برنامهنویسی GPU، فریمورکهای یادگیری عمیق و تکنیکهای بهینهسازی را پوشش میدهند.
کارایی انرژی و تأثیر زیستمحیطی
مصرف انرژی
کارایی انرژی GPUها و TPUها بسته به معماری و کاربردهای خاص آنها متفاوت است. به طور کلی، TPUها، به ویژه Google Cloud TPU v3، به طور قابلتوجهی در مصرف انرژی نسبت به GPUهای پیشرفته NVIDIA کارآمدتر هستند و از این نظر برتری دارند.
کاهش مصرف انرژی TPUها میتواند به کاهش قابلتوجه هزینههای عملیاتی و بهبود کارایی انرژی، به ویژه در پیادهسازیهای یادگیری ماشین در مقیاس وسیع، کمک نماید.
بهینهسازی برای وظایف هوش مصنوعی
TPUها و GPUها از بهینهسازیهای ویژهای بهره میبرند تا کارایی انرژی را در حین اجرای عملیات هوش مصنوعی در مقیاس وسیع افزایش دهند.
همانطور که در ابتدای مقاله اشاره شد، معماری TPU به گونهای طراحی شده است که به عملیات تانسور متداول در شبکههای عصبی اولویت میدهد و این امر امکان اجرای مؤثر وظایف هوش مصنوعی را با حداقل مصرف انرژی فراهم میآورد. همچنین TPUها دارای یک سلسله مراتب حافظه سفارشی هستند که به طور خاص برای محاسبات هوش مصنوعی بهینهسازی شده و باعث کاهش تأخیر در دسترسی به حافظه و نویز انرژی میشوند.
آنها از روشهایی نظیر کوانتیزاسیون و اسپارس بودن برای بهینهسازی عملیات محاسباتی بهره میبرند که به کاهش مصرف انرژی کمک میکند بدون اینکه دقت را تحت تأثیر قرار دهد. این ویژگیها به TPUها این امکان را میدهند که عملکرد بالایی را در کنار صرفهجویی در انرژی ارائه دهند.
به طور مشابه، واحدهای پردازش گرافیکی (GPU) به منظور بهبود عملکرد در عملیات هوش مصنوعی، بهینهسازیهای مؤثری در مصرف انرژی انجام میدهند. معماریهای جدید GPU شامل ویژگیهایی مانند خاموش کردن توان و مقیاسبندی دینامیک ولتاژ و فرکانس (DVFS) هستند که به تنظیم مصرف انرژی بر اساس نیاز بار کاری کمک میکند. همچنین، این واحدها از تکنیکهای پردازش موازی بهره میبرند تا وظایف محاسباتی را در هستههای متعدد توزیع کرده و در عین حال حداکثر توان عملیاتی را با حداقل کردن مصرف انرژی در هر عملیات، افزایش دهند.
تولیدکنندگان GPU به منظور بهینهسازی الگوهای دسترسی به حافظه و کاهش مصرف انرژی در حین انتقال دادهها، معماریهای حافظهای با کارایی انرژی و سلسله مراتب کش را توسعه میدهند. این بهینهسازیها، به همراه تکنیکهای نرمافزاری نظیر ادغام هسته و باز کردن حلقه، موجب افزایش بیشتر کارایی انرژی در بارهای کاری هوش مصنوعی شتابداده شده توسط GPU میشوند.
مقیاسپذیری در برنامههای سازمانی
مقیاسبندی پروژههای هوش مصنوعی
TPUها و GPUها هر دو قابلیت مقیاسپذیری را برای پروژههای بزرگ هوش مصنوعی فراهم میکنند، اما به شیوههای متفاوتی به این هدف میرسند. TPUها به طور یکپارچه با زیرساخت ابری، به ویژه از طریق Google Cloud Platform (GCP)، ادغام شدهاند و منابع مقیاسپذیری را برای بارهای کاری هوش مصنوعی ارائه میدهند. کاربران میتوانند به TPUها به صورت درخواستی دسترسی پیدا کنند و بر اساس نیازهای محاسباتی خود، منابع را افزایش یا کاهش دهند که این امر برای مدیریت پروژههای بزرگ هوش مصنوعی به طور مؤثر بسیار حائز اهمیت است. گوگل همچنین خدمات مدیریت شده و محیطهای پیش تنظیم شدهای برای استقرار مدلهای هوش مصنوعی بر روی TPUها ارائه میدهد که فرآیند ادغام با زیرساخت ابری را تسهیل میکند.
از طرف دیگر، GPUها به طور مؤثر برای پروژههای بزرگ هوش مصنوعی مقیاسپذیر هستند و گزینههایی برای استقرار در محل یا استفاده در محیطهای ابری از سوی ارائهدهندگانی مانند Amazon Web Services (AWS) و Microsoft Azure فراهم میکنند. این GPUها انعطافپذیری لازم برای مقیاسبندی را ارائه میدهند و به کاربران این امکان را میدهند که چندین GPU را به صورت موازی برای افزایش قدرت محاسباتی به کار ببرند.
علاوهبراین، GPUها به خاطر پهنای باند بالای حافظه و تواناییهای پردازش موازی خود، در مدیریت دادههای کلان برتری دارند. این ویژگیها امکان پردازش مؤثر دادهها و آموزش مدلها را فراهم میآورند که برای پروژههای بزرگ هوش مصنوعی که با مجموعههای داده وسیع سر و کار دارند، حیاتی است.
به طور کلی، هم TPUها و هم GPUها قابلیت مقیاسپذیری را برای پروژههای بزرگ هوش مصنوعی فراهم میکنند. TPUها به طور یکپارچه در زیرساختهای ابری عمل میکنند، در حالی که GPUها انعطافپذیری لازم برای استقرار در محل یا به صورت ابری را ارائه میدهند. توانایی آنها در مدیریت دادههای کلان و مقیاسبندی منابع محاسباتی، آنها را برای انجام وظایف پیچیده هوش مصنوعی در مقیاسهای بزرگ مناسب میسازد.
توصیهها
GPUها را در شرایط زیر انتخاب کنید:
پروژه شما به پشتیبانی جامع از فریمورکهایی فراتر از TensorFlow، نظیر PyTorch، MXNet یا Keras نیازمند است.
شما به انواع قابلیتهای محاسباتی از جمله یادگیری ماشین، محاسبات علمی و رندرینگ گرافیکی نیاز دارید.
شما به گزینههای بهینهسازی قابلتنظیم و کنترل دقیق بر روی تنظیمات عملکرد اهمیت میدهید.
انعطافپذیری در استقرار در محیطهای محلی، مراکز داده و فضای ابری از اهمیت بالایی برخوردار است.
TPUها را در شرایط زیر انتخاب کنید:
پروژه شما عمدتاً بر پایه TensorFlow است و از همافزایی نزدیک با عملکرد بهینهسازی شده این پلتفرم بهره میبرد.
• آموزش با ظرفیت بالا و زمانهای استنتاج سریع، به ویژه در زمینه آموزش مدلهای یادگیری عمیق در مقیاس وسیع یا برنامههای زمان واقعی، از اهمیت بالایی برخوردار است.
• کارایی انرژی و کاهش مصرف آن، به ویژه در استقرارهای بزرگ، از جمله نکات کلیدی به شمار میروند.
• شما یک سرویس ابری مدیریتشده را با قابلیت مقیاسپذیری یکپارچه و دسترسی آسان به منابع TPU در Google Cloud ترجیح میدهید.